Lecture 2: Types and Memory
Contents
Simple Data Types
Computers are complex machines in which information is passed around and processed to perform complex calculations. The type of information that is processed can vary. Usually, modern computers are best suited to deal with integer numbers with a size of 64 bits.
However, that's not the only kind of data a computer can work with. For example, the actual size of the integers can vary. For a number from 8 till 128 bits. And whether the number can have a decimal point, or a sign (positive or negative) can change too.
In a programming language, the programmer is responsible for making choices about what kind of data should be passed around to accomplish the task at hand. In Rust, every value has a data type. By knowing these types, the Rust compiler can generate the right instructions to work with values of that type.
The Rust Book has a very nice section about primitive data types if you want to know more.
Storage Locations
During the execution of your program, values are constantly moved around and modified. But where are the values stored on your computer?
Generally, a computer has a limited number of very fast storage locations, which are called registers. Registers are located inside the processor right next to the place where calculations happen. However, since there are usually only very few registers, values are frequently moved to and from memory.
The memory of a program is usually split into two parts: The stack and the heap.
The stack is a place where "local variables" are stored; variables associated with the function that is currently executing.
Every time a function is called, a new section is added to the stack (such a section is called a stack frame).
Then, when a function returns, the frame is removed again.
One of the reasons stack frames are used, is because they allow functions to be recursive. In other words, functions can call themselves like the function below.
fn factorial(n: u64) -> u64 { if n <= 1 { 1 } else { n * factorial(n - 1) } } fn main() { factorial(10); }Every time a function is called, a new stack frame is created containing the local variables of that function. In the example, that means that a new stack frame is created for every call to
factorial: one in which n=10, then another one with n=9, n=8, etc. Every call to the function gets a new 'version' ofn.
A stack in memory is very similar to a stack of cards. You can easily add more cards to the top of the stack, and then later remove them again starting at the top and working your way down. However, removing parts from the middle is a lot harder. Luckily, when calling functions this is not really an operation we have to perform. When we call a new function we add a frame to the top and when we return we can remove the topmost frame. If you want to know more about the stack, this Wikipedia article explains it well.
Alternatively, values can be stored on the heap. The heap is much more flexible. At any moment, the program can request a certain number of bytes it wants to use on the heap. Then, some time later, it can signal that the bytes aren't used anymore and can be reused for something else.
Usually, an 'allocator' is responsible for managing the heap. It will find an unused spot and mark it as used until the program is done with that bit of memory. Allocating space on the heap takes some time, an allocator needs to actually find an unused bit of memory which is of the right size. This means creating values on the heap is slower than creating values on the stack.
Note that using values on the heap is not necessarily slower than using values on the stack! They're both simply places in memory, and loading a value from the heap into a register takes a similar amount of time as a value from the stack (if we ignore cache...).
So why is a heap necessary? In a program, you want to avoid copying large pieces of data around all the time. That can become very slow. Instead of copying values around, you can instead reserve a bit of space for it and remember its location. Using that location you can look up the value from anywhere it is needed.
But when your value is located on the stack, you cannot keep referring to values lower down on the stack. When you return from a function, the current stack frame is deleted (as we discussed earlier). If you were remembering a location of some data located in that stack frame, that location becomes invalid after the stack frame is removed. In that situation it'd be nice if we can store things in a separate place in memory that stays valid even after the stack frame is gone. And that, is the heap!
The Rust book also has a good explanation about the differences between the stack and the heap.
Box
To put a value on the heap, you need to allocate a region to put it in.
Rust calls such an allocation a Box.
A Box is actually just a number, which refers to some location in memory, that is to say a pointer.
That means that, if you create a Box with a very large value inside, passing around the Box is very cheap since it's just a pointer.
So if you want to make a variable on the stack with a very large integer in it, you would write:
fn main() { let a: u128 = 3; }
But if you want to put value on the heap, you would write:
fn main() { let a = Box::new(3u128); }
This makes a new allocation on the heap, with the size to hold an 128-bit integer and puts the number 3 there.
It also makes a variable on the stack, called a.
Instead of holding the number 3 (and all 16 bytes of it), this variable holds the location in memory, which is only 8 bytes large.
Of course, the difference between 8 and 16 bytes isn't a lot but for larger and complexer types this can make quite a difference!
In most cases you can use the Box in the same places where you would normally use a number, except that you sometimes may need to dereference the box:
fn main() { let a = Box::new(3); // the star means to use what's *in* the box (the value on the heap) // instead of the box itself for the calculation println!("{}", *a + 3) }
Scope
In the example above, at the end of main the box is "dropped".
That means that the stack frame of main is removed with all its local variables (like a).
However, the Box also makes sure that the space reserved on the heap to hold the large data is automatically marked as available; this is called deallocation.
Dropping happens at the end of the scope of a variable.
When a variable goes "out of scope" (which is at the end of a function or, as we will see shortly, a block), the value is "dropped" meaning the space used for it is cleaned up.
Scopes are always indicated by curly brackets ({ and }).
You can make scopes in your program wherever you like:
#![allow(unused)] fn main() { fn test() { // the braces indicate the function's scope let a = 3 ; // lives to the end of the function { // we make a new scope with brackets let b = 4; // b lives until the end of the scope } // b is gone here, we can't use it anymore since the scope ended for i in 0..5 { // we start a scope again // i is part of the loop's scope, and x is too let x = 5; println!("{}", x + i); } // so here we can't use i and x anymore // we can still use a, the scope hasn't ended println!("{}", a); } }
Compound Data Types
In a program it is often useful to group values together. Instead of storing just one number, it's often useful to store several together. There are multiple ways to manage this in Rust which we will discuss here.
Arrays
An array is a structure which holds a fixed number of elements of a specific type. For example, 5 integers, or 10 characters:
fn main() { let digits = [0, 1, 2, 3, 4, 5, 6, 7]; }
The type of the value in digits is now: [i32; 8]. Note that this type description consists
of two parts: i32 (so it's an array of signed 32-bit integers) and 8 (there are 8 of them).
The type [i32; 8] therefore takes up the space of 8 i32s, or 8 * 4 = 32 bytes.
Because the value is stored in a local variable, those 32 bytes are allocated on the
stack.
(See! Now Box::new([0u8; 2048]) might actually make sense if we pass it around a lot: Instead of having 2048 bytes on the stack, we can have only 8 on the stack and 2048 on the heap)
To access an element of an array, you can use the index operator:
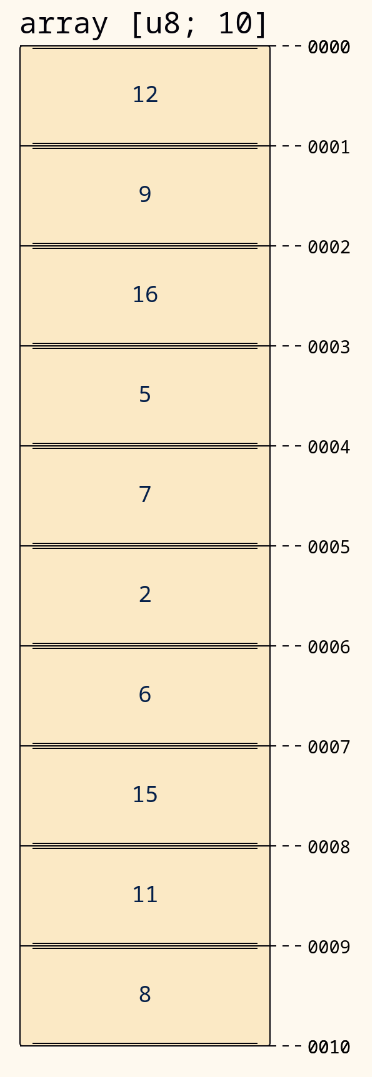
fn main() { let mut nums = [12, 9, 16, 5, 7, 2, 6, 15, 11, 8]; // get the 5th element of the array. // Note that we start counting locations in an array at 0, // so this prints the number 2, not 7! println!("{}", nums[5]); }
An array is just many variables
An array is simply a way to automate the creation of multiple variables of the same type at once. The above example of the array with 8 numbers is equivalent to the following:
fn main() { let digits_0 = 0; let digits_1 = 1; let digits_2 = 2; let digits_3 = 3; let digits_4 = 4; let digits_5 = 5; let digits_6 = 6; let digits_7 = 7; }
Sure, the semantics are a bit different (now there are 8 different variables with different names), but in memory, this looks identical.
Why do all elements of arrays need to be the same type?
Because the elements are the same type, they are also the same size. This is a very useful property. For example, if we want to know where the 8th element of an array is stored, we can just calculate that!
Given that we know where the first element is stored, we just move over 8 times the size of an element. So if the size of one element is 4 bytes, the 8th element is stored 28 bytes from the start. That property makes finding elements in an array very fast.
For example, in the following example each element has a size of 1 byte. The array starts at 0000, so the 8th element
is at position 0007
Resizing
Arrays do have a limitation. Let's look at the following example:
#![allow(unused)] fn main() { /// create an array with the `value` repeated `length` times. fn create_array(length: usize, value: u32) -> [u32; todo!()] { todo!() } }
How would we make this function? If we want to make an array, the compiler needs to know how much space to reserve for it on the stack. However, the compiler doesn't know this size! The length is just a variable, it can be any number. Maybe the program first asks a user to type in a number at runtime, which the compiler of course has no knowledge of.
This is a limitation of an array: The compiler needs to know its size, and this size can't ever change during the execution of the program. We can solve this by using a vector.
Vector (Vec)
A vector is a kind of array which can grow and shrink on-demand during the execution of the program. How does that work? Well, the elements aren't stored on the stack. Growing things on the stack is very hard, because you can only really allocate on the top. Not in the middle of the stack.
Instead, Vec stores elements on the heap just like Box.
Effectively a Vec is a just very large Box that holds not one, but many elements.
You can make a vector like this:
fn main() { let mut a = vec![1, 2, 3, 4, 5, 6]; }
That's very similar to an array. But we can now do something we couldn't do with arrays:
fn main() { let mut a = vec![1, 2, 3, 4, 5, 6]; a.push(7); println!("{:?}", a); }
We can add the 7 to it!
That means we can also implement the example from Resizing
#![allow(unused)] fn main() { fn create_array(length: usize, value: u32) -> Vec<u32> { let mut result = vec![]; for _ in 0..length { result.push(value); } return result; } }
For all the ways to interact with vectors (grow them, shrink them, etc), we recommend you to look at the documentation.
Implementation details
But, how does a vector work?
A vector is actually a struct.
We will look into these later this lecture.
Maybe it helps to continue reading first and then come back, so you understand this section better.
The vector struct contains 3 parts. A length, a capacity, and a Box with an array of elements. Yes, a normal array as we discussed before.
But, because the array sits in a box, it means the elements are located on the heap.
#![allow(unused)] fn main() { // the <T> part means that this struct is generic over a type. You can // see the name `T` used later. This simply means that the data is an // array of a type T, but the user of Vec may decide what that type is. // That means that a vec can contain any type of element, like a Vec // of numbers or a Vec of strings. pub struct Vec<T> { length: usize, capacity: usize, data: Box<[T]> } }
So what's the difference between the capacity and the length? The terms sound pretty similar. The trick behind a vector is that the array with data is actually always too large.
For example, at first the size of data may be 8, even if there's only a single element in the Vec.
This means you can add more things to the Vec before it is full.
The capacity is how many elements could possibly be stored, while the length is how many elements there are actually stored in the vector.
So at some point, if you add enough elements to the Vec, the length will become equal to the capacity.
What if we want to add more elements?
The most common strategy (also used in the built-in Vec) is to double the capacity when this happens.
So if the capacity started at 8, we double it to 16 and then 32, etc.
Each time we increase the capacity, we make a new allocation of the appropriate size, and copy all the data from the old to the new location on the heap.
If everything is copied, the old allocation can be removed, and all the data is safely stored in the new place with some capacity left-over.
This resizing can be very costly. The larger the array is, the more data needs to be copied. That's why the size is doubled every time. That ensures that the resizing will need to happen less and less often, compensating for the longer and longer duration it will take every time.
With this strategy, resizing actually doesn't take any time at all, on average. You resize more and more data but less and less often. This is called amortization.
Note that you can manually set the capacity of a vector. This may be desirable if you can cheaply calculate the final capacity of the vec in advance, to avoid multiple automatic resizes.
Tuple
So what if you do want to store multiple things of different types (and thus sizes)? In that case, to keep things fast, it would be very convenient if we knew all the sizes (and types) of the elements during compilation so the compiler can work out where to put things in memory.
Such a structure is called a "tuple". An example:
fn main() { // Saying the type like this is optional, as always, but // it's to show you what the type of a tuple looks like let a: (u8, u32, &str) = (3, 4, "test"); }
Here, we make a tuple of 3 elements. The size (in bytes) of this tuple, is 13 (1 + 4 + 8) bytes. The compiler can deduce this from the type of the elements, and thus can know where to store the elements in memory. This does mean that the size of a tuple always has to be fixed and known to the compiler.
Just like with arrays, a tuple is not so different from creating multiple variables. In memory the above example is looks a lot like:
#![allow(unused)] fn main() { let a_first = 3; let a_second = 4; let a_third = "test"; }However, the grouping a tuple provides can be more convenient to use.
Getting an element out of a tuple, works a bit different from arrays:
fn main() { let a = (3, 4, "test"); println!("{}", a.0); println!("{}", a.1); println!("{}", a.2); }
You simply use a dot, with a number.
The reason for that is that if you try to write an invalid index, like a.3, the compiler will simply not allow it.
Since the size of a tuple is always finite, the compiler knows the size and therefore also knows which indices (0, 1 and 2) are valid, and that 3 is not valid.
A tuple is a way to group multiple things of multiple types together in one variable. For that reason, a common application for them is returning more than one thing from a function.
For example:
// a function that calculates both the smallest and largest element in a vector: // notice we use a tuple (of two "u8"s) as a return type fn min_max(l: Vec<u8>) -> (u8, u8) { let mut min = u8::MAX; let mut max = u8::MIN; for i in l { if i < min { min = i; } if i > max { max = i; } } // make a tuple of both the smallest and the largest value (min, max) } fn main() { let a = min_max(vec![1, 2, 3, 4, 5, 6]); assert_eq!(a.0, 1); assert_eq!(a.1, 6); // we could also have written this: let (smallest, largest) = min_max(vec![1, 2, 3, 4, 5, 6]); // it makes two variables by "unpacking" the tuple assert_eq!(smallest, 1); assert_eq!(largest, 6); // maybe we only want the largest? let (_, largest) = min_max(vec![1, 2, 3, 4, 5, 6]); assert_eq!(largest, 6); }
The unpacking or destructuring of tuples and other types was discussed in lecture 2
The unit type
Sometimes, you want to say that a function returns "nothing". For example:
fn print_hello_world() { println!("Hello, World!"); } fn main() { print_hello_world(); print_hello_world(); print_hello_world(); }In our code, we just didn't put a
-> somethingafter the function. But actually, this:#![allow(unused)] fn main() { fn print_hello_world() -> () { println!("Hello, World!"); } }Is exactly equivalent. That's what rust actually inserts when you don't give a return type.
So what does
()mean? We call it the "unit type". That's because the unit type has only one value:(). We could thus write:fn main() { let a: () = (); }If we don't return anything from a function,
()is automatically returned (that's just the default).Notice however, that
()looks awfully similar to the syntax for a tuple. In fact, it's simply a "zero element tuple". A tuple with no values in it. And since there are no values in it, it has zero size and passing it around is essentially free.
Struct
Once you start combining more and more values in a single variable with tuples, keeping track of which value is at which index can become a pain.
At some point it can start making sense to use a struct.
A struct is a lot like a tuple, but we can give each element a name.
Additionally, we can give the entire struct a name, which we can use to refer to the entire grouping of the elements in the rest of the program.
Below is the same example as we gave with tuples.
But notice, we now created a struct MinMax.
We tell rust that the MinMax struct has two fields: smallest and largest. In the min_max function, we only have to say that
the return type is MinMax, and the compiler knows that it has the two fields.
struct MinMax { smallest: u8, largest: u8, } fn min_max(l: Vec<u8>) -> MinMax { let mut min = u8::MAX; let mut max = u8::MIN; for i in l { if i < min { min = i; } if i > max { max = i; } } MinMax { smallest: min, largest: max, } } fn main() { let a = min_max(vec![1, 2, 3, 4, 5, 6]); assert_eq!(a.smallest, 1); assert_eq!(a.largest, 6); }
In the main function, we can refer to a.smallest and a.largest directly. For such a small example, the names may not be absolutely necessary, but naming things makes code more readable and easier to work with.
At this point, I want to remind you that previously we told you to continue reading until after structs.
See if you understand the explanation about Vecs better now?
As you may have seen in the part about Vecs, a Vec is simply a struct.
Many other items in the standard library of Rust are structs.
Structs are so versatile because apart from holding data (with some names), they can also define methods: things you can do with structs.
For example, a Range struct holding something which has a start and an end:
#![allow(unused)] fn main() { struct Range { start: i64, end: i64 } }
to this struct we can now add "methods":
#![allow(unused)] fn main() { // add some methods to `Range` impl Range { /// This so-called 'static' method creates a new range pub fn new(start: usize, end: usize) -> Self { Range { start, end, } } /// This static method allows you to easily create a range /// that starts at zero. You only need to give an end. pub fn from_zero(end: usize) -> Self { Self::new(0, end); } /// This method is a method that's not static. /// That means that when we have previously created a value `r` of type `Range` /// we can call `r.invert()` on it and get two new ranges which /// describe everything below and above this `r` pub fn invert(&self) -> (Self, Self) { ( Self::new(i64::MIN, self.start), Self::new(self.end, i64::MAX), ) } } }
The type "Self" here, refers to the Range type since that's what we're adding methods to right now.
We can create new ranges like this now:
fn main() { let r1 = Range::new(1, 5); // 1 to 5 let r2 = Range::from_zero(5); // 0 to 5 }
And if we have made a range, we can invert it:
fn main() { let r = Range::from_zero(5); let (below, above) = r.invert(); println!("{} {}", below.start, below.end); println!("{} {}", above.start, above.end); }
Notice that there's a difference between the "invert" method and the "new" function.
The first parameter to invert is &self.
That means that when we say r.invert(), r becomes self. So r.invert() is the same as Range::invert(r).
Most of the functions on Vec you will get familiar with are methods.
You can even find a reference of all these methods on a Vec and every other struct.
Methods may still not be clear after this explanation. They are admittedly a pretty abstract concept, especially if you've never programmed before! Therefore, we encourage you to:
- Make the assignments on weblab associated with week 1.
- Read in The rust book about them.
Summary
- Values have types
- Different types have different sizes
- Values can be stored in different places in memory
- Stack
- Heap
- You can put multiple values of the same type together in an array
- You can use a
Vecto make an array that is resizeable at runtime - You can use a tuple to store a finite number of values of different types
- You can use a struct to name the type and values of a tuple
- Structs can have associated
methods, which represent things you can do with a struct and its contents
- Structs can have associated