Software Fundamentals
This is the homepage for the software fundamentals course. You can find all course information here.
This course is part of the CESE masters programme. This course's curriculum will be continued by the course Software Systems and the Embedded Systems Lab.
It is possible to use the course material in your own time. For example, if you are already following hardware fundamentals, but would still like to learn Rust. In that case, we recommend you enroll in weblab. The assignments are freely available and should guide you though the basics of Rust. The lectures are also available in writing on the lecture notes page
Deadlines
| Part | Graded | deadline always at 23.59 |
|---|---|---|
| Assignments on Git | PASS/FAIL | sunday, week 1 (7 sept) |
| Individual assignment | ✅ | sunday, week 4 (28 sept) |
| NES Project | ✅ | wednesday, week 10 (5 nov) |
This course consists of two parts over 9 weeks. You can find a detailed overview of what we will cover each week here
In the first part, the first 4 weeks, you will be working mostly on your own. There will be two lab sessions a week, 4 hours each, in which you can ask the TAs and your peers questions. On WebLab, there are practice assignments
In most lab sessions, we will spend 1 of these 4 hours (split into 2 smaller groups) discussing assignments together, looking at real-world examples of code. The assignments we will discuss could be based on your requests! Talk to the TAs if you have ideas.
In the first week, there will be a mandatory pass/fail assignment (meaning you can't continue the course if you don't do this) to demonstrate that you know Git. If you participate in first Lab, on Tuesday the 2nd of September, you automatically pass this. In the other three weeks, you will be working on an individual assignment in which you show your programming skills. The WebLab assignments can help you with this, and we strongly recommend you do them.
In the second half of the course there is a project. The project description is already published. You can only take part in this project if you have received a minimum grade of a 5 for the individual assignment, and when you have passed the Git assignment.
Note that you need a minimum grade of a 5.0 for the individual assignment to take part in the project and to pass the course.
The project will have a deadline in the halfway during week 10, and at the end of week 9 we will ask you to fill in a buddycheck questionnaire evaluating your team's performance in the project. These are mandatory.
During the project you are expected to work together with your group during the labs. Once a week, during the labs you will have a meeting with a TA assigned to your group to discuss your progress.
Minimum grades
The individual assignment decides your grade for part 1 of the course. The grade for needs to be at least a 5.0 to take part in the second half of the course (project).
Note however there is also a Git assignment, this assignment is mandatory to start the group project, even though you won't get a grade between 0 and 10 for it. It is simply pass or fail. During the group project, you will collaborate using git, and it's expected that you all know the basics by then.
Note that you need a minimum grade of a 5.0 for the project and individual assignment to pass this course.
Fraud and ChatGPT
Fraud (as well as aiding to fraud) is a serious offense and will always lead to (1) being expelled from the course and (2) being reported to the EEMCS Examination Board.
Fraud is taken to mean any act or omission by a student that makes it fully or partially impossible to properly assess the knowledge, insight and skill of that student or another student.
As part of an active anti-fraud policy, all code must be submitted, and will be subject to extensive cross-referencing in order to hunt down fraud cases. It is NOT allowed to reuse ANY computer code or report text from anyone else, including ChatGPT, Github Co-Pilot or similar, nor to make code or text available to any other student attending CESE4000 (aiding to fraud). An obvious exception is the code that was given to you by the course.
an excuse that one “didn’t fully understand the rules and regulations on student fraud and plagiarism at the Delft Faculty of EEMCS” is NOT acceptable. In case of doubt one is advised to first send a query to the course instructor before acting.
If you're in doubt, read the TU's guidelines on AI Tools, and make sure that we can properly assess your knowledge and insight.
Lecture notes
Each lecture will have an associated document with an explanation of what is discussed in the slides. This document will be published under lecture notes. We call these the lecture notes. You can use these to study ahead (before the lecture) which we recommend, so you can ask more specific questions in the lectures. And we do invite you to ask lots of questions! but in the case you could not make it to a lecture, it should also give you a lot of the information covered in the lectures in writing.
We encourage you to use the arrows at the sides of the webpage, to read through the pages of the website in-order, also following the lecture notes in that order. A summary/index of the lecture notes can be found here.
if you are learning rust but are not following the course for credits which some of you are, you can use the lecture notes to help you make the assignments.
All lecture slides are also published here.
For further learning, we recommend these additional resources:
- The Rust Programming Language by Steve Klabnik; Carol Nichols; The Rust Community,
- Rust for Rustaceans by Jon Gjengset
- Rustlings -- a collection of simple exercises designed to get you comfortable with Rust syntax and style.
If you notice any mistakes in this website, feel free to contact anyone on the course team. You can find our contact details on the staff page
Staff
The lectures of this course will be given by Andreea Costea. During the labs you will also interact with the TA team
- Charlie Ciaś
- Eric Jerman
- Glenn Weeland (Head TA)
- Max Guichard
- Utkarsh Verma
Contact
If you need to contact us, please use the course email address: softw-fund-ewi@tudelft.nl.
Alternatively, if you REALLY need to speak to one of us directly, you can contact Glenn at g.s.m.weeland@student.tudelft.nl.
Note that we prefer that you use the course email address and we might elect to ignore e-mails sent to personal email addresses if used improperly.
Software Setup
Linux
Note on Ubuntu
If you have Ubuntu:
- Carefully read the text below!
- DO NOT INSTALL
rustTHROUGHapt. Install using official installation instructions and userustup- before installation, make sure you have
build-essential,libfontconfigandlibfontconfig1-devinstalled- Be prepared for annoying problems
We recommend you to use Linux for this course. Mac OS X, should work fine but Windows has proved troublesome. We strongly discourage using Windows, it is possible for this course but not future courses. Therefore, we recommend you start learning and using Linux from the start.
Since everything has been tested on Linux, this is what we can best give support on. On other platforms, we cannot guarantee it.
If you're new to Linux, we highly recommend Fedora Linux to get started. If you would like to actually learn about Linux and become more proficient with it, we do recommend giving Arch Linux a try.
You might find that many online resources will recommend Ubuntu to get started, but especially for Rust development this
may prove to be a pain. If you install Rust through the official installer, it can work just fine on Ubuntu.
However, if you installed rust through apt it will not work.
Fedora also provides a gentle introduction to Linux, but will likely provide a better experience. For this course and for pretty much all other situations as well.
See Toolchain how to get all required packages.
Toolchain
To start using rust, you will have to install a rust toolchain. To do so, you can follow the instructions on https://www.rust-lang.org/tools/install. The instructions there should be pretty clear, but if you have questions about it we recommend you ask about it in the labs.
To install all required packages for Fedora run the following:
sudo dnf install code rust cargo clang cmake fontconfig-devel
Warning
Do not install
rustcorcargothrough your package manager on Ubuntu, debian or derived linux distributions. Read our notes about these distros here and then come back.Due to their packaging rules, your installation will be horribly out of date and will not work as expected. On Fedora we have verified that installing rust through
dnfdoes work as expected. For other distributions follow the installation instructions above and do not use your package manager. See our notes on Linux.
Editor setup
To use any programming language, you need an editor to type text (programs) into. In theory, this can be any (plain-text) editor.
However, we have some recommendations for you.
Why use an external editor?
We use weblab to give you practice assignments for the course. However, the editor built-in to weblab is far from the best available. Maybe you will find that it is sufficient, which is fine. But it may benefit you to use an external editor, a text editor you have installed on your computer. Some advantages of that are:
- Better/smarter autocomplete to make programming faster (the one built-in to weblab is very basic and won't help you much)
- Easy renaming and refactoring of code if you make mistakes
- Code generation
- Debugging code
- Stepping through code line by line
- Stopping execution at a certain line and the ability to see the values of variables at that moment
We also expect you and your team to use your own editor during the project.
Rust Rover (Jetbrains IDE)
To use it you can get a free student-license at https://www.jetbrains.com/community/education/#students
You will have to download the rust plugin for CLion too. This is easy enough (through the settings menu), and CLion might even prompt you for it on installation. If you can't figure it out, feel free to ask a question in the labs.
Visual Studio Code
Visual Studio Code (not to be confused with "visual studio") is an admittedly more light-weight editor that has a lot of the functionality rust rover has too. In any case, the teachers and TAs have experience using it so we can support you if things go wrong. You can easily find it online, you will need to install the "rust analyzer" plugin, which is actually written in Rust and is quite nice.
Other
Any other editor (vim, emacs, ed) you like can be used, but note that the support you will get from teachers and TAs will be limited if at all. Do this on your own risk. If you're unfamiliar with programming tools or editors, we strongly recommend you use either CLion or VSCode.
Lecture Notes
Here you can find the lecture notes for each Lecture, they might also contain extra information that is not talked about in the lecture. Below you can find links to each of the notes, together with a very brief course summary.
-
Lecture 1: Intro to Rust (and basics); In this lecture we start up the course, compare Rust to some alternatives and talk about the basics of programming in the language and in general. We will briefly cover a few basics such as loops, conditionals, and some datatypes.
- Lecture 1.5 (Lab 1): Git; Since the course has just started, we will use the first lab session to talk about Git. This has little to do with the rest of the lectures, but is vital to program in teams. You will use Git extensively in the group project later in this course, and right now already for other courses like Advanced Computing Systems. That is why we cover Git already so early in the course.
-
Lecture 2: Data Types; In this lecture we talk about data types, and how they can describe memory. We cover the primitive data types such as numbers, and some simple compound data types such as
Vecas well as how to create your own data types. -
Lecture 3: References and Ownership; In this lecture we talk about what rust calls "Ownership". We will discuss what references are, and how they relate to ownership, something that is called borrowing. We also look at so-called "Sized" types and unsized types. We may finish the in-person lecture with a discussion on string types in Rust and on unicode.
-
Lecture 4: Enumeration Types; In this lecture we cover what enum data types are and their difference to structs. Note that enums in Rust are quite different from those in other languages! We will also discuss error handling using the
Resulttype and optional data with theOptiontype.- Lecture 4.5 (Lab 4): Errors; An extension to Lecture 4, where we live-code an application which can produce errors, and we see how we handle this. This page shows the code we wrote during this lecture.
-
Lecture 5: Generics and Traits; In this lecture we will discuss generics. We already saw them very briefly during the last lecture. We talk about generic data types and generic code (functions), and how types can be bounded by so-called traits: properties of types. If time permits, we will finish with types and functions which are generic over a lifetime.
-
Lecture 6: Iterators and Collections; In this lecture we talk about several more standard collections:
HashMapandHashSet. Then we go into whatIteratorsare: how they interact with for loops, and how we can iterate over various collections. The ones discussed in this lecture, but alsoVecandString.
-
Lecture 7: Testing and Tooling; In this lecture we will talk about testing code, both while coding and to build confidence that code is correct when done coding. We will also discuss some static analysis tools which can help when writing code:
clippyandrustfmt. -
Lecture 8: Modules, Crates, and the group Project; In this final lecture we talk about how modules and crates work. During the individual assignment you may have already interacted with them but you might not have figured out how they work completely. We will also talk about
cargorust's package manager and about the libraries available oncrates.io.
After week 4, there will be no more lectures and thus no more lecture notes. Instead, you will work on a group project which you can find information about here
Lecture 1: What is Rust?
Software Fundamentals is part of the Computer and Embedded Systems Engineering study. Programming computer systems is an important part of embedded systems. C (together with C++) has been the standard for programming such systems for many years, to a point that many of you will likely be familiar with it. C has many advantages:
- C has had tooling built for it for close to 50 years
- Many people know C
- It has become a standard for foreign function interfaces (communication between programming languages)
- It has a well-defined specification (ANSI C) with a well-defined ABI that can (often) be relied on
- It is very fast compared to almost all other languages
However, over the years, many people have sought to improve C since the language also has several shortcomings:
- Few compile-time checks (leading to bugs)
- Relatively weak type system (you can very easily convert pointers of one type to another)
- Non-trivial safety problems like buffer overflows (no memory safety)
- No namespacing, all functions are (essentially) global
- Many non-standard extensions by compiler vendors that are relied upon by many
- Bad unicode support
Languages trying to improve on C have existed for a long time. Some examples you may know:
- C++ (Adds classes, lambda functions, generic templating, compile-time code execution)
- Java (Adds classes, a garbage collector, portable binaries, though not always as useful for embedded)
In this course, we're going to be using, and teaching you, a language called Rust. Rust is a relatively new language (it has only existed since 2009), and yet it has been the most loved (now called 'admired') programming language for the past 8 years. Because the language is so new, it takes advantage of many lessons learned in programming-language development in the past 40 years, that C hasn't benefited from because of its age.
The language was originally created by Graydon Hoare at Mozilla, but is currently developed by the Rust community. The original pitch by Hoare can still be found here, although it looks almost nothing like modern Rust. Rust is open source, you can find (and contribute to) it's source here. Every 6 weeks there is a new release with bug fixes, and possibly, new language features.
In this course, we will teach you to work with Rust, and talk about what sets it apart and why we chose to teach you this compared to other systems languages like C and C++
In the rest of these notes, we will compare Rust in a few ways to C, C++ and Java. Although C and C++ might sound obviously relevant since they are also systems programming language, Java maybe less so. Still, it provides some contrast being a fairly high level programming language with similar syntax to the other languages discussed. Additionally, Java is the main language taught in the Computer Science department.
Memory safety
In this part, we will refer to the "heap" and the "stack". In lecture two, we will talk more about what those are. You can already read about it here.
Memory safety is the property of a programming language aimed to prevent memory errors. When a language is not memory safe, bugs like the following can happen:
- Out of bounds reads and writes (of arrays), reads and writes to uninitialized memory. In a language like C, if you make e.g. an array of 5 elements, C won't prevent you from reading the 11th element even though that won't exist. The value that is read may be another variable, or uninitialized (and random). If a value is written out-of-bounds, it may overwrite another variable, or crash the program.
- Race conditions. Memory that is shared between different threads of execution are concurrently read from and written to leading to unexpected behavior.
- Use-after-free. Some memory is allocated, then used, then deallocated. But if a pointer to the allocated memory still exist, the memory can still be read from or written to causing unexpected behavior.
- Memory leaking. Allocations are made, but never freed leading to a constant increase in memory usage which may starve the system of resources.
- However, Rust does consider memory leaks to be safe as it can not trigger undefined behaviour. Of course Rust still tries to minimize memory leaks as much as possible.
These issues may lead to unexpected crashes of programs. However, if one of these bugs occurs and the program does not crash, the result may be even more alarming.
- Out-of-bounds reads may read data that is supposed to be private.
- Race conditions may cause writes to be missed, which could even lead to deadlocks.
- If memory is still used after deallocation, but another, unrelated, allocation is made at the same location, secret information may leak, or vital information could be corrupted.
- Leaking of memory may cause other programs which may be vital to the operation of the system to suffer.
A memory-safe language aims to make it impossible to be in one of those situations. This can be achieved through careful compile-time checking or through extra work at runtime. This article is a very interesting read if you want to learn more about the different possible techniques used to check for memory safety at compile time.
Memory safety in C, C++ and Java
Let's look at an example of a language that is not memory-safe: C.
#include <stdio.h>
char * read() {
char buf[20];
gets(buf);
return buf;
}
int main() {
char * r1 = read();
char * r2 = read();
printf("%s -> %s\n", r1, r2)
}
void secret() {
printf("secret!");
}
This program simply reads two strings from a user, and then prints that. What could go wrong? Well, what if the user types
21 characters? There's only room for 20. What would we overwrite? Well, right next to buf, there is probably the return pointer. The location to go to when
the read function is done (back to main). If we type 20 characters, and then the address of the secret function, we'd return to secret instead of main and print "secret!".
But let's say we did only type less than 21 characters. Let's say we input hello and world.
$ ./program
hello
world
> world -> world
We would probably see "world -> world". Why? Buf is a local variable in read. If we return from read, the variable doesn't exist anymore. So r1 doesn't
really point to a proper string any more. But it's very likely that the data is still stored there anyway. And if we call read again? Then the same memory location
is used for the second read. And then returned again meaning the variable is invalid again. So this program would either crash, or show "world -> world" (the second string twice).
In C++, something similar will happen.
However, in higher level languages like Java, which is memory safe, we would not experience these kinds of issues.
First, an array like char[20] would be allocated on the heap. Both times we run the function, a new allocation is made, and thus a new string is created.
Next, strings are not constant-size. If you input more than 20 characters, the allocation will simply grow and the extra characters will be stored in the extra space.
Strings also store their own length. Every time when data is accessed (by printf for example), a check is done to see if the accessed data is within bounds (which can be checked when you know the length).
Instead of losing the allocation when read would return, all allocations are sort-of "permanent". They last until they are not used anymore. Returning a string is therefore no issue.
import java.io.*;
public class Main {
static String read() {
Console console = System.console();
return console.readLine();
}
public static void main(String[] args) {
String r1 = read();
String r2 = read();
System.out.println(r1 + "->" + r2);
}
// cannot be accidentally or maliciously called
static secret() {
System.out.println("secret!");
}
}
So how do we check when data is not used anymore? A common method is called reference counting.
The garbage collector and reference counting.
Part of Java's solution to this memory unsafety is the reference counting. It works as follows. Every time we make an object (like a string), we also store a so-called "reference count", which will keep track how many "users" there are of this string. The only way we can use a string is if the program knows where its stored (the object is referenced). So whenever we create more references to an object, the language automatically adds code which increments this reference counter. And when you stop using a reference to an object, the reference counter is decreased. At some point, the reference count may reach zero. At that moment, we know that no variable in the program knows the location of the string object any more. And that also means it can't ever be used again, and thus may safely be deallocated (deleted).
With stopping to use a reference, we do not mean that objects are simply deleted after a while. Instead, when an object is used in a function and the function returns (and that object is not returned), there is no way to access the object anymore. At that point, we can be sure that it is safe to decrease the reference count by one.
String exampleFunction() { String example = "This is an example string"; // at this point it becomes impossible to access `example` anymore. // as the variable is out of scope. // Therefore, we can be sure the reference count can be decreased. return "this is the string that is returned"; }
There is one problem with this strategy. Let's look at the following C program, and let's pretend that C actually uses reference counting.
// Create a struct example, which points to another example struct
typedef struct example {
struct example * other;
} example_t;
void create_circular() {
// e1 referenced once
example_t * e1 = (example_t *)malloc(sizeof(example_t));
// e2 referenced once
example_t * e2 = (example_t *)malloc(sizeof(example_t));
// e1 references e2, so e1 is referenced twice
e1.other = e2;
// e2 references e1, so e2 is referenced twice
e2.other = e1;
}
int main() {
create_circular();
// Both variables, e1 and e2 are gone after calling the function.
// But e1 still references e2, and e2 still references e1. Their reference
// counts are still both 1 and won't be freed by a reference-counting scheme
}
In actual c, you wouldn't have reference counting and this code would just contain a memory leak. Although, even if reference counting is used, (like Java would do), this code would still contain a memory leak! To solve that, we need a garbage collector. A garbage collector is, in essence, a program that periodically searches for unused circular references, and removes them. How exactly this works isn't that important, but if you want to know more you can just search for it.
What is important, is that this all takes time. Reference counting takes time (and some space, for the reference count number). Periodically sweeping memory to search for circular references takes time. Allocating all objects on the heap takes time. Checking the bounds of arrays takes time. Thus, in Java and other such languages, we pay for memory safety with slower program execution. This may be well worth it, but especially on embedded systems which are resource-constrained, this extra slowdown can be unacceptable.
Although we will see that Rust doesn't need a garbage collector, people have made garbage collectors for Rust. What's neat is that it's possible to implement one in Rust itself, without needing to change the language itself. This is a link to an interesting article about such a garbage collector.
Static memory safety
Rust takes a new approach. Instead of handling memory safety at runtime, it tries to detect memory unsafe programs at compile time, partly through the type system. This means that if you make a mistake which could cause memory safety bugs, your program simply will not compile and in Rust's case, a helpful error message is shown explaining why it can't allow what you tried.
Let's translate our previous example to Rust and see what it has to say:
// let's assume this exists in the standard library fn gets(buf: &str) {todo!()} fn read() -> &str { // an empty string of 20 characters (non-ideomatic) let buf = " "; // not actually a function in Rust, but let's assume // it exist gets(&buf); return &buf; } fn main() { let r1 = read(); let r2 = read(); println!("{} {}", r1, r2); }
Unicode (A Slight Detour)
In C, a character is the size of a byte. That would mean that there can only be a total of 256 characters. At first, this was enough, but as soon as computers started communicating across international borders, problems arose.
- Some languages have accents on letters, like French, German, Scandinavian languages, and more
- Many languages don't even use the Latin alphabet.
- Some languages have more than 256 "letters" (Unicode calls them "graphemes" since not all languages use letters, like the symbols in many Asian languages)
- Many countries have different currency symbols
- People want to use both Emojis and Flags
The Unicode consortium has created a standard in which all symbols you would ever want to use in writing are assigned a number, also called a unicode codepoint. The most common encoding before unicode was ASCII. All ASCII symbols kept their old codepoints, but many more were added. In total almost 100.000 in unicode version 4.0.
To store characters as numbers up to 100.000 (and more are supported), we need to store them in more than just one byte. In Rust, the
chardatatype is actually a 32-bit integer.If every character was a 32 bit integer, the text "hello" would be 20 bytes long. But why? Many of the unicode codepoints are rarely used. Not even all codepoints are assigned, so some are never used.
To encode strings of unicode data, different encodings were invented. The most common is UTF-8. This is a variable-length encoding where when a letter is in the old ASCII range, the size of each character is only 1 byte. Only when a character is used that does not exist in ASCII, more bytes are used to encode it. 2, 3 or 4 depending on the character.
A Rust
&stris always utf-8 encoded and is thus not equivalent to achar *(byte array). You can create byte strings with the special byte string literal:b"test"(with abin front)
The &str type describes a reference to a string. So let's change the program a bit.
#![allow(unused)] fn main() { fn read() -> &str { let buf = " "; gets(&buf); return buf; } }
But the Rust compiler will loudly complain about this program. gets didn't get a mutable reference.
It can't modify the string to put the read data in.
And that's a good thing. Rust wouldn't allow us to make this string mutable even if we wanted to since we don't know the length in advance.
A gets function would want to grow and shrink the string based on how many characters a user types.
The only way to do this is to allocate the string on the heap. That way it can grow (this is exactly what Java did).
Let's change the program again. We do that by using the String type, which is a heap-allocated string.
(Do note that none of the programs above compiled so far. In each example something was wrong that could
be a safety bug, and the compiler stopped each from compiling meaning that the bug could not occur when running the program).
// let's assume this exists in the standard library fn gets(buf: &mut String) {unimplemented!()} fn read() -> &str { let mut buf = String::new(); gets(&mut buf); return buf; } fn main() { let r1 = read(); let r2 = read(); println!("{} {}", r1, r2); }
But this still won't compile. We return a reference to a string from this function &str. But buf is a local variable.
This is exactly the same problem we had in our C program, where after the return the buf wouldn't contain the data we wanted to anymore.
The solution? Don't return a reference, but return the ownership of the heap allocated string. This stops it from being deallocated when the function returns,
and instead deallocates buf when main returns (and the program ends). That looks like this:
#![allow(unused)] fn main() { fn read() -> String { let mut buf = String::new(); gets(&mut buf); return buf; } }
This is somewhat equivalent to the Java version, where the string is allocated on the heap and can therefore live longer than the function where it is created in. Rust does not need reference counting since it only allows a single place to have ownership of an object. If there can only be one reference, we don't need to keep track of it.
Abstractions for systems programming (only C and C++)
The Rust compiler is conservative. That means, it checks your program, and guarantees that it won't be memory-unsafe at runtime (see memory safety). But sometimes, a program that is in fact memory-safe, is rejected. The compiler isn't always aware of all the invariants of the exact system you are programming for. For example, some categories of race conditions cannot happen on single-core machines. This poses a problem, since sometimes you need to do something that is safe, but the compiler can't guarantee that.
Let's look at a relatively simple example: Rust's safety rules say that you may only have a single mutable reference to an allocation at a time. So at the same time, it must be impossible to update a variable from two different places, because that can cause a race condition.
An array can be considered a single allocation. But when you split the array into two halves, it's actually perfectly safe to mutate the two halves at the same time since the halves don't overlap at all.
So it is safe to write a function like
#![allow(unused)] fn main() { // splits `inp` at index `at` and returns a mutable // reference to the left and right halve fn split<T>(inp: &mut [T], at: usize) -> (&mut [T], &mut [T]) { unimplemented!() } }
But Rust cannot check it to be correct (what if the halves do overlap. That entirely depends on your implementation).
To accomplish this, you can introduce small sections of so-called "unsafe" code in your program. Code that is so-called "sound" but the compiler cannot check it. For split, this would be:
#![allow(unused)] fn main() { pub unsafe fn split_at_mut_unchecked<T>(inp: &mut [T], mid: usize) -> (&mut [T], &mut [T]) { let len = inp.len(); let ptr = inp.as_mut_ptr(); // SAFETY: Caller has to check that `0 <= mid <= self.len()`. // // `[ptr; mid]` and `[mid; len]` are not overlapping, so returning a mutable reference // is fine. unsafe { // from_raw_parts creates a new &mut [T] from a pointer and a length (from_raw_parts_mut(ptr, mid), from_raw_parts_mut(ptr.add(mid), len - mid)) } } fn split<T>(inp: &mut [T], mid: usize) -> (&mut [T], &mut [T]) { assert!(mid <= inp.len()); // SAFETY: `[ptr; mid]` and `[mid; len]` are inside `inp`, which // fulfills the requirements of `from_raw_parts_mut`. unsafe { split_at_mut_unchecked(inp, mid) } } }
Notice the unsafe blocks. Code inside those can be memory unsafe if the programmer wants it to.
The reason this is better than allowing unsafe code everywhere, like in C, is that you can audit these small sections much more easily than the entire codebase of a program.
If a memory bug occurs, they must have occurred in these sections. If there are relatively few of them, that makes your life easier.
Notice too, that the split function is not marked as "unsafe". split uses unsafe code, but it has been thoroughly checked and
as long as you perform the unsafe operations through the split function, your program is safe.
We call the split function a safe abstraction. They form small enclaves of unsafe code that perform
common operations. And as long as you don't write the unsafe code for those operations yourself, and instead
use the safe abstraction, your program is safe!
So why Rust?
Rust promises both fast and safe code, and is suitable to program embedded systems. That makes it a strong alternative to languages like C and C++. Should we do away with C and C++? No, of course not. So many systems already run on C code and work fine. But adding some more safety to systems without much runtime cost, is something worth doing in the future.
Learning Rust
The Rust language comes with a book, written by Steve Klabnik, Carol Nichols, and the Rust community. Together with these lecture notes and the book, you may learn enough about the language already. However, in the live lectures and the labs, there will be opportunity to ask questions which we encourage you to do. We can have discussions about them, so everyone can learn from your questions.
Lecture 1.5: Git
The lecture notes for this lecture are a bit different. This lecture is heavily inspired on an article and lecture given in Cambridge.
Therefore, I'd like to refer you to the original video lecture:
And the original article:
https://missing.csail.mit.edu/2020/version-control/
It, and the lecture we gave are both licensed under CC BY-NC-SA.
Changes
- We also talked about how to use CLion and git within a Rust project
- Custom part about remotes, with Gitlab, and merge requests
Extra: Git aliases
In the lecture, I used an alias called git nicelog. To make such an alias, you can apply the following instructions (on linux).
On windows, it will be similar, but I can't test the details, so you may need to apply some trial and error.
- Make a directory called
scriptsanywhere on your systems. The name doesn't need to be scripts, but that's what I like to do. - Add this directory to your path. To do this, edit a file called
.bashrcor.zshrc(hidden file in your home directory) and add the following to it:export PATH="/path/to/your/scripts:$PATH"and replace the path with the absolute path to your scripts directory- Note that you may need to reopen your terminal after this, or run
source ~/.bashrc/source ~/.zshrc
- now, make a file in the scripts directory called
git-nicelog(name needs to start with git, then a-and then the name of your alias) - Put the following in the file:
#![allow(unused)] fn main() { #!/usr/bin/bash git log --all --graph --decorate }
- The first is to say that it's a bash script, and the second line is the command to execute instead of
git nicelog. - Now make the file executable using
chmod +x git-nicelog. - Now, anywhere on your system, type
git nicelog
Lecture 2: References
Contents
Ownership and References
We recommend that you read the rust book section about ownership and the book section about references to learn about this. In the lecture we discuss it at length, but the rust book already contains an excellent written explanation of the ownership rules (and why ownership rules!).
However, here is a summary of ownership rules and references:
- Ownership:
- Each value in Rust has an owner, in the form of a variable binding.
- A value can have only one owner at a time.
- When the owner goes out of scope, the value will be dropped.
- Ownership can be moved to another owner using assignments or function calls
- References:
- You can reference a value using
&or&mut. This borrows the value, but does not transfer ownership. - A reference cannot keep existing after the owner is dropped or moved.
- While a mutable reference to a value exists (which is until the mutable reference is dropped), no other references to the value can exist.
- You can reference a value using
Traits
In lecture 5, we will talk about traits in much more detail. That mean's that although information stated here will be true, they may not be the whole truth.
A trait is something that marks a type. For example, a trait may indicate that values of a certain
type can be copied, or compared to one another for equality. If a type is marked by a trait, it is said
that that type implements the trait. For example, it is possible to determine whether two integers
are equal. Therefore, integers implement Eq. However, floating point numbers do not implement Eq.
The reason for that is, among other reasons, that there are multiple different bit patterns that all mean
Not a Number for floats.
For this lecture, only a few traits are important. Clone, Copy and Sized.
If a type implements Clone, it is possible to duplicate a value of that type. For example:
fn main() { let a = 3; let b = a.clone(); // both a and b are usable now (they are both 3) }
Both a and b contain the value 3, and they both own that value. Of course, they do own a
different copy of the variable since a value can have only one owner. If a type implements
Clone, it has a method called .clone() which can be used to clone the value.
Some types that implement Clone, also implement Copy. If a type implements Copy, it signifies
to the rust compiler that cloning the type is trivial. For example, cloning an integer is trivial. You
do that all the time by moving it around. Types that implement Copy can be moved around freely.
In the example above, the a.clone() is not necessary. a is an integer, so
fn main() { let a = 3; let b = a; // a and b are both still usable now, since integers implement Copy }
leaves both a 3 in a and in b.
Not all types that are Clone, are also Copy. Most structs are not Copy. Let's take a Vec for example:
fn main() { let a = Vec::new(); let b = a; // only b is usable now, a is moved into b. }
The same code as before, now leaves a unusable (the compiler will complain if you use a) after a is assigned to b.
Vec is not Copy so simply assigning it does not copy it. It moves the ownership from a to b. If you want
both a and b to own the same vec, you need to use .clone().
fn main() { let a = Vec::new(); let b = a.clone(); // both a and b are usable now }
This makes the fact that you are cloning explicit. Cloning a Vec may take a considerable amount of time
if the Vec is large. If the compiler were to do it in the background, you may get weird performance issues. Instead,
you need to explicitly say when you want to clone a Vec, so you know at which points you're paying the performance cost.
Do note that cloneing itself is not bad. Sometimes you need to, and usually it's not actually that slow.
To see what traits a type implements, you can go to the type's documentation page. For example for the Vec:
https://doc.rust-lang.org/stable/std/vec/struct.Vec.html#trait-implementations. You will see
a line like impl<T> Clone for Vec<T> where T: Clone .... That means that a Vec containing a type T implements Clone only if it is possible
to Clone that type T, which makes sense.
Lastly, there are types that are Sized, which we will talk about in the next section.
Sized data
Some types in rust are Sized. Actually, many types are Sized. A type implements
Sized if that type has a size known at compile time. A struct automatically
implements Sized if all of its members also implement Sized. That makes sense,
if all members have a known size at compile time, the struct's size is simply the sum
of the members1.
Almost all types implement Sized. For example, integers, floats, booleans, Vec and most structs and references to types.
So what types don't implement Sized? One example is the slice type. You can read a lot
more about it in the rust book. You write
the slice type as [T]. That looks a lot like the type of an array: [T; n] where n is the length.
A slice is an array of unknown length. Therefore, we can't know its size at compile time, and thus [T] can't implement Sized.
Values of types that don't implement Sized, can't be stored in variables on the stack. So how do we use a slice? A reference to
any type always implements Sized. Regardless of whether the type referenced implements Sized. Thus, we can't say let a: [T], but we
can say let a: &[T]. A reference simply denotes a location in memory. We may not know the length of the array at that location at compile time,
but we can store the location of the data in a variable and pass it around.
Note that when I say that the compiler doesn't know a size at compile time, I don't mean that the size can change constantly, like with a Vec. Consider the following function:
fn test(a: [u32]) { unimplemented!() } fn main() { test([1, 2, 3]); test([1, 2, 3, 4]); }
test is called twice. Each time, with a different length array. The size of each array is perfectly known at compile time (3 and 4 elements). But
should the size of a be in the test function? 3 or 4 elements?
fn test(a: &[u32]) { unimplemented!() } fn main() { test(&[1, 2, 3]); test(&[1, 2, 3, 4]); }
However, if as above we give test a reference, we only give test the location of the array we pass it. So regardless of the length of the array,
what we pass to test always has the same size.
Slices
Generally, we call a reference to an array (like above) a slice. A slice comprises two parts. The location the data lives at (like discussed above),
but also the length of that data. This makes it possible to refer to segments of arrays and pass those around. Let's look at another example.
fn remove_first_last(a: &[i32]) -> &[i32] { if a.len() >= 2 { &a[1..a.len()-2] } else { a } } fn main() { let array /*:[i32; 4]*/ = [1, 2, 3, 4]; let result = remove_first_last(&array); println!("{:?}", result) }
This program should be pretty easy to understand. On line 10 we give remove_first_last a slice (with length 4, and pointing at array).
However, remove_first_last doesn't actually remove any elements. It just returns a new slice with a different starting position and length.
result acts like it's a new array. However, it actually is just a reference to the elements [2, 3] of the original array variable. You can still
use both the original array and result. However, at this point you can use neither to modify the array. Because remember the rules of borrowing!
There can only be a single mutable reference to a value, and if there is one, there can be no non-mutable references. Because result references array,
array cannot be mutated (and the compiler will reject your code if you even try).
And now you may start to understand why this rule exists. Since both result and array refer to the same data, if one of the two modifies the array, the other will
immediately notice. This makes your program extremely hard to reason about!
Strings

Rust has a lot of different types that all seem to just mean "a string of text". If you did C before, you may know that it represents all strings as char *s.
What are all these extra types for in Rust?
Let's start out with the simplest. &str is pretty much the same thing as a char * in C, and it will be the string type you will use most. A string literal
has this type, so you can write:
fn main() { let a: &str = "test"; }
There is a difference however. A &str in Rust is not the same as a &[u8] like it would be in C. This is because &str works with UTF-8 encoded unicode data.
Sometimes, you do want to work with just bytes, in which case there's the &[u8] type. So that covers two string types already.
You may know that in C, you can't always just add more letters to a string. To do that, you may need to use the malloc function and first find a space
large enough for the letters to fit in. Note that we had a similar problem previously with arrays. We called a resizable array, a Vec.
Well, we call a resizable &str a String! Internally it's pretty much a Vec of UTF-8 encoded characters. It's allocated on the heap, and automtacally
resizes if you add more data.
And those are all the string types you really need to know about for now. There are more, specifically to interoperate with C code (CStr, CString), or to
represent strings received from the operating system (OsStr, OsString), but you will probably not need those much in the near future.
-
Actually, the size of a struct isn't strictly the sum of its members. Usually, some padding bytes are inserted to ensure alignment and optimize access times. ↩
Lecture 2: Types and Memory
Contents
Simple Data Types
Computers are complex machines in which information is passed around and processed to perform complex calculations. The type of information that is processed can vary. Usually, modern computers are best suited to deal with integer numbers with a size of 64 bits.
However, that's not the only kind of data a computer can work with. For example, the actual size of the integers can vary. For a number from 8 till 128 bits. And whether the number can have a decimal point, or a sign (positive or negative) can change too.
In a programming language, the programmer is responsible for making choices about what kind of data should be passed around to accomplish the task at hand. In Rust, every value has a data type. By knowing these types, the Rust compiler can generate the right instructions to work with values of that type.
The Rust Book has a very nice section about primitive data types if you want to know more.
Storage Locations
During the execution of your program, values are constantly moved around and modified. But where are the values stored on your computer?
Generally, a computer has a limited number of very fast storage locations, which are called registers. Registers are located inside the processor right next to the place where calculations happen. However, since there are usually only very few registers, values are frequently moved to and from memory.
The memory of a program is usually split into two parts: The stack and the heap.
The stack is a place where "local variables" are stored; variables associated with the function that is currently executing.
Every time a function is called, a new section is added to the stack (such a section is called a stack frame).
Then, when a function returns, the frame is removed again.
One of the reasons stack frames are used, is because they allow functions to be recursive. In other words, functions can call themselves like the function below.
fn factorial(n: u64) -> u64 { if n <= 1 { 1 } else { n * factorial(n - 1) } } fn main() { factorial(10); }Every time a function is called, a new stack frame is created containing the local variables of that function. In the example, that means that a new stack frame is created for every call to
factorial: one in which n=10, then another one with n=9, n=8, etc. Every call to the function gets a new 'version' ofn.
A stack in memory is very similar to a stack of cards. You can easily add more cards to the top of the stack, and then later remove them again starting at the top and working your way down. However, removing parts from the middle is a lot harder. Luckily, when calling functions this is not really an operation we have to perform. When we call a new function we add a frame to the top and when we return we can remove the topmost frame. If you want to know more about the stack, this Wikipedia article explains it well.
Alternatively, values can be stored on the heap. The heap is much more flexible. At any moment, the program can request a certain number of bytes it wants to use on the heap. Then, some time later, it can signal that the bytes aren't used anymore and can be reused for something else.
Usually, an 'allocator' is responsible for managing the heap. It will find an unused spot and mark it as used until the program is done with that bit of memory. Allocating space on the heap takes some time, an allocator needs to actually find an unused bit of memory which is of the right size. This means creating values on the heap is slower than creating values on the stack.
Note that using values on the heap is not necessarily slower than using values on the stack! They're both simply places in memory, and loading a value from the heap into a register takes a similar amount of time as a value from the stack (if we ignore cache...).
So why is a heap necessary? In a program, you want to avoid copying large pieces of data around all the time. That can become very slow. Instead of copying values around, you can instead reserve a bit of space for it and remember its location. Using that location you can look up the value from anywhere it is needed.
But when your value is located on the stack, you cannot keep referring to values lower down on the stack. When you return from a function, the current stack frame is deleted (as we discussed earlier). If you were remembering a location of some data located in that stack frame, that location becomes invalid after the stack frame is removed. In that situation it'd be nice if we can store things in a separate place in memory that stays valid even after the stack frame is gone. And that, is the heap!
The Rust book also has a good explanation about the differences between the stack and the heap.
Box
To put a value on the heap, you need to allocate a region to put it in.
Rust calls such an allocation a Box.
A Box is actually just a number, which refers to some location in memory, that is to say a pointer.
That means that, if you create a Box with a very large value inside, passing around the Box is very cheap since it's just a pointer.
So if you want to make a variable on the stack with a very large integer in it, you would write:
fn main() { let a: u128 = 3; }
But if you want to put value on the heap, you would write:
fn main() { let a = Box::new(3u128); }
This makes a new allocation on the heap, with the size to hold an 128-bit integer and puts the number 3 there.
It also makes a variable on the stack, called a.
Instead of holding the number 3 (and all 16 bytes of it), this variable holds the location in memory, which is only 8 bytes large.
Of course, the difference between 8 and 16 bytes isn't a lot but for larger and complexer types this can make quite a difference!
In most cases you can use the Box in the same places where you would normally use a number, except that you sometimes may need to dereference the box:
fn main() { let a = Box::new(3); // the star means to use what's *in* the box (the value on the heap) // instead of the box itself for the calculation println!("{}", *a + 3) }
Scope
In the example above, at the end of main the box is "dropped".
That means that the stack frame of main is removed with all its local variables (like a).
However, the Box also makes sure that the space reserved on the heap to hold the large data is automatically marked as available; this is called deallocation.
Dropping happens at the end of the scope of a variable.
When a variable goes "out of scope" (which is at the end of a function or, as we will see shortly, a block), the value is "dropped" meaning the space used for it is cleaned up.
Scopes are always indicated by curly brackets ({ and }).
You can make scopes in your program wherever you like:
#![allow(unused)] fn main() { fn test() { // the braces indicate the function's scope let a = 3 ; // lives to the end of the function { // we make a new scope with brackets let b = 4; // b lives until the end of the scope } // b is gone here, we can't use it anymore since the scope ended for i in 0..5 { // we start a scope again // i is part of the loop's scope, and x is too let x = 5; println!("{}", x + i); } // so here we can't use i and x anymore // we can still use a, the scope hasn't ended println!("{}", a); } }
Compound Data Types
In a program it is often useful to group values together. Instead of storing just one number, it's often useful to store several together. There are multiple ways to manage this in Rust which we will discuss here.
Arrays
An array is a structure which holds a fixed number of elements of a specific type. For example, 5 integers, or 10 characters:
fn main() { let digits = [0, 1, 2, 3, 4, 5, 6, 7]; }
The type of the value in digits is now: [i32; 8]. Note that this type description consists
of two parts: i32 (so it's an array of signed 32-bit integers) and 8 (there are 8 of them).
The type [i32; 8] therefore takes up the space of 8 i32s, or 8 * 4 = 32 bytes.
Because the value is stored in a local variable, those 32 bytes are allocated on the
stack.
(See! Now Box::new([0u8; 2048]) might actually make sense if we pass it around a lot: Instead of having 2048 bytes on the stack, we can have only 8 on the stack and 2048 on the heap)
To access an element of an array, you can use the index operator:
fn main() { let mut nums = [12, 9, 16, 5, 7, 2, 6, 15, 11, 8]; // get the 5th element of the array. // Note that we start counting locations in an array at 0, // so this prints the number 2, not 7! println!("{}", nums[5]); }
An array is just many variables
An array is simply a way to automate the creation of multiple variables of the same type at once. The above example of the array with 8 numbers is equivalent to the following:
fn main() { let digits_0 = 0; let digits_1 = 1; let digits_2 = 2; let digits_3 = 3; let digits_4 = 4; let digits_5 = 5; let digits_6 = 6; let digits_7 = 7; }
Sure, the semantics are a bit different (now there are 8 different variables with different names), but in memory, this looks identical.
Why do all elements of arrays need to be the same type?
Because the elements are the same type, they are also the same size. This is a very useful property. For example, if we want to know where the 8th element of an array is stored, we can just calculate that!
Given that we know where the first element is stored, we just move over 8 times the size of an element. So if the size of one element is 4 bytes, the 8th element is stored 28 bytes from the start. That property makes finding elements in an array very fast.
For example, in the following example each element has a size of 1 byte. The array starts at 0000, so the 8th element
is at position 0007
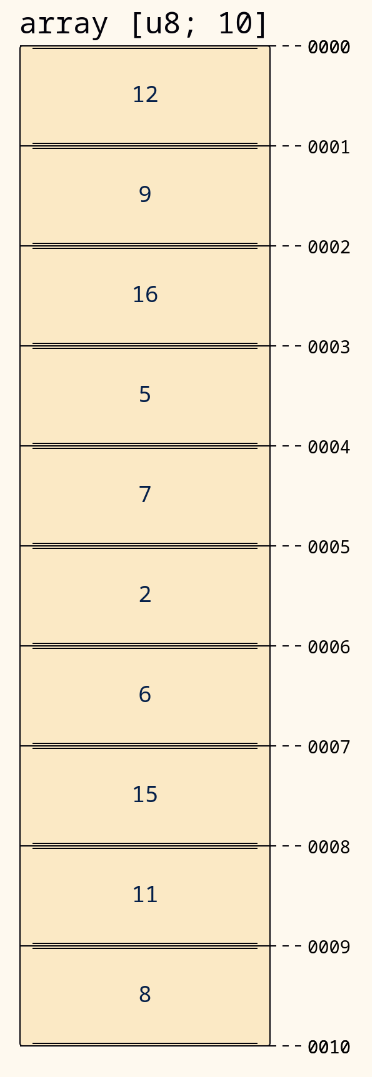
Resizing
Arrays do have a limitation. Let's look at the following example:
#![allow(unused)] fn main() { /// create an array with the `value` repeated `length` times. fn create_array(length: usize, value: u32) -> [u32; todo!()] { todo!() } }
How would we make this function? If we want to make an array, the compiler needs to know how much space to reserve for it on the stack. However, the compiler doesn't know this size! The length is just a variable, it can be any number. Maybe the program first asks a user to type in a number at runtime, which the compiler of course has no knowledge of.
This is a limitation of an array: The compiler needs to know its size, and this size can't ever change during the execution of the program. We can solve this by using a vector.
Vector (Vec)
A vector is a kind of array which can grow and shrink on-demand during the execution of the program. How does that work? Well, the elements aren't stored on the stack. Growing things on the stack is very hard, because you can only really allocate on the top. Not in the middle of the stack.
Instead, Vec stores elements on the heap just like Box.
Effectively a Vec is a just very large Box that holds not one, but many elements.
You can make a vector like this:
fn main() { let mut a = vec![1, 2, 3, 4, 5, 6]; }
That's very similar to an array. But we can now do something we couldn't do with arrays:
fn main() { let mut a = vec![1, 2, 3, 4, 5, 6]; a.push(7); println!("{:?}", a); }
We can add the 7 to it!
That means we can also implement the example from Resizing
#![allow(unused)] fn main() { fn create_array(length: usize, value: u32) -> Vec<u32> { let mut result = vec![]; for _ in 0..length { result.push(value); } return result; } }
For all the ways to interact with vectors (grow them, shrink them, etc), we recommend you to look at the documentation.
Implementation details
But, how does a vector work?
A vector is actually a struct.
We will look into these later this lecture.
Maybe it helps to continue reading first and then come back, so you understand this section better.
The vector struct contains 3 parts. A length, a capacity, and a Box with an array of elements. Yes, a normal array as we discussed before.
But, because the array sits in a box, it means the elements are located on the heap.
#![allow(unused)] fn main() { // the <T> part means that this struct is generic over a type. You can // see the name `T` used later. This simply means that the data is an // array of a type T, but the user of Vec may decide what that type is. // That means that a vec can contain any type of element, like a Vec // of numbers or a Vec of strings. pub struct Vec<T> { length: usize, capacity: usize, data: Box<[T]> } }
So what's the difference between the capacity and the length? The terms sound pretty similar. The trick behind a vector is that the array with data is actually always too large.
For example, at first the size of data may be 8, even if there's only a single element in the Vec.
This means you can add more things to the Vec before it is full.
The capacity is how many elements could possibly be stored, while the length is how many elements there are actually stored in the vector.
So at some point, if you add enough elements to the Vec, the length will become equal to the capacity.
What if we want to add more elements?
The most common strategy (also used in the built-in Vec) is to double the capacity when this happens.
So if the capacity started at 8, we double it to 16 and then 32, etc.
Each time we increase the capacity, we make a new allocation of the appropriate size, and copy all the data from the old to the new location on the heap.
If everything is copied, the old allocation can be removed, and all the data is safely stored in the new place with some capacity left-over.
This resizing can be very costly. The larger the array is, the more data needs to be copied. That's why the size is doubled every time. That ensures that the resizing will need to happen less and less often, compensating for the longer and longer duration it will take every time.
With this strategy, resizing actually doesn't take any time at all, on average. You resize more and more data but less and less often. This is called amortization.
Note that you can manually set the capacity of a vector. This may be desirable if you can cheaply calculate the final capacity of the vec in advance, to avoid multiple automatic resizes.
Tuple
So what if you do want to store multiple things of different types (and thus sizes)? In that case, to keep things fast, it would be very convenient if we knew all the sizes (and types) of the elements during compilation so the compiler can work out where to put things in memory.
Such a structure is called a "tuple". An example:
fn main() { // Saying the type like this is optional, as always, but // it's to show you what the type of a tuple looks like let a: (u8, u32, &str) = (3, 4, "test"); }
Here, we make a tuple of 3 elements. The size (in bytes) of this tuple, is 13 (1 + 4 + 8) bytes. The compiler can deduce this from the type of the elements, and thus can know where to store the elements in memory. This does mean that the size of a tuple always has to be fixed and known to the compiler.
Just like with arrays, a tuple is not so different from creating multiple variables. In memory the above example is looks a lot like:
#![allow(unused)] fn main() { let a_first = 3; let a_second = 4; let a_third = "test"; }However, the grouping a tuple provides can be more convenient to use.
Getting an element out of a tuple, works a bit different from arrays:
fn main() { let a = (3, 4, "test"); println!("{}", a.0); println!("{}", a.1); println!("{}", a.2); }
You simply use a dot, with a number.
The reason for that is that if you try to write an invalid index, like a.3, the compiler will simply not allow it.
Since the size of a tuple is always finite, the compiler knows the size and therefore also knows which indices (0, 1 and 2) are valid, and that 3 is not valid.
A tuple is a way to group multiple things of multiple types together in one variable. For that reason, a common application for them is returning more than one thing from a function.
For example:
// a function that calculates both the smallest and largest element in a vector: // notice we use a tuple (of two "u8"s) as a return type fn min_max(l: Vec<u8>) -> (u8, u8) { let mut min = u8::MAX; let mut max = u8::MIN; for i in l { if i < min { min = i; } if i > max { max = i; } } // make a tuple of both the smallest and the largest value (min, max) } fn main() { let a = min_max(vec![1, 2, 3, 4, 5, 6]); assert_eq!(a.0, 1); assert_eq!(a.1, 6); // we could also have written this: let (smallest, largest) = min_max(vec![1, 2, 3, 4, 5, 6]); // it makes two variables by "unpacking" the tuple assert_eq!(smallest, 1); assert_eq!(largest, 6); // maybe we only want the largest? let (_, largest) = min_max(vec![1, 2, 3, 4, 5, 6]); assert_eq!(largest, 6); }
The unpacking or destructuring of tuples and other types was discussed in lecture 2
The unit type
Sometimes, you want to say that a function returns "nothing". For example:
fn print_hello_world() { println!("Hello, World!"); } fn main() { print_hello_world(); print_hello_world(); print_hello_world(); }In our code, we just didn't put a
-> somethingafter the function. But actually, this:#![allow(unused)] fn main() { fn print_hello_world() -> () { println!("Hello, World!"); } }Is exactly equivalent. That's what rust actually inserts when you don't give a return type.
So what does
()mean? We call it the "unit type". That's because the unit type has only one value:(). We could thus write:fn main() { let a: () = (); }If we don't return anything from a function,
()is automatically returned (that's just the default).Notice however, that
()looks awfully similar to the syntax for a tuple. In fact, it's simply a "zero element tuple". A tuple with no values in it. And since there are no values in it, it has zero size and passing it around is essentially free.
Struct
Once you start combining more and more values in a single variable with tuples, keeping track of which value is at which index can become a pain.
At some point it can start making sense to use a struct.
A struct is a lot like a tuple, but we can give each element a name.
Additionally, we can give the entire struct a name, which we can use to refer to the entire grouping of the elements in the rest of the program.
Below is the same example as we gave with tuples.
But notice, we now created a struct MinMax.
We tell rust that the MinMax struct has two fields: smallest and largest. In the min_max function, we only have to say that
the return type is MinMax, and the compiler knows that it has the two fields.
struct MinMax { smallest: u8, largest: u8, } fn min_max(l: Vec<u8>) -> MinMax { let mut min = u8::MAX; let mut max = u8::MIN; for i in l { if i < min { min = i; } if i > max { max = i; } } MinMax { smallest: min, largest: max, } } fn main() { let a = min_max(vec![1, 2, 3, 4, 5, 6]); assert_eq!(a.smallest, 1); assert_eq!(a.largest, 6); }
In the main function, we can refer to a.smallest and a.largest directly. For such a small example, the names may not be absolutely necessary, but naming things makes code more readable and easier to work with.
At this point, I want to remind you that previously we told you to continue reading until after structs.
See if you understand the explanation about Vecs better now?
As you may have seen in the part about Vecs, a Vec is simply a struct.
Many other items in the standard library of Rust are structs.
Structs are so versatile because apart from holding data (with some names), they can also define methods: things you can do with structs.
For example, a Range struct holding something which has a start and an end:
#![allow(unused)] fn main() { struct Range { start: i64, end: i64 } }
to this struct we can now add "methods":
#![allow(unused)] fn main() { // add some methods to `Range` impl Range { /// This so-called 'static' method creates a new range pub fn new(start: usize, end: usize) -> Self { Range { start, end, } } /// This static method allows you to easily create a range /// that starts at zero. You only need to give an end. pub fn from_zero(end: usize) -> Self { Self::new(0, end); } /// This method is a method that's not static. /// That means that when we have previously created a value `r` of type `Range` /// we can call `r.invert()` on it and get two new ranges which /// describe everything below and above this `r` pub fn invert(&self) -> (Self, Self) { ( Self::new(i64::MIN, self.start), Self::new(self.end, i64::MAX), ) } } }
The type "Self" here, refers to the Range type since that's what we're adding methods to right now.
We can create new ranges like this now:
fn main() { let r1 = Range::new(1, 5); // 1 to 5 let r2 = Range::from_zero(5); // 0 to 5 }
And if we have made a range, we can invert it:
fn main() { let r = Range::from_zero(5); let (below, above) = r.invert(); println!("{} {}", below.start, below.end); println!("{} {}", above.start, above.end); }
Notice that there's a difference between the "invert" method and the "new" function.
The first parameter to invert is &self.
That means that when we say r.invert(), r becomes self. So r.invert() is the same as Range::invert(r).
Most of the functions on Vec you will get familiar with are methods.
You can even find a reference of all these methods on a Vec and every other struct.
Methods may still not be clear after this explanation. They are admittedly a pretty abstract concept, especially if you've never programmed before! Therefore, we encourage you to:
- Make the assignments on weblab associated with week 1.
- Read in The rust book about them.
Summary
- Values have types
- Different types have different sizes
- Values can be stored in different places in memory
- Stack
- Heap
- You can put multiple values of the same type together in an array
- You can use a
Vecto make an array that is resizeable at runtime - You can use a tuple to store a finite number of values of different types
- You can use a struct to name the type and values of a tuple
- Structs can have associated
methods, which represent things you can do with a struct and its contents
- Structs can have associated
Lecture 3: Enumeration types and Error Handling
Contents
Enums
A simple enum in Rust might look familliar to you if you have already seen them in other languages. They are a datatype with a finite number of "options", a finite number of values that they can represent. Let's look at an example:
enum Color { Red, Blue, Yellow, Orange, Green } pub fn main() { let a: Color = Color::Red; let b = Color::Blue; // bring all "variants" into scope use Color::*; // which allows us to omit the 'Color::' let c = Blue; }
The type of these variables (made explicit in variable a) is Color.
The value can be either red, blue, yellow, orange or green, we call these options "variants".
Just like you might be used to in C, you can choose numbers to represent variants.
#[repr(u8)] // this is optional, it tells rust to store this enum as a `u8` enum Color { Red = 5, Blue = 7, // if you don't specify one, it just continues counting. // so yellow will be 8 Yellow, // after 8 we jump to 10 Orange = 10, Green = 15, } fn main() { let a = Color::Red as u8; // Note that this does not work! // let c = 5 as Color; // *even* though 5 is a valid variant number. }
By default, (if you don't explicitly assign numbers) enum variants start counting at 0, in steps of 1.
Enums with data
Sofar, enums are pretty similar to C or Java's enums. However, in Rust enums are a lot more powerful. Enums can have data associated with each variant. Let's look at an example with IP addresses. There are both IPV6 and IPV4 addresses, and their representation is slightly different.
#![allow(unused)] fn main() { enum IpAddress { V4(u8, u8, u8, u8), V6(u128) } }
This definition says, that an ip address can either be a V4 address.
In that case, the type contains four 8-bit integers.
However, if the address is a V6 address, the value contains a single 128-bit integer.
We use it like this:
enum IpAddress { V4(u8, u8, u8, u8), V6(u128) } fn main() { let a_v4_address = IpAddress::V4(192, 168, 0, 1); // a u128 in hexadecimal notation. // Notice that we are allowed to use underscores to separate parts of numbers! let a_v6_address = IpAddress::V6(0xDEAD_BEEF_CAFE_BABE_BAAA_AAAD_1234_5678); }
Tagged Unions
This may look a lot like the definition of a union if you're used to C. Just like with unions, an enum with data is a bit like multiple overlapping structs. The same piece of memory can have multiple interpretations based on what variant is stored there. Therefore, enum types with associated data are sometimes called "tagged unions".
The "tagged" part refers to the fact that unlike unions in C, Rust's enums contain a tag that represent which of the variants is currently active. An example:
#include<stdio.h>
union FloatOrInt {
float f;
int i;
}
void main() {
// one variable
FloatOrInt u;
// we fill it as if it's a float, with a float value
u.f = 0.5;
printf("%f", u.f);
// now we use the same space for an integer
u.i = 5;
printf("%d", u.i);
// oops! even though an integer is stored in u,
// we interpreted it as a float by accident
// C will compile this code, even though it's undefined
// behavior.
printf("%f", u.f);
}
On the final line, C allows us to interpret a memory location that stores an integer as a float. Since the bit representation of a float is entirely different from that of an int, this will print nonsense. Because in C, unions have no tags, at runtime there is no way for code to check which variant is active: float or int.
In rust, enums are tagged. An example similar to the above example in C:
enum FloatOrInt { Float{f: f64}, Int{i: i64}, } fn main() { // initialize as a float let u = FloatOrInt::Float{f: 0.5}; // we cannot now do: // println!("{}", u.f); // since we haven't checked that u is a float // (here it's obvious but that's not always true) // check that u "matches" (see the next section) // the "Float" tag if let FloatOrInt::Float {f} = u { println!("{}", f); } // this code will not execute since the tag is `Float`, // not `Int`. We cannot accidentally interpret the memory // as an integer. if let FloatOrInt::Int {i} = u { println!("{}", i); } }
Here, if let Tag { ...fields...} = value { block of code } means that if value has the tag Tag, then put the contents in the variables mentioned in fields and make those variables available in block of code (and only if the tag matches, run the code that block of code).
We call this process matching, and we will dive deeper into that in the next section.
To read more about using enums, take a look at the rust book!
Matching
If you have an enum with data, you sometimes want to get this data out.
We briefly looked at matching with if let in the previous section on tags.
If we go back to the scenario of IP addresses, what if we want to write a function like the following, which returns the last byte of an IP address regardless of whether it's a v4 or v6 address.
#![allow(unused)] fn main() { fn last_byte(addr: IpAddress) -> u8 { ... } }
We could use if let again:
#![allow(unused)] fn main() { fn last_byte(addr: IpAddress) -> u8 { // is it a v4 address? Return the last byte if let IpAddress::V4(_, _, _, last) = addr { return last } // is it a v6 address? Return the last byte if let IpAddress::V6(value) = addr { return (value & 0xff) as u8 } // well it can't be anything except v4 or v6, // so we can just crash if we get here (we won't ever) unreachable!() } }
In general, you can do this by using a match statement.
#![allow(unused)] fn main() { fn last_byte(addr: IpAddress) -> u8 { match addr { IpAddr::V4(_, _, _, a) => a, IpAddr::V6(v) => v & 0xff, } } }
However, matching doesn't just work on enums with data in them. It works on any type:
#![allow(unused)] fn main() { fn print_color(c: Color) { match c { Color::Red => println!("red"), Color::Blue => println!("blue"), Color::Yellow => println!("yellow"), Color::Orange => println!("orange"), Color::Green => println!("green"), } } }
Or on integers, where it behaves more like a switch statement:
#![allow(unused)] fn main() { fn test(a: usize) { match a { 0 => prinln!("the number is zero"), 1 ..= 10 => println!("the number is small"), 11 | 12 => println!("the number is 11 or 12"), x => println!("the number is something else, specifically: {}", x), } } }
Note that regardless what you use match for, a match always must be exhaustive. That means, whatever
the value we match on it, one match arm must execute. So in the case of an enum, every single variant
needs to be handled, or a "catch-all" needs to be provided. In the example above, the x case is executed
if none of the other arms executed.
Sometimes you don't care about the value in the catch-all arm, and you can replace the x with a _ to throw it away.
Note that arms are evaluated in-order. That means you can't put the catch-all arm first since then it would always be triggered and none of the arms below would ever even be checked.
Options
One good application of enums, is when, for example, you have a function and it may or may not return a value. You could represent that as follows:
#![allow(unused)] fn main() { enum MayReturnNumber { Value(i32), Nothing } fn test(a: i32) -> MayReturnNumber { if a.is_even() { MayReturnNumber::Value(a / 2) } else { MayReturnNumber::Nothing } } }
This pattern is so common that the standard library provides a type like this. It's called Option<T>.
The definition of it is as follows:
#![allow(unused)] fn main() { /// From the standard library! /// Available without importing in any program pub enum Option<T> { /// No value. None, /// Some value of type `T`. Some(T), } }
And you would use it like
#![allow(unused)] fn main() { fn test(a: i32) -> Option<i32> { if a.is_even() { Some(a / 2) } else { None } } }
Notice that because Option is so-called "generic over a type T". It works for any return type. In the example
above we say that the type inside the option is i32, but it could be anything.
Niche Optimisation
Note: The following few paragraphs are about some internals of enums. You may find it interesting, but won't need much of it in your exercises. You can also skip it if you're in a hurry.
So how do enums work? Internally, they are so-called "tagged enums". Option<T> would desugar roughly to:
#![allow(unused)] fn main() { struct Option<T> { is_some: bool, data: T } }
Larger enums would get a number instead of a boolean determining which of the variants they are. And if more than one of the variants contains data, all the data is stored in the same location in the struct (this is possible since an enum is never two variants at once). Very similar to a union in c.
But this means that using an enum has a bit of overhead. This "tag" (the boolean or number determining what variant it is) needs some space.
Okay, let's keep that in the back of our mind for a bit. A common thing to do with for example Options, is to store a reference in it.
The reason for that is that rust doesn't ever allow a reference to be null. So if you want to have a type that works like a null pointer,
you'd quickly arrive at Option<&T> (where T is of course any type you like). But, you may say, that's inefficient! now we store both a
pointer and a tag. Why can't pointers just be null?
Well actually, that's incorrect. An Option<&T> does not take more space than a single pointer. That's cause the rust compiler
realises that &T has a niche. As I just said, a reference can never be null. Thus, rust stores an Option<&T> just as a &T,
and sets the reference to null when the option is None. As a programmer you can use this Option as normal, but a bit of space
is saved under the hood.
To read more about this, read this and this from the rust documentation
Results
The Result type is like Option. It's part of the standard library, and looks roughly like this:
#![allow(unused)] fn main() { pub enum Result<T, E> { Ok(T), Err(E), } }
With a result, you can represent an operation that could fail. For example:
#![allow(unused)] fn main() { /// Reading a file can fail with one of two reasons here. /// Either it couldn't be opened, or it couldn't be read. pub enum FileError { Open, Read } /// When we read a file, we return either the contents as a String, /// or a FileError. pub fn read_file(path: String) -> Result<String, FileError> { // we first open and see if this succeeded // notice that open() also returns a Result, // so here too we match on Err or Ok match std::fs::File::open(path) { // if not, return an error, inside the Err variant Err(_) => Err(FileError::Open), // if opening worked, we fet an f Ok(mut f) => { // we allocate a string on the heap let mut res = String::new(); // and try to read the contents into it match f.read_to_string(&mut res) { // this may succeed, then we're done // and can return the result in an "Ok" Ok(_) => Ok(res), // if it didn't succeed, we return Err again, but with a different error code (Read) Err(_) => Err(FileError::Read) }; } }; } }
This may immediately look a bit cumbersome. So let me also immediately simplify it a lot!
#![allow(unused)] fn main() { /// This example is the same as below, except that the standard library /// already defined a set of error codes for when you interact with the filesystem /// (since those kinds of operations usually return the same kinds of errors. /// For example, reading, writing or creating files) pub fn read_file(path: String) -> Result<String, std::io::Error> { // see the question mark at the end? That just // means that if open returned an error, immediately // return the function with an error too. That means // that only if the file was opened successfully, we // continue with an open file in `f`. let f = std::fs::File::open(path)?; // now we again create a string to put the result in let mut res = String::new(); // and read. This may again return an error. If so, // we again use the question mark to say that we want // to return the function if the operation fails. f.read_to_string(&mut res)?; // if we get here, all previous operations worked, since // we did not return yet. res } }
And once more without all the comments, so you can see better how concise this is:
#![allow(unused)] fn main() { pub fn read_file(path: String) -> Result<String, std::io::Error> { let f = std::fs::File::open(path)?; let mut res = String::new(); f.read_to_string(&mut res)?; res } }
Actually, you can also use the ? operator to work with options:
#![allow(unused)] fn main() { /// a and b are both maybe an integer. This function returns /// a + b when both a and b are Some. fn add_options(a: Option<i32>, b: Option<i32>) -> Option<i32> { // definitely_a definitely contains an integer, because // if a was None, the question mark makes the function immediately // return None. let definitely_a = a?; // definitely_b is now also definitely an integer let definitely_b = b?; // integers we can add, and then we wrap the whole thing in a Some to // say that the function returns something. Some(a + b) } }
To read more about results and the question mark operator, you can read the chapter from the rust book about it. However, here is a short summary:
- functions that can fail, return a
Result. - A
Resulthas two generic type parameters. The first, is what type the function returns when it succeeds. The right is the type that the function returns when it fails. - If a function returns a
Resultor anOptionthen inside it, you can use the?operator. - The
?operator returns the current function immediately, if it finds anError aNonevalue.
Lab 4: Errors
The code we wrote live:
use std::fs::read_to_string; use std::io; use std::process::exit; use std::num::ParseIntError; use thiserror::Error; #[derive(Debug, Error)] pub enum MainError { #[error("an io error occured: {0}")] IoError(#[from] io::Error), #[error("an divide error occured: {0}")] DivideError(#[from] DivideError), #[error("couldn't parse int: {0}")] ParseIntError(#[from] ParseIntError), #[error("not enough parts on line")] NotEnoughParts } #[derive(Debug, Error)] pub enum DivideError { #[error("divide 1 failed")] FirstFailed, #[error("divide 2 failed")] SecondFailed, } pub fn divide_three(a: u64, b: u64, c: u64) -> Result<u64, DivideError> { let r1 = divide(a, b).ok_or(DivideError::FirstFailed)?; let r2 = divide(r1, c).ok_or(DivideError::SecondFailed)?; Ok(r2) } pub fn divide(a: u64, b: u64) -> Option<u64> { if b == 0 { None } else { Some(a / b) } } fn process_integers(inputs: &[(u64, u64, u64)]) -> Result<Vec<u64>, DivideError> { let mut res = Vec::new(); for &(a, b, c) in inputs { let answer = divide_three(a, b, c); match answer { Ok(i) => res.push(i), Err(e) => { return Err(e); } } } Ok(res) } fn read_and_process() -> Result<(), MainError> { // numbers.csv contains: // 20, 2, 3 // 12, 0, 5 // 58, 3, 0 let contents = read_to_string("src/numbers.csv")?; let mut numbers = Vec::new(); for i in contents.lines() { let mut splitter = i.split(','); let first = splitter.next().ok_or(MainError::NotEnoughParts)?; let second = splitter.next().ok_or(MainError::NotEnoughParts)?; let third = splitter.next().ok_or(MainError::NotEnoughParts)?; let first_int = first.trim().parse()?; let second_int = second.trim().parse()?; let third_int = third.trim().parse()?; numbers.push((first_int, second_int, third_int)); } let res = process_integers(&numbers)?; println!("{res:?}"); Ok(()) } #[test] fn test_right_error() { assert_eq!(Err(DivideError::FirstFailed), process_integers(&[(1, 0, 4)])) } fn main() { if let Err(e) = read_and_process() { eprintln!("{}", e); exit(1); } }
Lecture 5: Traits
Contents
Traits
In Rust, a trait is best explained as a property of a type. Different types have different properties that relate them. In some other programming language, this is known as an "interface" which may be familiar to you.
So what properties are we talking about? Well, one we already saw in lecture 2, called "Clone". If types have the "Clone" property (or as the rust people say: implements the Clone trait), then you can clone values of that type.
Generics
Let's look at an example where these traits are actually useful. Let's say we are creating a function called
get_largest which finds the largest number in a list of numbers:
#![allow(unused)] fn main() { fn get_largest(list: &[i32]) -> i32 { let mut largest = list[0]; for &item in list { if item > largest { largest = item; } } largest } }
Note that this function is specifically made to work on arrays of i32. But the code here is pretty much equivalent to
an implementation for f64:
#![allow(unused)] fn main() { fn get_largest(list: &[f64]) -> f64 { let mut largest = list[0]; for &item in list { if item > largest { largest = item; } } largest } }
And yet, we can't call get_largest with floats:
#![allow(unused)] fn main() { fn get_largest(list: &[i32]) -> i32 { let mut largest = list[0]; for &item in list { if item > largest { largest = item; } } largest } get_largest(&[3.0, 4.0]); }
(note: press the "play" button on the top right of the block above to see the error this produces)
So how can we solve this, without having to copy the code and rewrite the entire function just to have it work for different input types? We can use so-called generic type parameters (or "generics"):
#![allow(unused)] fn main() { fn get_largest<T>(list: &[T]) -> T { let mut largest = list[0]; for &item in list { if item > largest { largest = item; } } largest } }
The <T> syntax means "this function's code depends on a single type that we call T", and afterwards we say that
if the input is an array of Ts, then the output is a single T. But let's think about this code. Does it work for
any type T? Let's think about it. On the first line, we move a value out of the list. That only works by either
.clone()ing, or having a type T that is Copy. Furthermore, on the 4th line, we compare two elements of the list. But
we can't necessarily compare values of any type.
Thus, get_largest will not work for any type T. But the function's definition now says it will. Therefore, the code
above won't compile. For it to compile, we would need to explicitly mark which properties a type must have to work for
this function. What are those properties? One is called Copy. It's a trait that marks values that can move freely. The
other is called PartialOrd, which says that two values are orderable (and thus we can use the > and other comparison
operators on them).
Let's try it:
fn get_largest<T>(list: &[T]) -> T // read as: "where this works for T that are orderable and copyable" where T: PartialOrd + Copy { let mut largest = list[0]; for &item in list { if item > largest { largest = item; } } largest } fn main() { // these all work assert_eq!(get_largest(&[3.0, 4.0]), 4.0); assert_eq!(get_largest(&[3u32, 4u32]), 4u32); assert_eq!(get_largest(&[3u8, 4u8]), 4u8); // but actually, it also works for types you may not have expected // (this finds the alphabetically largest string) assert_eq!(get_largest(&["hello", "world"]), "world"); }
So PartialOrd and "Copy" are traits. Let's look at some more traits:
Built-in Traits
| trait | property: |
|---|---|
Eq and PartialEq | A type is comparable to others of the same type with == and != |
Ord and PartialOrd | A type is comparable to others of the same type with > and < and >= and <= |
Copy and Clone | A value of the type can be duplicated (implicitly and explicitly respectively) |
Debug | A value has a debug representation to print it (usually shows the structure of the type). This allows you to write println!("{:?}", v) |
Display | A value has pretty representation to print it. This allows you to write println!("{}", v) |
From and Into | A value of the type can be converted into (or from) a value of another type |
Hash | A value of this type can be hashed |
Iterator | A value of this type can be iterated over. This also means a value of this type can be used in a for loop. |
Add, Sub, etc | A value can be added/subtracted/etc to other values of the same type. This is like operator overloading. |
Note that some traits imply other traits. For example, a type can only be Copy if it's also already Clone. And
a type can only be Ord of it's also already Eq, otherwise operators like >= can't work.
Partial{Ord, Eq} vs {Ord, Eq}:
You may have seen that some traits have a "Partial" version. So what's the difference? Simply said, the Partial version has fewer requirements than the non-partial version.
For example: for types that are
PartialEq, an==check needs to be:
- symmetric:
a == bimpliesb == a- transitive:
a == bandb == cimpliesa == c.While types that are Eq, also need to make sure that equality checks are reflexive:
a == a. This excludes floating point numbers, sincef64::NAN != f64NAN.A similar story applies to PartialOrd vs Ord.
Custom traits
Traits are not just something that's built into the compiler. Let's look at an example:
#![allow(unused)] fn main() { struct Rectangle { width: f64, height: f64, } struct Circle { radius: f64, } }
Both of these structs are shapes. They may have some common functionality. For example, you may want to find the area of both of them. In such a case, defining this functionality as a trait is a good choice:
// if types have the "Shape" property ... trait Shape { // ... then they *must* provide an implementation for this associated function fn area(&self) -> f64; } // for example: impl Shape for Rectangle { // we *have* to provide this, with the exact same signature as // given in the trait fn area(&self) -> f64 { self.width * self.height } } impl Shape for Circle { fn area(&self) -> f64 { // the signature needs to be the same, but the // internals do not. self.radius * self.radius * std::f64::consts::PI } } fn main() { let a = Rectangle {width: 20.0, height: 30.0}; // we can now use this function on both Rectangles *and* Circles assert_eq!(a.area(), 600.0); print_area(Circle{radius: 10.0}); } // and we could make a function that prints the area of both: // the T: Shape is a shorthand to say that T needs to implement Shape. fn print_area<T: Shape>(s: T) { println!("{}", s.area()) }
Generic Traits (bonus!)
This part is just an interesting aside. You don't necessarily need it to understand the assignments. But actually, structs and traits can also be generic over types. So you could define shapes to work on any number. I'm just going to give one big (and quite advanced) example:
use std::ops::Mul; // generic over a T. Could be any type struct Rectangle<T> { width: T, height: T, } struct Circle<T> { radius: T, } // shapes are also generic trait Shape<T> { fn area(&self) -> T; } impl<T, Res> Shape<Res> for Rectangle<T> // To be a shape, the T in the shape needs to multipliable where T: Mul<T, Output=Res> + Copy { fn area(&self) -> Res { // returns whatever the output of multiplying may be self.width * self.height } } // here we say the output is *always* an f64, // since circles won't have nice integer areas. impl<T> Shape<f64> for Circle<T> // To be a shape, the T in the shape needs to multipliable where // T needs to be multipliable T: Mul<T> + Copy, // and if we were to multiply T with itself, it's output needs // to be convertable into an f64, since we use a pi constant from // f64s <T as Mul<T>>::Output: Into<f64> { fn area(&self) -> f64 { (self.radius * self.radius).into() * std::f64::consts::PI } } fn main() { // these both work let a = Rectangle {width: 20.0, height: 30.0}; let b = Rectangle {width: 20u32, height: 30u32}; assert_eq!(a.area(), 600.0); assert_eq!(b.area(), 600u32); // as does this: let c = Circle{radius: 40u32}; // assert that there's a fractional part. We did end up with a float. assert_ne!(c.area().fract(), 0.0) }
impl Trait shorthand
When we previously defined a function that takes value of any type that implement a trait, we wrote something like this:
#![allow(unused)] fn main() { fn print_area<T: Shape>(s: T) { println!("{}", s.area()) } }
However, there's a nice shorthand that's usually easier to read:
#![allow(unused)] fn main() { fn print_area(s: impl Shape) { println!("{}", s.area()) } }
Using a generic is equivalent to "impl Trait" shorthand (note: only if used in parameter position. In return position they're not at all equivalent to generics, even though you can use impl Trait for return values just fine).
Note however, that function 1 and 2 here are not at all equivalent. 1 and 3 are equivalent:
#![allow(unused)] fn main() { // a and b can be different types that both implement Shape individually. // they can be the same, but don't need to be fn print_area_1(a: impl Shape, b: impl Shape) { println!("{}", s.area()) } // a and b must be the same concrete type, and need to implement Shape fn print_area_2<T: Shape>(a: T, b: T) { println!("{}", s.area()) } // this is the equivalent code to print_area_1 fn print_area_3<T: Shape, U: Shape>(a: T, b: U) { println!("{}", s.area()) } }
Lifetimes
Lifetimes will be discussed live in the lecture. For more information, I direct you to the lab and the official rust book.
Lecture 6: Collections and Iterators
Contents
Collections
Built into the Rust standard library, is a module called "collections". In it, there are a number of commonly used
datastructures. One of those is the Vec, which we have seen before. In this lecture, we will also look at
HashMap and HashSet, two datastructures you might find useful.
If you prefer listening or watching a more concise lecture about this topic, we highly recommend the video by Jon Gjengset about this topic.
Hashmap
A HashMap is a data structure that works a bit like a database.
Elements in a HashMap always have some kind of key, together with an associated item.
For example, in a database of students, the key might be your student ID and the value is the information associated with that student ID.
Let's imagine we are designing our own HashMap of keys and values. We might imagine a vector of tuples:
struct Student { name: &'static str, average_grade: f64, } fn main() { let mut v = Vec::new(); v.push((1, Student {name: "Sarah", average_grade: 7.6})); v.push((12, Student {name: "Tim", average_grade: 8.2})); v.push((34, Student {name: "Josh", average_grade: 5.9})); v.push((42, Student {name: "Cat", average_grade: 9.1})); }
The type of each pair is (i32, Student) here.
Let's say that we would like to find the student with ID 42.
To do that, we can simply iterate over all students until we find Cat.
#![allow(unused)] fn main() { // find a value for a specific key println!("{}", v.iter().find(|(k, _)| k == 42)); // prints: Some(Student {name: "Cat", ..}) }
In this case the list of students is not too long, so finding the student with ID 42 won't take too long. But the longer the list becomes, the slower it is to find specific students. Unless we are lucky of course. If we had wanted to find the student with ID 1 in this example, it would be very quick since Sarah happens to be the first student in our list!
We call an operation that, like this one, becomes slower the more items we add: O(n).
That notation essentially says that the time it takes grows like a linear function.
So can we do better? What if we knew that all the keys are numbers between 0 and 100. We could create an array of 100 elements like this:
#[derive(Copy, Clone)] struct Student { name: &'static str, average_grade: f64, } fn main() { let mut v = [None; 100]; v[1] = Student {name: "Sarah", average_grade: 7.6}; v[12] = Student {name: "Tim", average_grade: 8.2}; v[34] = Student {name: "Josh", average_grade: 5.9}; v[42] = Student {name: "Cat", average_grade: 9.1}; // find the value of a key: println!("{}", v[14]); // None println!("{}", v[42]); // Some(Student {name: "Cat", ..}) }
On the last line here, we attempted to find a student with ID 42 and instantly found Cat, since their information was stored at index 42.
To find that, we did not actually need to search through the array, so the operation becomes what we call constant time or O(1).
The speed of this lookup does not at all depend on how many students we store, as long as we know the ID of the student we are looking for.
Notice here, that we can only have a single student with an ID. There's only a single place for every ID, so when we add a second student with an ID that was already in use, the second student would overwrite the first.
The instant-lookup trick with arrays only works when our keys are integers. Let's say we want to find people by their name, we cannot make an array where we can use strings to index it. Furthermore, if we don't know a maximum value for these integers, we might need to allocate enormous amounts of memory so that is infeasible as well.
That, is what a HashMap is. It's like an array, that can do these instant-lookups by their key, but unlike the array example it works for almost any key imaginable. Let's look at the example below. Here we indeed use student's names as a key, not their student number.
use std::collections::HashMap; #[derive(Copy, Clone)] struct Student { student_id: u64, average_grade: f64, } fn main() { let mut v = HashMap::new(); v.insert("Sarah", Student { student_id: 1, average_grade: 7.6 }); v.insert("Tim", Student { student_id: 12, average_grade: 8.2 }); v.insert("Josh", Student { student_id: 34, average_grade: 5.9 }); v.insert("Cat", Student { student_id: 42, average_grade: 9.1 }); v.get("Cat") // Some(Student {student_id: 42, ..}) }
The code looks pretty similar to the original Vec example, but now using get instead of indexing.
With a HashMap, on average, it always takes the same amount of time, regardless of the size of the hashmap to find items.
Do note, that HashMaps do not have a defined order.
Because of how arbitrary keys are turned into indices in an array (which we call hashing)
Let's look at another example where HashMap is useful: counting occurrences of words.
Let's say we have a large text, like this assignment, and we are interested in how many times each word is used.
We expect to find words like 'the' and 'and' and 'a' to be very frequent.
Let's use this as our setup:
fn find_occurences(data: &str) { // split on words for word in data.split(' ') { } } fn main() { let words = include_str!("lecture-5-iterators.md"); find_occurences(words); }
At this point, first think about how you would do this while using a `HashMap` without reading ahead, where will show the solution. To go ahead, open the tab below.
fn find_occurences(data: &str) { let counter = HashMap::new(); // split on words for word in data.split(' ') { if counter.contains_key(word) { // if the word was seen before, add 1 *counter.get_mut(word) += 1; } else { // if the word wasn't seen before, now we've seen it once counter.insert(word, 1); } } println!("{}", counter); } fn main() { let words = include_str!("lecture-5-iterators.md"); find_occurences(words); }
Other operations on a hashmap are for example: contains_key (gives a boolean saying whether a key is present)
and remove (deletes a key-value pair by its key). For more information, see
the standard library.
HashSet
A HashSet is in many ways similar to a HashMap.
You can think of a HashSet like a HashMap with no values, only keys.
You might think that such a data structure is absolutely useless.
However, that's not at all true, because of two properties HashMap and therefore also HashSet has.
- A
HashMap/HashSetcannot contain duplicate elements - You can see if a
HashMap/HashSetcontains an element in constant time.
A HashSet can therefore be useful to for example find if there are duplicates in a list of items, like this:
#![allow(unused)] fn main() { fn has_duplicates(elems: &[u64]) -> bool { // make a hashset let res = HashSet::new(); // put all elements in for i in elems { // notice: this is a set so we don't give a value res.insert(i); } // if an element in `elems` was already seen before, it will overwrite // go at the same location as the previous occurence in the HashSet // thus, the total length of the set will be smaller than the length of `elems` res.len() < elems.len() } }
You can use a very similar program to find "items you have seen previously". You put every item you see in the Set and then when you notice it overwrites another element you found your first duplicate.
Iterators
The different collections in Rust, all have a method called .iter(). This method, returns
an iterator. But what is an iterator?
Simply put, an iterator is any value that may have some kind of next value.
For example, you can turn a Vec into an iterator (through iter()) and go from one item to another:
fn main() { // a collection of items let items = vec![1, 2, 3, 4, 5]; // make an iterator let mut iterator = items.iter(); assert_eq!(iterator.next(), Some(&1)); assert_eq!(iterator.next(), Some(&2)); assert_eq!(iterator.next(), Some(&3)); assert_eq!(iterator.next(), Some(&4)); assert_eq!(iterator.next(), Some(&5)); // when there are no more elements, return None assert_eq!(iterator.next(), None); }
Notice that Vec is not an iterator itself. We can create an iterator that iterates over a Vec,
but Vec does not have this property of having a next item on its own.
When we create an iterator over a Vec, we essentially start by pointing to the first element.
Every time we call next, we advance to the next item, and at some point next may return None signalling that there is no next item.
At this point, you may notice that this is not the only possible iterator over a Vec.
Indeed, you could also write:
fn main() { // a collection of items let items = vec![1, 2, 3, 4, 5]; // make an iterator let mut iterator = items.iter().rev(); assert_eq!(iterator.next(), Some(&5)); assert_eq!(iterator.next(), Some(&4)); assert_eq!(iterator.next(), Some(&3)); }
To iterate over the Vec in reverse, from the end to the start.
For loops
In many languages, a for loop is an abstraction over simpler loop kinds to iterate a specific number of times. Although this is technically true in Rust too, it might be more accurate to see a for loop as an abstraction over "finishing an iterator". A for loop has to ability to take any iterator, and repeat a block of code until the iterator is exhausted.
Let's take the vec example again from above
fn main() { // a collection of items let items = vec![1, 2, 3, 4, 5]; // make an iterator let iterator = items.iter(); // run the iterator until the end for i in iterator { println!("{}", i); } }
The for loop takes the iterator, and prints every element until the end, where the end is marked by the iterator returning None.
Because this is an abstraction, we can look at what the more primitive while-loop version of this code looks like to understand better what is going on:
fn main() { // a collection of items let items = vec![1, 2, 3, 4, 5]; // make an iterator let iterator = items.iter(); // run the iterator until the end let mut temp = iterator.next(); while temp != None { // can't fail because we just looked it's not None let i = temp.unwrap(); // original code in the for loop println!("{}", i); // advance the iterator temp = iterator.next(); } }
So what can we learn from this? One thing is that the for loop you have most likely used most:
#![allow(unused)] fn main() { for i in 0..10 {} }
probably also has something to do with iterators. And indeed, it does.
The expression 0..10 is actually an iterator.
It starts at 0, then every time you call next on it, it advances.
Until, after 9 it returns None
fn main(){ let mut range = 0..10; assert_eq!(range.next(), Some(0)); assert_eq!(range.next(), Some(1)); assert_eq!(range.next(), Some(2)); assert_eq!(range.next(), Some(3)); }
Infinite Iterators
The definition of an iterator is very simple.
It's anything that has the notion of a next element.
Although an iterator can stop whenever it returns None, nothing says that it has to.
An iterator that simply never returns None is an infinite iterator, and that's perfectly okay.
You could for example write:
fn main() { for i in std::iter::repeat(1) { println!("{i}"); } }
Which will infinitely print the number 1. For any arbitrary iterator, you can also make it infinite by cycling it:
fn main() { for i in vec![1, 2, 3].iter().cycle() { println!("{i}"); } }
Which will print the numbers 1, 2, 3 and then 1 again, forever.
cycle() is a method available on any iterator, and these methods are often called adapters
Adapters
Adapters are functions on iterators, that can turn an iterator into something else.
Let's look at an example of another adapter: map().
With map(), we can transform one type of iterator into another.
For example, the following code transforms an iterator over integers, into one of floats which are twice as small as the integer:
fn main() { let data = vec![1, 2, 3, 4]; for i in data .into_iter() .map(|i| i as f64 / 2.0) { // prints 0.5; 1.0; 1.5; 2.0 println!("{i}"); } }
Sometimes, an adapter can also change the length of an iterator.
For example, take() will stop the iterator after a number of elements have passed.
fn main() { let data = vec![1, 2, 3, 4]; for i in data .into_iter() .take(2) { // prints 1; 2; println!("{i}"); } }
The most important ones are:
.collect(): Turns an iterator into a datastructure (like a vec), consuming all the items in the iterator..map(|x| some_op(x)): Transforms all elements of an iterator by applying the function..filter(|x| some_predicate(x)): Only keeps the elements in the iterator that satisfy the predicate..find(|x| some_predicate(x)): Returns the first item that satisfies the predicate (transforms an iterator into a single value)..take(n): Returns a new iterator which is at most n elements long..position(|x| some_predicate(x)): Returns the index of the first element that satisfies the predicate..nth(n): Returns the nth element in the iterator (like indexing). Note that.nth(n)will advance the iterator. Running.nth(n)twice won't yield the same element twice.
You can find more methods in the rust documentation.
The following is called a closure:
#![allow(unused)] fn main() { |a, b, ..., z | { } }A closure is a way quickly make a function that you can use as an expression. For example, to use as a parameter to another function. The parameters are put within vertical bars (|), and then a block or expression follows with the function body.
A closure can use variables defined in an enclosing scope.
Many methods on iterators are "lazy". For example, if you run .map() on an iterator, you're not actually mapping every
element right there. Instead, the calculation is stored, and only performed for items that you're actually using in the
program (for example, when you collect to put all items in a collection).
For example:
#![allow(unused)] fn main() { // make a very long vec let mut v = Vec::new(); for i in 0..10000 { v.push(i); } // iterate over the vec let res: Vec<_> = v.into_iter() // only keep items divisible by 3 .filter(|x| *x % 3 == 0) // multiply all of those items by 2 .map(|x| x * 2) // take only the first 20 items .take(20) // put those in a vector .collect(); println!("{:?}", res); }
In this example, an eager system would first apply 10 000 filter operations, and then roughly 3333 map operations, only to throw almost everything away (we only need 20 items). But because iterators are lazy, the map function actually only runs 20 times. We only need 20 items. The filter function will run a bit more often (some items are discarded). But still only 60 times. That saves a lot of computation.
In fact, this lazy evaluation is what allows iterators to be infinite.
It is perfectly fine to have an iterator over an infinite number of elements, as long as you don't keep all infinity of them in memory, but simply generate the next() one every time.
#![allow(unused)] fn main() { let res = // create an iterator over all numbers from one to infinity // So this iterator is technically infinitely long. It just means // it will never return "None" when .next() is called. (1..) // multiply them all by 2 (this creates the even numbers) .map(|i| i * 2) // finds the first number that's divisible by 21 .find(|i| i % 21 == 0); // 42 is the first even number divisible by 21 assert_eq!(res, Some(42)); }
Lecture 7: Testing:
If you are interested in reading a book about this topic, we highly recommend this one by one of our own professors from the TU Delft, Mauricio Finavaro Aniche: https://www.effective-software-testing.com/. Some of this lecture has been inspired by it.
Simple Tests
A very simple technique to see if software works as it is supposed to, is to provide it with inputs and see if the outputs match your expectation. You might find yourself doing this manually, going through some inputs you know and printing the output. Although this works for small programs, for larger programs there may be many different inputs you might want to test. Furthermore, every time you change a complex program you really should ideally retest all inputs to see if you haven't broken anything.
A more sustainable way to test software is through automated testing.
Writing automatic tests in Rust is quite easy, although it may take you a little longer to write one than manually trying an input.
Usually, it simply boils down to writing a function with the #[test] annotation on it, and calling the function with your input(s).
#![allow(unused)] fn main() { fn fibonacci(n: u64) -> u64 { match n { 0 => 0, 1 => 1, n => fibonacci(n - 1) * fibonacci(n - 2) } } #[test] fn test_fibonacci() { assert_eq!(fibonacci(0), 0); } }
Whenever cargo test is run in the root of a project, all functions marked with #[test] in that project are ran.
Now you can keep these test cases around, such that every time you change your code, you can re-run cargo test to verify that everything is still working as expected.
As you can see in the example above, we use assert_eq! to test the input and output of fibonacci.
This is an assertion.
An assertion is a statement about your code, which you expect to pass.
By making the right assertions, bad code will cause one or more of your assertions to fail, which you can observe.
In Rust, there are three kinds of assertions built-in:
assert!(e)checking ife`` evaluates totrue`.assert_eq!(a, b)checking ifais equal tob, it is similar toassert!(a == b), but shorter and better output.assert_ne!(a, b)checking ifais not equal tob.
Other kinds of assertions can be constructed out of these simple ones, you can for example give assert!() more complex expressions.
Rust's assertions optionally support messages, for example:
#![allow(unused)] fn main() { assert!(a.is_ok(), "a was not ok, and instead was {}", a.unwrap_err()); }would give a nice error message with the exact error
awas wheneverawas not ok.
Cool! However, the test we just wrote did not catch the bug in our fibonacci program. We should have added the to recursive cases, not multiplied! We only tested one of our base cases, so we did not catch this.
That brings us to an important question: how many tests should we make to be sure that our program works as expected?
For the fibonacci code you might say that the answer is 3. One for each base case and some test that shows that the recursive case is correct.
#![allow(unused)] fn main() { fn fibonacci(n: u64) -> u64 { match n { 0 => 0, 1 => 1, 42 => 42, n => fibonacci(n - 1) + fibonacci(n - 2) } } }
But with those three tests, you would not find the bug in the snippet of code above.
You may show that the base cases and the recursive cases are correct, but you most likely didn't test whether the right output was given for n=42.
Thus the real answer to that question, how many tests we should make, is simple (but unsattisfying): you can't know. A very important rule in software testing is, as uttered by Dijkstra, "Testing can be used to show the presence of bugs, but never to show their absence". Still, testing can be very useful to improve your confidence about your code's correctness, and our confidence might increase as we test more of it.
Besides normal assertions, Rust also supports debug assertions. Those seem like the normal ones, but start with
debuglikedebug_assert_eq!(a, b). These kinds of assertions get triggered when you compile in debug mode (which is whatcargo rundoes by default), but when you compile in release mode, with all optimisations turned on, as withcargo run --releasethese assertions will not be checked. This is useful when you put assertions in the middle of your normal code, and you don't want your code to crash when running in production.
Coverage
So how do we make sure we test all of our code?
One possibility is to use tools such as tarpaulin or llvm-cov, which both perform a very similar task: generating coverage reports.
With code coverage tools we can measure which parts of a program get executed by our tests, which can help show us what tests we still have left to write.
How that works, is that the compiler will, together with these special tools, insert a special function call after every single line of code in your program telling the coverage tool that that line is executed. The code below illustrates that, though many details are omitted:
#![allow(unused)] fn main() { fn fibonacci(n: u64) -> u64 { cov(2); match n { 0 => {cov(3); 0}, 1 => {cov(4); 1}, n => {cov(5); fibonacci(n - 1) + fibonacci(n - 2)} } } // called when a certain line is covered fn cov(line: usize) {todo!()} }
Note that this may make your code slightly slower, since these extra function calls do have overhead.
Let's use tarpaulin as an example. With the above code in a project, we can simply run cargo tarpaulin -o html and after some running the tool will generate an html file called tarpaulin-report.html which will look like the example below (note that you can click on it! may work better with light theme):
Types of Coverage
Cargo tarpaulin shows us which lines in our program are and aren't executed. We call this line coverage. Although useful, don't make the mistake of thinking that when all lines are covered by your testcases, there are no bugs left in your program. When a line of code is reachable in multiple ways, for example by one of several conditions being true, and you only test one such path, any of the other paths may still be incorrect.
There are different metrics we can use for coverage. For example, cargo llvm-cov supports region coverage.
A single code region may contain multiple regions, for example in boolean expressions a > 3 || b < 5 would be two regions.
One step stronger still is branch coverage.
The previous example contains 2 regions, but 4 possible branches: a > 3, a <= 3, b < 5 and b >= 5.
Under branch coverage, a test needs to verify each of these.
Unfortunately, branch coverage is not very well supported in Rust yet.
And still, even with these stronger types of coverage, you have to remember that with 100% coverage there can still be bugs!
Types of Tests
When we test code, there are different kinds of tests of different granularity, which have commonly used names.
- Unit Tests: A test of a single isolated part of a program (unit) like a single function.
- Integration Test: A test of various systems together to see whether they work together correctly.
- End-to-End/System test: A test of the entire system, from start to finish. Usually the last thing you do.
- Smoke Test: Often the very first test you make to just see if one very common usage of your program doesn't completely crash. Useful while you start writing a program before you do proper testing to simply see if you haven't done something very stupid.
These kinds of tests have different granularity, and are useful for different purposes. When an integration test or end to end test fails, it might not be obvious what the reason of the failure is, it could be anywhere in the system. With a unit test you can make sure that each basic component works correctly. Once you are sure that that is the case, you can work your way up to integration tests and end to end tests to see if more and more of a system is correct.
Test Driven Development
Up to now, we have assumed that we write tests after we wrote software, to see if the software we wrote first is actually correct. However, that does not always have to be the order. When a bug is found in a large or complicated project, it can be hard to find what exactly causes it. In that case it can be helpful to first create a test that reliably triggers the bug and fails. Then, it becomes very clear what has to be done to fix the bug: make the test pass. We call this test driven development, where we write the test first for the software that still has to come.
In Rust, we sometimes use a derived term: compiler driven development. That's when we use the compiler to help us write software. We start with wrong software and keep following compiler error messages until the code compiles, and more often than not is also correct!
Splitting up files
It's often useful to split your code into several parts to give a logical structure to the program.
In Rust, this is done with the mod keyword.
With mod, we can declare that a certain module exists, and this can be done right in the middle of a program.
fn main() { a::x(); b::y(); } mod a { pub fn x() {} } mod b { pub fn y() {} }
Note that I had to make x and y public. Visibility (like public and private) works on a module level in Rust.
Modules are also the way to link different files together. Let's say I have a file structure like this:
Cargo.toml
src/
main.rs
a.rs
b.rs
Then I can link these files together using mod statements:
mod a; mod b; fn main() { a::x(); // assuming a has a public x function b::y(); // assuming b has a public y function }
It is also possible to use directories to represent modules. One file in that directory then has to be called mod.rs to represent the root of that module. The file structure might look like this:
Cargo.toml
src/
c/
a.rs
b.rs
mod.rs
main.rs
a.rs and b.rs would contain public functions, mod.rs would look like this:
#![allow(unused)] fn main() { pub mod a; pub mod b; }
to declare that there are two modules in the c/ directory. Because we want to import a and b, through c from main.rs I have to say that a and b are public. main.rs now looks like this:
mod c; fn main() { c::a::x(); c::b::y(); }
Linking between files
As you can see, the paths to refer to items in modules can become pretty long.
c::a::x() may become cumbersome.
To reduce the effort, there is also the use statement. mod and use together form what other languages might call import. mod makes modules available, and use can bring them into scope. For example, main.rs in the previous example could have looked like this:
mod c; use c::a::x; use c::b::y; fn main() { x(); y(); }
Alternatively, if we had put this in mod.rs:
#![allow(unused)] fn main() { pub mod a; pub mod b; pub use a::x; pub use b::y; }
Then our main.rs code would be as short as
mod c; // because we used 'pub use` these are now directly // available from c. use c::{a, b}; fn main() { x(); y(); }
You can play with this, making modules private but publically useing items from them to make specific parts of your program available.
Lecture slides (2025-2026)
Lecture 1: Intro to Rust
Lecture 2: Data Type
Lecture 3: Ownership and References
Lecture 4-1: Validity
Lecture 4-2: Enum
Lecture 5: Traits and Generics.
You can also access the accompanying exercises.
Lecture slides (2024-2025)
Recordings of the lectures are also available on Collegerama
Lecture 1: Intro to Rust
Lecture 2: Data Type.
Lecture 3: Ownership and References.
Lecture 4: Enums and Errors
Lecture 5: Traits and Generics
Lecture 6: Iterators and Collections
Lecture 7: Testing and Tooling
Lab Slides
Git Assignment
This set of exercises aims to help you getting started with Git. Git is the Version Control System we use in this course. Git is very popular, it is used by many companies in the industry, so knowing how to work with it will be an important skill to master.
Git will allow you to work on the source code of your software system collaboratively, and it will keep track of your changed through history. It can be used for big teams, small teams, and even by individuals.
As we use Git to gain insights into the groups’ progress later in this course and other courses, it is important that you make sure to configure Git as explained in the first section of this manual. When you already know how to work with Git then you are free to skip the parts that are already known to you.
Make sure to complete the final assignment at the end of this manual before Sunday, week 1 (10 Sept).
In case you have questions you can ask your peers for help, or you can ask a TA.
Git takes some time to get used to, it may look complex at first, but once you get familiar with the terminology it should be much easier to work with. Don’t hesitate to ask for help when you get stuck, it’s better to ask in the first weeks than halfway into the project.
Good luck!
Disclaimer
A lot of time was spent on the correctness of this assignment, but it could be that we have missed something.
In case you encounter a problem then please report this to us at softw-fund-ewi@tudelft.nl.
These assignments are adapted by Jonathan Dönszelmann, and based on an assignment from the CSE bachelor's program.
Original Authors Sander van den Oever, Sebastian Proksch, Yoshi van den Akker, Denise Toledo and Ana Băltăreţu,
Assignment Information
How to hand in your assignment?
To complete this assignment you have to complete all tasks marked in the "assignment" boxes on the following pages. You do not need to upload anything to Brightspace; just make sure your changes have been uploaded (pushed) to our GitLab server and then a TA will be able to check that you've completed the assignment.
Note that some pages are collapsed in the sidebar. To go to the next page, you can press the right arrow on the side of the page.
Some things we discuss here will assume you use gitlab. That's because we run our own instance at EEMCS. However, another popular git provider is GitHub. In fact, for different courses you might use Github and when you use git for yourself, you'll likely use GitHub as well. Almost everything said in this assignment also applies to GitHub.
Starting the assignment
To start the assignment, you will need to get an account on gitlab, where we give you a template repository for the assignment. For that, you need to create an account on the internal EWI gitlab. This account is also necessary for other assignments in this course, such as the final project.
- Login at GitLab through Single Sign On. Do this as soon as possible!
- Once you did this, we will add your account to some gitlab repositories in the first week of the course. If possible, on the same day you create your account.
- Do not change account details such as your email address and/or username please.
- These are used for automated checks by course staff.
- Setting a profile picture is fine, as is filling in other profile fields.
- Ensure you are using the correct URL: e.g. https://gitlab.ewi.tudelft.nl and not something like https://gitlab.tudelft.nl (which, confusingly, exists as well, but is not linked to EEMCS' GitLab)
- Never enter a password for user
git@gitlab.ewi.tudelft.nl, there's no correct password, and you'll get yourself banned when you try a couple of times! - The server has a pretty tight firewall, therefore:
- Upon failed connections, do not immediately retry without verifying your setup.
- In the event that you tried too many times you'll be banned from the server automatically. The first two times you'll be banned automatically for 1 hour. When you reach the banlist for the third (or more) time then you'll be banned permanently.
- When you ended up in the server's banlist, you can request to be unbanned by the EIP team.
Send an email to
eip-ewi@tudelft.nl, mentioning that you want to be unbanned from GitLab, and include your public IP address (find it using whatsmyip.org for example).
Install & Configure Git
When Git is not installed on your system yet then you can follow the steps from Git’s website to install it. For later parts of this course, we recommend you use linux.
You can check whether Git is installed by running the following command on your terminal:
git --version
This should print something like
git version 2.37.2
There are multiple ways to use Git. For instance, you can use your terminal (entering raw commands), you can use a GUI (in case you prefer pushing buttons instead of typing commands) or your editor (e.g., IntelliJ, Eclipse, etc.) may include Git support.
In this manual we will focus on interacting with git through the terminal. We will always mention the equivalent terminal commands in case you prefer to work with the terminal. The most important thing is to get familiar with the terms, and how to perform the basic operations in Git.
We strongly discourage you to use SourceTree, a git GUI. This GUI doesn't handle authentication errors properly, and will just try again and again until your IP gets banned.
Configuring Git on your system
Submitting your code on GitLab has been restricted to only accept code that is authored by students. The platform will automatically check whether the email
address ends with @student.tudelft.nl.
Therefore, you need to instruct Git what name and email address to associate with your work. You can configure this on a global and a per project level.
Run the following commands to set your git email address globally. It's safest to set it globally, but especially if you already use a personal email address for other git repositories, you can simply remove the
--globalfrom the commands below, and running the command inside the repository you want to change the settings for.git config --global user.name "Your full name" git config --global user.email "Your student email" # This one is just very convenient git config --global push.autoSetupRemote trueTo check whether the commands were successful, you can run;
git config --global user.name git config --global user.emailThis should output whatever you configured using the commands above. Make sure that the configured email address ends with @student.tudelft.nl!
You should now have everything set to get started with git. We will walk you through the entire flow, an overview is given below (highlighted are the Git terms you should know);
- Creating / configuring your SSH keys
- Downloading an existing project (cloning a remote repository)
- Storing your (selected) changes on Git and undoing this (staging, committing and reverting to a local repository)
- Sync your commits to GitLab (pushing to the remote repository)
- Working on an isolated feature/task (starting/switching a branch)
- Combining your feature/task with the “live” version of the system (merging a branch)
- What to do when automatic merging fails (merge conflicts)
- Sync changes from the remote in your local repository (fetching, pulling from remote repository)
- Perform a full workflow to fix a problem
- Additional git features (rebasing, cherry picking, force pushing, stashing, tagging, etc.)
Set up SSH Keys
SSH keys are a way to authenticate yourself to another party (for example a service like GitLab). They replace the need for the usual username/password authentication. You'll learn more about this once you follow a course on Security and Cryptography. For now, you should only remember that SSH keys consist of a private part and a public part. As the name suggests you should never share the private part of your key. That's roughly equivalent to giving someone your password. The public part of your key is meant to be shared with other parties. Using the public part of the key anyone can send secure messages your way. Only when you have the private key then you can see the contents of these messages. In the following steps you'll create your private and public keys (your keypair) and you'll upload the public part of your key to GitLab so that GitLab will be able to authenticate you.
Creating your SSH key
When you first open your new GitLab account, it will give you a notification that you have not set up an SSH key yet. To make cloning easier we will start off by creating a SSH key. GitLab has an easy to follow tutorial on both creating the key. Note that in the tutorial you come across a step where you can set a passphrase for your (private) key. It's not required to do so. When you set a phrase, then make sure to remember it, as you'll be asked for the phrase every time you want to load/use your key. When you set no passphrase then you should ensure that nobody can access the private key file on your device (use a strong password to login and don't leave your device unlocked/unattended).
Uploading your public key to GitLab
The tutorial on GitLab also contains a part on adding your public key to your GitLab account. When you've completed all steps your private key is now allowed to access the GitLab instance.
Test your connection
By default your .ssh folder inside your home directory is checked for SSH keys. As long as they use default names, like id_rsa, id_ed25519, etc. then they should be picked up automatically. When you use a different name then you should either load your key manually (using your ssh-agent) or by editting your SSH configuration file (~/.ssh/config). When this is necessary we recommend the latter option. Create (or edit) the file ~/.ssh/config and add the following block;
Host gitlab-eemcs
HostName gitlab.ewi.tudelft.nl
IdentityFile ~/.ssh/id_custom_key
Change ~/.ssh/id_custom_key to the actual path to your desired private key (remember that the public counterpart should be uploaded in your GitLab account). You can also use this file to use different keys for different servers.
To check whether you can successfully connect to GitLab, you can run the following command;
ssh -T git@gitlab.ewi.tudelft.nl
This will ask if you want to continue connecting; enter yes and, if everything works correctly, it should output something like Welcome to GitLab, @[username]! and exit.
Uploading work
The three most important git operations are
We will now go into these seperately.
The clone operation
There are two ways to get a repository on your computer. By creating a new one locally (also called initialisation of a repository). Or, alternatively, you can download an existing repository from a platform like GitLab, GitHub, or similar (this is called “cloning” a project). In our course we use our self-hosted GitLab instance, located at gitlab.ewi.tudelft.nl.
As this course will provide you with a template to start working from, we will explain the case where you download an existing project to your machine.
Always use TU Delft's Single Sign On (NetID login) to authenticate yourself to GitLab and do not change the username (your NetID) and/or your primary email address (your student email). Those are used to generate reports about your performance in our course.
There is also a GitLab instance located at
gitlab.tudelft.nl. These instances are not linked in any way. You should only use the instance of our faculty.
Finding the URL of the project
To clone a project we need to have the URL of the repository. To get this we will first go to the project in the web interface of
GitLab by clicking on Projects > Your projects in the top left corner in GitLab, now select your personal git assignment repository.
The name of this repository contains your NetID in the name. Click on the blue “Code” button in the top-right corner and copy the
“Clone with SSH” URL (starts with git@…, not https://).
Cloning using the https URL is also possible, but this will trigger a prompt where you have to enter a username and password. This way of authentication is likely to be deprecated in the near future, less secure and is less convenient (you have to type your password). Therefore, we recommend you already get familiar with cloning over SSH.
Cloning a repository
Now that we have the URL we need to clone the repository on our machine. This can be done in the following way;
Navigate to the folder where you'd like to store the projects' files and run the following command;
git clone <URL>You can paste a URL into the terminal using ⌘V (OSX), Ctrl+Insert (Windows) or Crtl+Shift+V (Linux).
Assignment
Clone your individual git repository to your local machine.
Common errors
Here you can find some of the most common errors that your peers have encountered in the past year(s).
You are prompted for git@gitlab.ewi.tudelft.nl's password
Something in your SSH key setup is not working as expected. Please check whether your SSH agent is running (you may need to restart it manually upon reboot of your device), and that your SSH key is loaded into the agent.
Do not enter any password. You don't have the correct password, and performing too many attempts here will get your IP banned from our GitLab server.
Sharing changes on git
Now that the setup is complete it is finally time to work with Git. As stated before, git is a tool for version control and collaboration. Git works by storing the changes that have been made to your files. In the practice repository you will be able to find a document called README.md. We are going to work with this document to practise.
Assignment
First open the
README.mddocument in your preferred editor (a plain text editor or IDE). Read the document and make a change of a few lines. Once you're done, save the changes and go back to the terminal to store the changes you made.
Staging
Saving changes on git is done in two steps, the first step is to select which changes need to be stored. This is called staging. Afterwards we actually store the changes by committing.
To see which files are staged run the command;
git statusThe red files are not staged, the green files are staged. To see the changes of the files you can run the commands;
git diff [file] git diff --staged [file]To stage or unstage changes you can respectively use the commands;
git add <file> git restore --staged <file>for partial commits you can add the -p flag to the add command.
Assignment
Stage the changes you made in the
README.mdfile.
Committing
The second step of storing changes is called committing. This step can be seen as boxing all the changes that you have made and labelling them with a message which is called the commit message. This message is to make sure that you, your team members and the TAs know what the changes are without having to go through all the files. You have learned about the conventions for commit messages during the git lecture. To refresh you memory you can look at this guide.
To commit the changes in the terminal you need to enter the command;
git commit -m "your commit message"You can also add your commit message in an editor by removing the -m and the commit message.
NOTE: The default editor on many systems is vim (which is a very useful tool to learn). If you enter it by accident, use the following key sequence (one by one) to exit:
[escape][:][x][enter](to store changes and quit vim). To exit without storing your changes you can use[escape][:][q][!][enter]. You can find a tutorial on vim here if you want to get started with it.
Commit cohesive sets of changes, and give the changes a clear description. You can find more best practices in this online article by Tower.
Assignment
Commit the changes you staged in the previous assignment.
How to reset a set of changes
Sometimes you committed something incorrectly, for example when you forgot to check if the code actually compiled. All the commits that are not online yet can be reset without too many problems.
Terminal
To reset the branch to the last commit you can use the following command;
git reset [--soft | --mixed | --hard] HEAD~1
Without specifying the reset option it will default to a mixed reset. The number behind HEAD~ is how many commits you want to go back. To see the log of the commits and check where you want to go to when you made multiple commits use the command;
You can see the history of commits using git log. Optionally add the shown parameters to make it look nice
git log --all --graph --decorate
Assignment
To try it out, make some changes in the
README.mddocument that you do not want to share and commit them. Then reset the changes.
Try out all the different options for resetting your branch to see what the effect is. We recommend soft reset as it keeps your changes. Mind that these changes remain staged!
Synchronise your commits to GitLab
To allow for everyone to use and see your changes, you need to upload the changes to GitLab. Uploading the changes is done by pushing the commits containing your changes. After pushing, you cannot undo the changes anymore. When you made a mistake, you need to make new changes, commit them and push that commit again to change it.
Before you push your on commits you should ensure that your local repository is up to date by pulling all changes that others may have pushed meanwhile. This will be explained in the next sections.
For pushing, use the command:
git pushWhen you want to push a new branch, which you will do in the next assignment, you need to push in the following way;
git push -u origin <branch_name>Note that if you set the following option, git will automatically assume that you want to push to the branch with the same name on the remote. If you set it, you can always just use
git push.git config --global push.autoSetupRemote true
Assignment
Push the changes you have made so far.
Working together
So far we have only worked in the "main" branch (previously this was commonly referred to as the "master" branch). This branch is meant for a stable version of your project and not meant for ongoing development. So far it worked out because you are the only person working in this repository, but imagine when all your team members also make changes on the same code. You would not be able to see easily what is finished and what is still in progress, plus there might be a broken product on "main". So from now on: never push to main. Instead, you should create branches to work in isolation on the new features and functionalities. The branch should have a name which is descriptive about its purpose.
Creating a branch
First, a branch must be created.
Terminal
Use the following command to make a new branch:
git branch <branch_name> git checkout `branch_name`Or the shorthand
git checkout -b <branch_name>When you want to push a new branch, which you will do in the next assignment, you need to push in the following way;
git push -u origin <branch_name>
Branches are created from the currently checked out commit. Typically you create a new branch from the most recent working version of your product. Sometimes you may want to try a different approach to a problem, then you can go back a few commits and branch from there.
Assignment
For this assignment you are going to create a new branch for adding the required tools for this assignment to the README file. For example, you need Git and SSH to complete this assignment. Decide on a descriptive name and create the branch. Add the requirements and make sure to push the branch to the remote repository.
(You may run into an error
The current branch new_branch has no upstream branch., the error should already include instructions on how to resolve this).
Switching to another branch
When you made changes on a branch, you sometimes need to change branches to look at something from someone else (for example when reviewing code). To change branches, you need to do the following;
Make sure that all the updates are visible on your machine by fetching;
git fetch --allNow you can view and switch branches by using the following commands;
git branch -a git checkout <branch_name>
Switching branches is possible when you have no uncommitted changes. Make sure that all changes are either stashed (see Additional features) or committed before changing branches.
Assignment
Create a new branch called
merge_readme. Switch to it, and push it to GitLab. Make sure you can see the new branch on the website.When on the branch, make one commit which changes multiple lines in the README. Also change the title of the README.
Switch back to the main branch, and then also make a commit here that makes different changes to the README. Make the title of the README different than on the
merge_readmebranch.
Combining your feature with the “live” version of the system
When you start coding, your peers can work on other features in the meantime. To see if the features work together, you can combine the features by merging their branches. To merge their changes into your branch, you need to do the following;
Make sure that the to be merged branch is up to date (by using fetch and pull) then execute the following commands:
git checkout <base_branch_name> git merge <branch_name_to_be_merged_into_base>
Merge Conflict
Sometimes merging cannot be done automatically. This is called by a merge conflict, which basically means that the two branches changed the same part of a file. Git will modify the conflicting file to have both versions. The two versions are separated by greater than (>), equals (=) and less than (<) signs. It is your task to determine what the correct version is and make sure the merge is correct.
Always check if merging worked out before you commit the resolved merge conflict. Make sure your code still works afterwards by compiling and running the tests for example.
When the merge fails the affected files will be listed in the output using the following format;
CONFLICT (content): Merge conflict in <file>Resolve the conflicts in these files in your editor and commit the changes to finalise the merge.
Assignment
Merge the branch
maininto themerge_readmebranch (NOT THE OTHER WAY AROUND) and resolve the conflicts. Make the new title become the title of themainbranch, but the contents be the contents from themerge_readmebranch. Make sure togit addandgit commitand push the changes you made to themerge_readmebranch.
Merging your changes in the main branch
When you finish working on a feature, the changes need to be put into the shared repository. To do this, we create merge requests. This allows your peers to check and give feedback on the changes you made and spot potential bugs.
Creating a merge request is done in the GitLab online environment. Here you can set a variety of options. For example, you can (and should) provide a short description of the changes you want to merge. Besides that, you can request a specific person to review your merge request. You can also require a certain number of approvals before your merge request may be merged. There is also an option to mark a merge request as draft, which will make it impossible to merge it (until it is unmarked as draft).
Create a merge request for the
merge_readmebranch to themainbranch. Once this is done, merge the merge request.
It is generally considered bad practice to merge your own merge requests. Since this is an individual assignment, it's fine to do so now. However, during the project, make sure one of your peers merges your merge request (after reviewing it thoroughly).
Synchronise changes from the remote in your local repository
When new changes are pushed into the remote repository, the changes are not automatically put onto your computer. To obtain the latest version of the files, you should pull the branch from the remote.
Make sure you have no uncommitted/unstashed changes when pulling.
Assuming you are on the branch you want to update, pulling can be done in the following way;
Type the following command;
git pull
When someone pushed changes onto your branch and you did too, Git will merge the changes that happened. This merge will result in a merge commit where, just like with merging, merge conflicts can occur.
Switch back to the
mainbranch and see what the current status is of themainbranch. After this, use pull to get the new changes. What changed?
Full workflow for adding changes
Now that you have seen all basic functionalities of Git and GitLab, it's time to put them all together. In this final task you will perform the full workflow of finding a problem, reporting it and fixing it.
The final part of your readme should be a short reflection on this assignment. The readme should contain 2 sentences about what you learned in this assignment (What was hard? Did you already hear of certain terms before?).
Create an issue in GitLab describing the problem: a reflection is missing. Make sure the issue has a clear title and description.
The next step is to fix the problem. As you saw before, each issue should be resolved in a separate branch.
Create a new branch to work on this issue.
Create a branch to work on the new issue. Next, create a merge request to solve this issue in GitLab.
Now it's time to fix the problem.
Checkout the newly created branch. Address the issue by adding your reflection. Once you are done, commit and push the changes.
Propose the fix by creating a merge request for it.
Create a merge request for the branch. Make sure the title and description are clear. If you already created the draft merge request automatically with the branch, unmark the merge request as draft.
If you created the branch from GitLab, you will notice the text "Closes #1" is put in the description automatically. This links the merge request to the issue it was made for. Once the merge request is merged, the issue is closed automatically. You can also add this text to a merge request manually: "closes", "fixes" and "resolves" are keywords you can use, followed by the issue number.
Normally your peers would review your changes by leaving comments and/or suggestions on your merge request. Once that is done, one of them will merge your changes into the codebase. You will have to perform the merge yourself this time.
Merge the merge request you just created. Checkout the
mainbranch and pull the latest changes.
Congratulations, you have reached the end of the Git assignment! You should now know the basics of how to work with Git and GitLab.
If you are interested in more information about Git, you can read the section on additional features.
Additional Git features
On this page we will discuss some more advanced features of Git you could read about if you want to learn more about Git.
The intention of this page is not to teach you all these advanced features, but rather to make you aware they exist. As such, not all features have instructions on how to perform them. Feel free to look them up if you want to know more about these options.
Stashing
Sometimes you made changes that you want to save, but not commit. This can be done with stashing. This will save the changes that you made locally, but does not apply it to the history of the project, it is only on your computer. Additionally, it automatically restores your branch to the last committed version on your machine.
The most useful use case for stashing is the following scenario:
- You are working on a feature, but you notice a bug in another part of the code.
- You stash your changes and start fixing the bug on a new branch.
- You commit the changes and make a merge request for the bug.
- You go back to your own branch start working with the assumption of the working code.
- You apply the stash to get your changes back and continue working.
For the terminal you can stash your changes by using the command;
git stashAfterwards you can use two commands to see and apply the changes to your code again;
git stash list git stash applyYou can apply specific stashes by using the reflog syntax, which is the name it states before the stash when viewing the stash list,
stash@{0}is for example the latest stash.
Tagging
Tags are marked versions of your program which can be downloaded easily from the repository. It is possible to make tags using Git, but you are also able to make tags in GitLab which is perfectly fine as well. The tags are essentially small releases you make of the project (for example a version number can be a nice use case for a tag).
Cherry-picking
Sometimes it may occur that you run into a bug that someone fixed in a commit on a different branch. This is where cherry-picking comes in. With cherry-picking you are able to apply the changes of a specific commit to your own branch.
Rebasing
Rebasing is another way of merging two sets of changes together. Instead of combining them and putting it into a merge commit, rebase reapplies the changes made on top of another branch. For example, if you are in branch A, which branched off of main, and main gets updated with new changes, you can rebase A onto the latest commit of main. All changes of the branch are applied starting from a new commit. The resulting code is the same as if you had merged main into your branch, but now there is no such merge commit.
Rebasing rewrites the history of the project by creating new commits for each commit in the branch to rebase. It allows for a cleaner project history and can make the history easier to understand. It does come with some risks:
- The collaboration workflow can become distorted, because you rewrite history.
- You cannot elaborate on why you had to perform this merge (which you could have indicated in the merge commit otherwise).
Rebasing can be done interactively usually to clean up any messy history. Here you can reorder, combine or plainly delete commits that were created. Interactive rebasing leaves room for errors, as this process is irreversible and distorts the workflow that resembles the actual product.
We do not allow rebasing during the project to make sure that we have an accurate representation of the work you and your group provided. You are allowed to do it on local branches that are not public/pushed to the remote. You can change your local history, but not the published history. If you want to try rebasing, you can do this in your repository for the Git assignment.
People tend to have different preferences when it comes to merging vs. rebasing. We do not claim that one is better than the other. For your own projects you should pick whichever you like best.
Automatic rebase
Automatic rebasing is a tool to avoid merge commits in the same branch. When more than one person is working on a branch and another person pushes their commits before you pushed yours, the created changes have to be merged with your changes. The “default” solution uses a merge commit: the new version of the remote branch is merged into your local branch. These merge commits can clutter the Git history and leave the history less clear than before.
An alternative solution is to rebase your commits. This will pull the new commits from the remote and rebase your commits on top of them. This can be done automatically by enabling automatic rebasing. Since your commits are not pushed yet, it will not cause a problem for your peers. However, as you might have changed the same code as your peers, it is possible that conflicts occur. You can resolve these in a way similar to resolving merge conflicts. Always make sure to check the code still works after rebasing.
Auto stashing
Automatic rebasing is used to rebase your unpushed commits onto new commits on the remote branch, but what if you didn’t commit your changes yet? You can stash your changes, pull the new commits and apply your stashed changes afterwards. This process can be automated by enabling automatic stashing.
Force pushing
When you are changing the history of a branch that is already online, Git will prevent you push this branch because it conflicts with the existing branch on the repository. When you are sure that the branch you have is the correct one, you are able to force push a branch. This tells Git that you know it conflicts, but you are absolutely sure of what you are doing and the remote branch should be overwritten. During the OOP Project, force pushing is not allowed on the group project repositories. You are free to try this out on your repo for the Git assignment.
By force pushing you can irreversibly delete code from your repository. Any changes made remotely between the time you last pulled and your forced push will be overwritten. A slightly safer version of forcing a push is using force with lease: this will be rejected in case newer commits were pushed to the remote branch.
Link to WebLab
https://weblab.tudelft.nl/cese4000/2025-2026/ Make sure to log-in and enroll
WebLab
WebLab is a controlled programming environment in which you can practice single concepts of Rust. The WebLab assignments will not be graded, though we recommend that you do them. Especially the assignments of week 1. These are not at all very difficult, but they will get you started with some simple programming.
Important assignments
If you don't want to do all WebLab assignments, but do feel like doing some, the following form a good set to start with, which covers many important topics but will not take too much of your time:
week1/basics(easy)week1/types/references(medium)week1/types/all about vecs(medium)week1/Binary Coded Decimal(hard)week2/structs and ownership/Wacky Stacky(medium)week2/structs and ownership/Brackets(hard)week2/enums and matching/matching(medium)week2/enums and matching/Structural Matching(medium)week2/enums and matching/Creating Patterns(medium)week3/traits/Sign Magnitude Representation(hard, may take a bit of time)week3/iterators and collections/anonymous functions(easy)week3/Case Converter(medium)week3/Hashed collections(medium)
Individual Assignment
This assignment has two parts, the actual assignment and requirements. And a reference manual, see the links below for both.
Individual Assignment
This is the assignment you will do in the first four weeks of the course. In it, you will create a program to process data from smart utilities: gas and electricity meters, and turn this data into a series of plots.
On a high level your program should be able to parse so-called 'telegrams' produced by smart meters. The exact specification of these telegrams is a separate document, you can find here. The parsed data should be converted into some kind of useful data structures (enums, structs, etc) and from that you will generate the data of several plots. This data you can feed into a utility we have provided to you, which will turn the data into actual visualizations for you.
We expect you to work on this assignment gradually while following the lectures of this course. Using the knowledge you've gained from each lecture by applying it to this assignment. That being roughly in the following order:
- Create data structures matching the format of the telegrams (see the second grading point)
- Parse strings into these data structures
- Aggregate data and test the soundness of your program
If you run into any trouble or if anything is unclear, please come to the labs to ask your questions!
Note: There are certain restrictions you have to work with while making this assignment, like not being allowed to use all libraries.
Required Setup
Please read Software Setup to see what packages etc. you need for running the template.
Data Aggregation
The telegrams you parse contain data.
Telegrams come in sequences with timestamps.
We ask you to implement a simple pipeline that takes these sequences of telegrams, and plots the data contained
using the plotting library we provide you called tudelft-dsmr-output-generator.
The template you will start with already includes this library.
Using tudelft-dsmr-output-generator we expect you to display:
- Current of each of the three power phases over time (see
current_over_timein the library). - Voltage of each of the three power phases over time (see
voltage_over_timein the library). - A linechart of energy production and consumption over time (see
energy_over_timein the library)- Each telegram is a datapoint (total energy consumed and total energy produced)
- The plot should show the difference with the previous datapoint. i.e. even though the data is cumulative, the plot should not be.
- Always use the first telegram as a reference. Discard the data in the first telegram, but plot the difference with the second telegram, and then the third, etc.
- Only plot the last 12 datapoints.
- A gas over time chart that works similarly to energy production in that the reporting is cumulative but we expect you to plot the differences
- However, there is no concept of gas production.
- An overview of events that occurred in the sequence of telegrams
- Ordered by date!
IMPORTANT NOTE: Time is hard! To help you, there is a function exposed in
tudelft-dsmr-output-generatorcalleddate_to_timestamp. If you parse dates correctly and use this function, you don't need to worry about timezones at all.
Graphs
Below you can see the expected output of should_parse_4_recursive.dsmr, which you got in your examples directory.
And here is the expected output of should_parse_3.dsmr (which is non-recursive)
Below you can see in detail the graphs from the expected output of should_parse_4_recursive.dsmr.
Gas graph
Current graph
Voltage graph
Energy graph
JSON Example
The following is a snippet from the generated JSON file that is expected using the should_parse_4_recursive.dsmr.
{
"data": [
{
"produced": 30.0,
"consumed": 16.0,
"timestamp": 1072916922
},
{
"produced": 34.0,
"consumed": 20.0,
"timestamp": 1072916982
},
// ...
]
}
Grading
Your grade starts at a 1. For each requirement you implement you get the specified amount of points below. Up to a maximum grade of a 10. You will see that in the rubric below, you can receive up to 9 points reflecting this.
You need to have a minimum of a 5.0 for this assignment to be allowed to follow the second part of this course (the group project) and thus be able to pass this course.
- Implement the complete parsing of v1 of the protocol (2pts).
- You have to use structs, enums and at least one match statement
- note: if unable to parse certain constructs, partial points may be awarded
- A sensible data format that represents the structure of telegrams. This item will be manually graded based to up to (1pt). With "sensible", we mean:
- You use enums to represent parts of the format which make sense to be enums.
- You use structs to represent parts of the format which make sense to be structs.
- Certain telegram structures which are never valid (hint: telgrams containing different kinds of information at the same time) cannot be represented by your format.
- Reject invalid telegrams (1pts)
- This requires you to reject invalid telegrams of all the protocol versions you implement
- On rejection: exit gracefully with exit code
42. - note: partial points may be awarded
- Output of the aggregated data format as specified in the assignment above (1pts)
- Make sure to also do this for v1.2 of the protocol when you implement it.
- With this we mean the plotting of the data using the
tudelft-dsmr-output-generator.
- Unit testing of components of your program (0.75pts)
- A few basic smoke tests (0.15pts)
- Substantial testing of at least 10 distinct unit tests covering 40%1 of your code (0.15pts)
- Thorough testing with unit and integration tests with in total least 25 distinct tests covering 80%1 of your code (0.3pts)
- Unit and smoke testing as defined in Lecture 7 (0.15 points)
- note: no further partial points can be obtained
- Error Handling (0.75pts)
- tip: use
.expect(..)in your code instead of simply.unwrap()before attempting this so that it is easier to implement when you do get around to it. - No panics given malformed data
- No panics on malformed unicode input
- On errors, the program outputs a message and nonzero exit status but does not panic.
- note: partial points may be awarded
- tip: use
- Integrated Error Handling with Testing (0.5pts)
- Different erroneous inputs return different kinds errors
- Have at least 10 different error cases across your program
- Tests verify that your parser rejects erroneous inputs for the right reason
- Implement version 1.2 of the protocol (parsing and aggregation) (2pts)
- Recursively parse sub-telegrams
- When graphing data, information should be accumulated (added together) from sub-telegrams (so if there is a toplevel electricity meter and a sub-electricity meter the total energy consumed and produced should be combined (usually by summing)). The Date of sub-telegrams does not matter, assume all data is produced at the same time.
- Parse Gas information when the
gextension is found - note: partial points may be awarded
Progress Expectation
Below is a recommendation of where you should be in the project for each of the 4 weeks.
| Week | Description |
|---|---|
| Week 1 | Parse and output event data. |
| Week 2 | Parsing timestamps, floating decimal numbers and string types, including error checking |
| Week 3 | Voltage, current and energy parsing and graph generation. |
| Week 4 | Sub-telegrams and gas meter data parsing, and graph generation. (make sure these requirements are met!) |
Ideally, implementation of your tests should happen parallel to your development of the actual application. Just make sure that the first time your code compiles isn't in week 4, and test that small parts work starting in week 1.
Limitations
For this assignments you are not allowed to:
- Exchange code with other students. We'd like to evaluate how good you are at programming, not your friends. Discussing concepts during labs is strongly encouraged, but make sure you show what you can do.
- You are not allowed any additional dependencies, except those already present in the template code you received. That means that you are limited to the following crates:
thiserror(Or other purely error-handling libraries. If you choose any other, discuss with a TA)itertools(for convenience, you don't need this crate)tudelft-dsmr-output-generator(our library)
If you get stuck
- Look at what the compiler is telling you! It's often mighty useful
- You can always ask a TA during one of the labs which run twice a week
cargo clippycan tell you things about your code the compiler wouldn't even catch
Hand-In Details
The deadline of the assignment is Sunday the 28th of September, at 23.59, and we will only check the latest commit on the main branch before this date.
Learning Goals
- Gain confidence in your ability to write a small but useful Rust program, specifically:
- use control flow primitives and use match
- design data types to match data
- work with string data
- using iterators
- using recursion
- writing tests
- handle errors and validate input
- Learn how to read requirements and implement them
- Learn how to write robust programs by writing (unit) tests and applying proper error handling
- Gain some elementary knowledge about using the Git VCS

Introduction
This document provides the "Delft Smart Meter Requirements" (DSMR), a fictional standard for an Automatic Meter Reading (AMR) system for electricity and gas meters.
The scope of this standard is the end-consumer interface (P11) for:
- Residential electricity meters
- Residential gas meters
This standard focuses on the interface for gas meters.
 Figure 1.1: Meter interfaces overview
Figure 1.1: Meter interfaces overview
The goal of this standard is to reach an open, standardized protocol implementation and functional hardware requirements related to the communication between several types of Service Modules and a Metering System. Any specification in this standard is intended to encourage suppliers to develop their hardware and software in a common direction. Standardised protocols and hardware specifications are referred to as much as possible. This companion standard is the result of a combined effort of the major Delft grid operators.
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and " OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Devices and Telegrams
DSMR data is generated by DSMR supported devices such as various kinds of smart meters. Smart meters are connected to each other like a tree. Each DSMR supported device MAY have up to 3 ports through which they connect to other meters, sub meters. A device SHALL NOT have more than 3 ports.
DSMR Version 1.2 and up reflects this tree-like structure, while Version 1.0 data must be flat. DSMR data is sent in telegrams. Sequences of telegrams start with a version header, followed by at least one telegram.
When a sub-meter sends a Telegram, it will pass through a parent device. The parent device then outputs a new telegram, with inside it the sub-telegram from the sub-device. The parent SHALL ALWAYS add more information to the combined telegram since parents are meters themselves too. That means that the top level device will often send a packet with zero or many sub-packets associated with the sub-devices.
Sub-devices MAY be the same kind of device as a parent or another sibling. For example, it is possible that there are two electricity meters and a gas meter connected to a top-level electricity meter.
For historical reasons, the top level device MUST be an electricity meter device (not gas).
Representation
Example Telegram(s)
Below we show an example of a DSMR telegram message. In the following text, we will define the structure of each part of this and other DSMR messages.
/v10\
1.1.0#(START)
2.1#(23-Jul-05 15:26:41 (S))
3.1.1#(H)
3.2.1#(506f776572204661696c757265)
3.3.1#(23-Jul-02 13:12:00 (S))
3.1.2#(L)
3.2.2#(566f6c7461676520746f6f206c6f77)
3.3.2#(23-Jul-05 13:37:00 (S))
4.1#(E)
7.1.1#(0241.7*V)
7.1.2#(0240.6*V)
7.1.3#(241.92*V)
7.2.1#(01.*A)
7.2.2#(10.*A)
7.2.3#(0.5*A)
7.3.1#(+001.00*kW)
7.3.2#(-05.010*kW)
7.3.3#(+02.500*kW)
7.4.1#(0011454892.*kWh)
7.4.2#(0000001245.*kWh)
1.2.0#(END)
Representation of primitive protocol values
| Value format | Example | Meaning |
|---|---|---|
Fn(x,y) | F7(3, 3) - YYYY.YYY | Floating decimal number with a fixed number of decimals behind the decimal point (in this case 3) |
Fn(x,y) | F7(0, 3) - YYYY.YYY or YYYYY.YY or YYYYYY.Y or YYYYYYY. | Floating decimal number with a variable number of decimals behind the decimal point (with a minimum of 0 and a maximum of 3). A Floating point number must have a decimal point. |
In | I4 - YYYY | Integer number with n digits |
Sn | S6 - CCCCCC and S2..4 - CC or CCC or CCCC | Alphanumeric string, number of characters defined by the number or range that follows. If hexadecmial, double the number of characters follow (2 hex-digits per character) |
DATE | YY-MMM-dd hh:mm:ss (X) - 23-Jul-05 15:26:41 (S) | ASCII presentation of Time stamp with Year (0-99), Month (name), Day (1-31), Hour (0-23), Minute (0-59), Second (0-59), and an indication whether daylight savingstime (DST) is active (X=S, UTC+2) or DST is not active (X=W, UTC+1). Dates are always strictly after 1970-01-01 00:00:00 (W). Month codes are Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec |
IMPORTANT NOTE: Time is hard! To help you, there is a function exposed in
tudelft-dsmr-output-generatorcalleddate_to_timestamp. If you parse dates correctly and use this function, you don't need to worry about timezones at all.
Representation of Sn
Strings are represented with the Sn format.
When the format specifies a field which can have an arbitrary string as value, string characters are represented with
hexadecimal characters, two characters per byte.
However, sometimes the format specifies that a string can only be one or multiple exact values. In that case, those
values are not encoded as hexadecimal, and are the exact value specified.
The length of a string is implicit, but all fields are delimited by parenthesis so the length can be deduced from the format.
(AABB...CC)
1 2 3
AA: hexadecimal characters representing the first character of the stringBB: hexadecimal characters representing the second character of the stringCC: hexadecimal characters representing the last character of the string
(strings are always in ASCII, unicode is not supported)
Example
The following is the string "Hello, World!", S13, encoded according to this format:
48656C6C6F2C20576F726C6421
Representation of a Telegram
A top-level telegram always starts with a version number. The format for such a version number is as follows:
| / | S3 | \ | + | S0..10 |
|---|---|---|---|---|
| ascii 0x2F | "v", followed by 2 digits | ascii 0x5C | ascii 0x2B, if extensions follow | unordered list of extension codes2 |
After which, the content of a telegram follows. Note: the header MUST NOT contain any whitespace or characters other than those defined above.
Version number reference
| Version | Notes |
|---|---|
v10 | Version 1.0 doesn't support any extensions and MUST reject telegrams that have extensions. MUST also reject sub-telegrams. |
v12 | Version 1.2 supports both the gas and recursive extension, though only when specified, and MUST reject any invalid extensions |
Each version increase only adds to the standard. For example, parsing of v1.2 packets does not fundamentally change how
v1.0 packets are parsed.
When no extensions are present then there MUST be no + after the version number.
Extensions code reference
| Extension code (case sensitive) | Description |
|---|---|
g | Gas |
r | Recursive (supports subtelegrams) |
Other extension codes and duplicate extension codes are considered invalid and MUST be rejected.
Example of version
The following is an example of a version header of a telegram. It is a version 1.2 with extensions for recursion and gas.
/v12\+gr
Representation of Telegram content
The following table holds the structure of the content of a Telegram.
The fields of a telegram can be sent in any order, unless otherwise noted, and MUST always start with a field id.
Every field implicitly ends with a newline character \n (0x0A) and on some operating systems also a carriage return \r.
| Description | Field ID | Value format | Unit | Note |
|---|---|---|---|---|
| Start of Telegram | 1.1.0 | S5 (always: START) | MUST be first | |
| Date of the Telegram | 2.1 | DATE | MUST occur exactly once per telegram or sub-telegram | |
| Eventlog Severity | 3.1.n | S1 | MAY repeat, n is the event id. MUST be H for high or L for low | |
| Eventlog Message | 3.2.n | S0..1024 | MAY repeat, n is the event id (arbitrary, hex string) | |
| Eventlog Date | 3.3.n | DATE | MAY repeat, n is the event id | |
| Information type | 4.1 | S1 | "G" (gas), "E" (electricity). SHOULD come before the information itself, and MUST only appear exactly once in a telegram. | |
| Electricity: | ||||
| Voltage | 7.1.n | F5(1,2) | V | n is the phase (1, 2 or 3) |
| Current | 7.2.n | F2(0,1) | A | n is the phase (1, 2 or 3) |
| Power | 7.3.n | (S1) F5(0,3) | kW | n is the phase (1, 2 or 3). Sign (+ or -) is optional. |
| Total consumed | 7.4.1 | F10(0, 0) | kWh | (cumulative) |
| Total produced | 7.4.2 | F10(0, 0) | kWh | (cumulative) |
| Only in V1.2 and up: | ||||
| Start Child Telegram | 1.1.n | S5 (always START) | MAY repeat a maximum 3 times, n is the child id (>0 and <=3) | |
| End Child Telegram | 1.2.n | S3 (always END) | MAY repeat a maximum 3 times, n is the child id (>0 and <=3) | |
| Gas extension: | ||||
| Total gas delivered | 5.2 | F8(3,3) | m3 | (cumulative) |
| End of Telegram | 1.2.0 | S3 (always: END) | MUST be last |
Note: The order of event log entries is only decided by their date. n is simply a unique id.
Representation of fields
A field is always represented on a single line and its format is as follows
| ID | # | ( | Value | * | Unit | ) |
|---|---|---|---|---|---|---|
| Field ID | ascii 0x23 | ascii 0x28 | Attribute according to value format | ascii 0x2a, if a unit follows | Unit if applicable | ascii 0x29 |
Note that units MUST be present when the protocol specification lists them. They MUST be the right unit for the value type to the protocol specification.
Example
As an example, the following is the representation of the current voltage on phase 1
7.1.1#(240.42*V)
Representation of child telegrams
Telegrams MAY contain data received from child devices.
Such child data starts with Field id 1.1.n, with n representing which child device the data is from.
Immediately after the start, fields from that child device will follow until a stop is received (Field id: 1.2.n,
with n matching the start).
A telegram MUST have at most 3 child devices, thus n can only be 1, 2 or 3.
Children MAY have more children of their own, recursively.
The top level telegram MUST contain information for Electricity, and MUST not contain Gas information. Therefore, Gas meters MUST always be child devices.
An example is shown below of a telegram with gas data. Since gas data cannot be toplevel, it is included as a subtelegram, while the toplevel telegram is a telegram from a electricity meter.
/v12\+rg
1.1.0#(START)
2.1#(23-Jul-05 15:26:41 (S))
3.1.1#(H)
3.2.1#(506f776572204661696c757265)
3.3.1#(23-Jul-02 13:12:00 (S))
3.1.2#(L)
3.2.2#(566f6c7461676520746f6f206c6f77)
3.3.2#(23-Jul-05 13:37:00 (S))
; Start gas subtelegram
1.1.1#(START)
2.1#(23-Jul-05 15:26:41 (S))
4.1#(G)
5.2#(12345.123*m3)
1.2.1#(END)
; End gas subtelegram
4.1#(E)
7.1.1#(0242.7*V)
7.1.2#(0241.6*V)
7.1.3#(242.92*V)
7.2.1#(0.7*A)
7.2.2#(10.*A)
7.2.3#(0.5*A)
7.3.1#(+001.00*kW)
7.3.2#(-05.010*kW)
7.3.3#(+02.500*kW)
7.4.1#(0012454892.*kWh)
7.4.2#(0000001445.*kWh)
1.2.0#(END)
Requirements for Telegram content
A Telegram must have certain fields. Telegrams which do not follow the requirements are invalid and MUST be rejected.
- Each Telegram MUST contain a start, an end, and date
- A telegram MUST contain up to 3 child telegrams (0 is possible)
- A telegram MUST only contain information from a single meter: Gas or Electricity. Fields with information of different meters cannot be combined in a single telegram.
- A telegram MUST contain exactly one 4.1 information type field
- The top level telegram MUST only be from an Electricity meter. Gas meters MUST only be child meters and their information is contained in child telegrams.
- Empty lines and stray newlines MUST be ignored
- In a telegram, all field IDs MUST be unique.
- Every information type (Eventlog, Gas and Electricity) MUST be complete. For example, the electricity data MUST contain voltage, current and power of all three phases and the total consumed and produced power. Another example, every event log MUST have a date, message and severity.
Multiple Telegrams
In a single .dsmr file, multiple telegrams MAY be stored.
The telegrams come, concatenated, with zero or more newlines in between.
When multiple telegrams are concatenated, only one header MUST be present.
When multiple voltages are present of the same phase, you MUST only record the highest voltage per phase for purposes of the graphs. The same is true for current, that is to say, only record the highest. To repeat, all other quantities, for example power, should be summed.
Rejecting telegrams
When a telegram is malformed it MUST be rejected by any receiving node. If a single telegram in a sequence of telegrams is malformed, the entire sequence MUST be rejected. Rejected telegrams are thrown away, so parent meters do not need to spend time parsing such telegrams.
Comments
One MAY implement comments. That is to ignore any line that starts with a ; (0x3B).
Do not that some example telegrams in this document use comments.
Example
; this is a comment
Acknowledgements
This (fictional) standard is largely inspired by the Dutch Smart Meter Requirements: P1 Companion Standard version 5.0.2. This can be retrieved at the following URL: https://www.netbeheernederland.nl/sites/default/files/2024-02/dsmr_5.0.2_p1_companion_standard.pdf
If you are not following this course for a grade, but would like to get started with the project anyway, the template is available here If you are part of the course, you don't need to do this, and should not do this! You'll get a repository from us.
Introduction
In this manual we will provide you with all the information you need to get started on the project. Please read through it carefully.
The project
In this project you will be creating a Nintendo Entertainment System (NES) emulator in groups of 4 (though there may be some groups of 5). The project will be graded based on the following aspects:
- Completeness of your emulator: We will evaluate this using ROMs that you need to run. These will be provided.
- Quality of your code base: We will manually grade your code base to see how well you utilized core Rust concepts such as Enums and Traits. We will also look at the quality of your documentation and tests
- Collaboration: We will also look at how well you collaborate. This will take into account your git usage, as well as how efficiently you divide tasks and such.
Grading
You can find the requirements for the project, and the grading formula here
Planning
The project will take 4 weeks. Each week you will have a short meeting with your assigned TA to look at your progress and ask any questions related specifically to your group. In week 4 we will ask you to fill in a form with your preferences about whether you want to have your meeting on either Tuesdays or Thursdays. We will try to take this into account, but can't always guarantee this.
Attendance
The weekly TA meetings are IN PERSON. If you for some reason cannot be there, notify your TA IN ADVANCE. Your attendance will be considered as a part of your individual contributions, and your teamwork grades.
Fraud
If we suspect fraud, the case will be forwarded to the Board of Examiners.
- You are not allowed to discuss or share your specific code with other groups. You are allowed to discuss the project on a conceptual level, but not the concrete implementation.
- You are not allowed to copy substantial code from the internet.
- You are allowed to copy short pieces of code from the documentation, but in that case please provide a link to where you got it from.
When in doubt, ask one of the TAs.
Next chapters
The next chapters will provide you with more detailed information on the project. We will first provide you with an overview of the NES. Next, we will explain the requirements of the project in more detail. Then we will provide you with a guide on what we think is the best way to get started on the project. Finally, we will provide you with an overview of some useful links we encountered while working on the reference solution.
NES Introduction
In this project you will be creating an emulator for the Nintendo Entertainment System, or NES. Here we will briefly talk about what the NES is, and how it works.

NES
The NES is a simple game console created by Nintendo, in 1985. To play a game on the NES you insert a game cartridge. In early games, this cartridge only contained a read-only memory (ROM) chip. Later on, the cartridges also included random-access memory (RAM) and even some expansion chips for extra video or sound capabilities. Famous games like Super Mario Bros. 1, 2 and 3, The Legend of Zelda and Metroid were originally made for this console.
NES Architecture
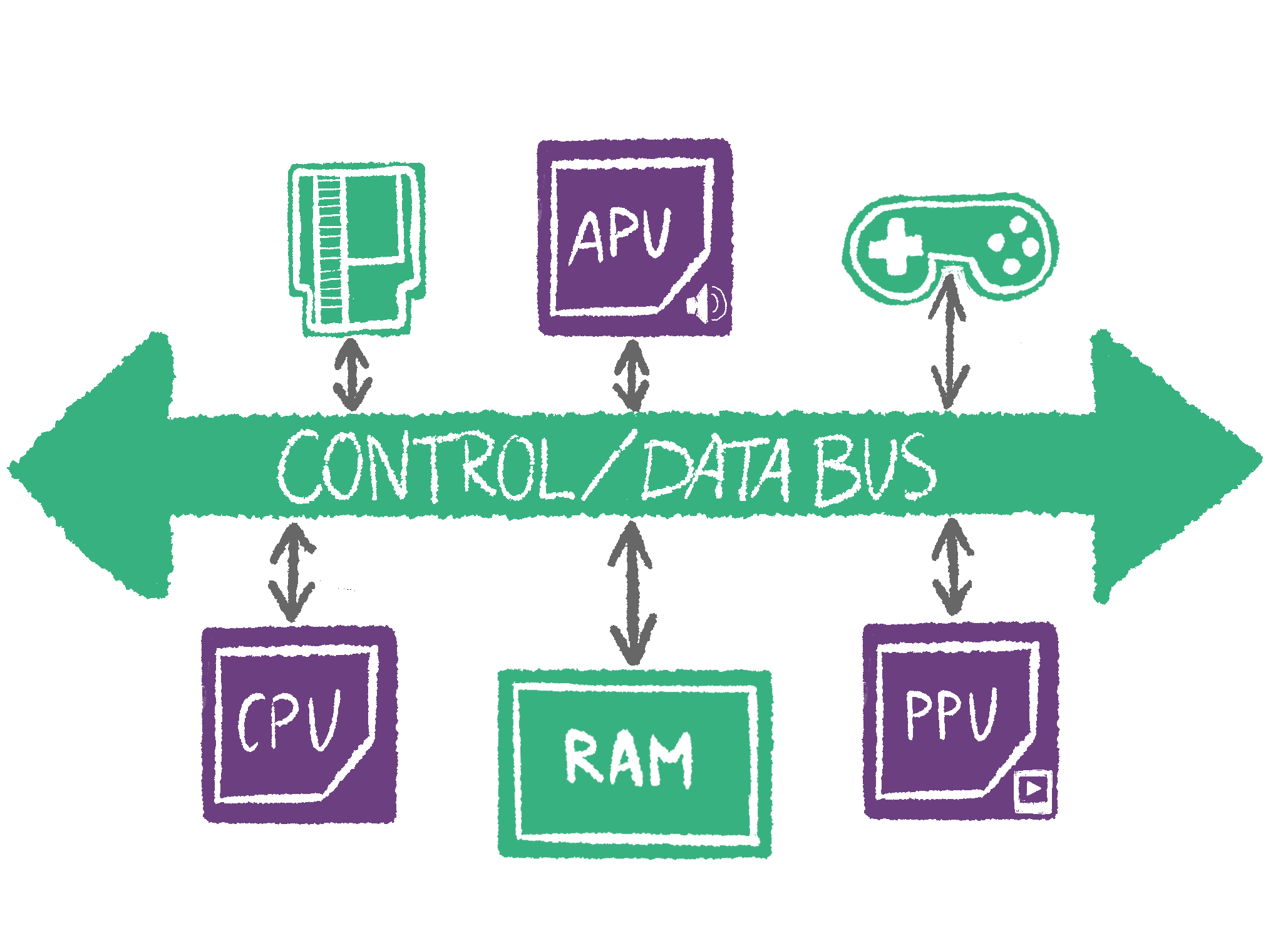
The NES consists of four main chips.
6502
First off, there's the 6502 CPU, which you will be emulating during the project.
This CPU executes the instructions on the game cartridge. The 6502 used in the NES
is slightly special, since decimal mode is
disabled on it. NOTE: That means you do not need to implement decimal mode!
Ram
There is the RAM chip. This contains a bit of modifiable storage space. And it's not much. Only 2 Kilobytes
of ram are available. This is pretty much nothing compared to modern standards.
PPU
The PPU or the Picture Processing Unit is responsible for drawing on the screen. You can compare it to a modern-day
GPU. However, the PPU was a lot less configurable than GPUs, and could only work with 2d graphics directly from the
cartridge. We already provide you with a working PPU, so this is not something you need to emulate. However, the CPU
and PPU need to be able to communicate. This is something you will have to support.
The PPU has its own memory space. The PPU has its own ram, and parts of the cartridge called character rom (because the character data is stored there) can only be accessed by the PPU.
APU
Finally, there is the APU or the audio processing unit.
This chip is not part of the project. We haven't implemented it for you, and you don't need to implement it.
However, you can of course implement it as a bonus.
Cartridge
Both the CPU and the PPU can interact with the cartridge. A cartridge was used to physically distribute video games for the NES. The Cartridge contains two kinds of ROM, and usually some RAM.
- Character ROM, data for the PPU like sprites, backgrounds, etc.
- Program ROM, data and instructions for the CPU?
On some cartridges, the RAM was protected with a little battery. This was useful for saving game progress. Note that you don't actually have to save RAM contents after the emulator finishes. You could do this as a bonus though.
For emulators, cartridges are usually stored as .nes files. These files contain a small
header with information about the cartridge, followed by the raw binary data of the ROM.
Mapper
The memory mapper is a chip on the cartridge, which can change the way memory is laid out. Different games may have different
mappers, and in the .nes cartridge file format there's a number specifying which mapper
it requires.
Mappers are necessary, because the memory space of the NES is only 64Kb large. A memory space is all the places the CPU can access. The reason for this limitation is that the address of a memory location can only be 16 bits large on the NES. However, games are routinely larger than 64Kb. Super Mario Bros 3 is 384Kb large for example.
The most common mapper is the MMC1. The MMC1 can support up to 256Kb of program data. It does this by changing parts of memory on-demand. At any time, two banks of ROM are loaded into memory. One bank from 0x8000 to 0xbfff, and one from 0xc000 to 0xffff. However, there are actually up to 32 banks available. By writing to a specific memory address (this is well documented), the CPU can order the mapper to change which bank is located at one of these two locations.
NOTE: There's also the NROM mapper. This is not a mapper at all. The bank assignment cannot be changed. Therefore, it's very simple to implement and a good starting point.
Controller
Finally, there is the controller.
We will provide you with code that can process keyboard input.
You should then pass this information to the CPU in the appropriate form.
Unofficial instructions
NOTE: This is bonus. If you are not doing this bonus, this part is not necessary.
If you look at this list of all the instructions supported by the NES, you see there are holes in the table. Games are not supposed to use these opcodes. If they do, the behavior is undocumented.
However, programmers figured out that the CPU does not always crash when these opcodes are used. The following things can happen if they are used:
- The CPU jams. It halts execution and just crashes.
- Nothing happens. This is equivalent to the NOP instruction. However, sometimes these instructions are longer than the normal 1-byte NOP instruction, which can be useful sometimes.
- Something random happens. Sometimes this depends on the temperature of the CPU
- Something consistent happens. An operation is executed which is not normally supported by the CPU.
The last category is most interesting. For example, opcode 0xa3 is the LAX "instruction". It's the same as executing an LDA and LDX instruction at the same time. Some games have actually started to use these instructions.
Requirements
In this part, you can find an overview of the graded parts of the project, and what their weights are.
Fraud and ChatGPT
Fraud (as well as aiding to fraud) is a serious offense and will always lead to (1) being expelled from the course and (2) being reported to the EEMCS Examination Board. As part of an active anti-fraud policy, all code must be submitted, and will be subject to extensive cross-referencing in order to hunt down fraud cases. It is NOT allowed to reuse ANY computer code or report text from anyone else, including ChatGPT, Github Co-Pilot or similar, nor to make code or text available to any other student attending CESE4000 (aiding to fraud). An obvious exception is the code that was given to you by the course.
an excuse that one “didn’t fully understand the rules and regulations on student fraud and plagiarism at the Delft Faculty of EEMCS” is NOT acceptable. In case of doubt one is advised to first send a query to the course instructor before acting.
Individual contributions
Part of your grade will be determined by your individual contributions.
Do note, that everyone in your group is supposed to do at least some part of the work. You are responsible, as a group (which we do also consider in your teamwork grade), to involve your team members in this project. We expect everyone to at least make some meaningful commits on the project repository which are not, say, simply fixing a typo in the Readme or performing existing code refactoring. This is also a large reason for why we reserve the right to make exceptions to the grading rules presented here.
Teamwork
With this part you can receive a total of 2 points based on the teamwork in your group. This point is shared in your group. We will take into account:
- Meetings with the TA
- Planning
- Distribution of responsibilities
- Git usage
There are also mandatory buddychecks, one halfway and one at the end.
Report
With this part you can receive a total of 1 point determined by your report. This point is shared in your group. This report should have:
- A reflection on your teamwork, results, and what you would do differently if you were to do it again.
- An overview of the architecture of your emulator, with a diagram of how your emulator functions.
- A description of the features you implemented (so we can grade them for the Technical requirements section)
We recommend you write the report using LaTeX but as long as you submit a readable PDF that is sufficient.
Code quality
With this part you can receive a total of 2 points based on the following criteria:
- Testing (assessed by your group's TA)
- Software Architecture (assessed by your group's TA)
- Linting (do you pass clippy and cargo fmt, version 1.79)
- Documentation, clarity and readability of code (assesed by your groups's TA)
This grade is shared in your group.
A note on clippy
Clippy is a very capable linting tool, but it does sometimes make mistakes. You can tell clippy not to look at certain parts of your code (this is discussed in the lectures). Obviously it is not allowed to ask clippy to ignore all style issues for the entire project. If however, on a small scale, you disagree with clippy: make a comment about it and disable the lint just for that specific instance. Your TA will look at this.
Technical requirements
The technical requirements consist of several parts. In total these parts are worth 5 points of your grade. These points are shared in your group.
With the base part, you can receive a total of 3 points:
Base
- Implement all the documented instructions, with their addressing modes (TEST: use
tudelft-nes-testto check this!) - Implement the NROM and MMC1 mapper
- Read cartridges in the
.nesformat from files - Proper timing of different instructions (NOTE: page-boundary and branch timing is bonus)
- Implement handling of interrupts
- Implement the NES CPU Peripheral Communication
- note: this includes PPU and Controllers but not the APU that is bonus
Only once you have implemented these base features to (near) completion, can you receive any of the following points:
Advanced
- Implement the unofficial instructions (max 1 bonus point)
- Be cycle accurate on page boundaries and after branch instructions (max 0.5 bonus points)
- Emulate the APU (max 1.5 bonus points)
- Add currently not-supported features to the PPU source code (max 0.5 bonus points)
- Support more mappers, such as the MMC31. (max 1 bonus points, depending on the complexity)
- Support battery backups (save games) (max 0.25 bonus points)
- If you find something else you think is interesting, do talk to the TAs. Maybe we can give you points for it!
Note that you will be limited by a maximum of 5 points for the technical requirements. Pick and choose which bonus features you like!
Exceptions
We reserve the right to change grades in exceptional cases.
Submission details
Your submission will be the most recent commit on the main branch. This submission should contain all of your code as well as a pdf file of your report (see above for details).
Using Libraries and Provided Libraries
For your project, we provide two libraries: tudelft-nes-ppu and tudelft-nes-test. These respectively provide all the
graphics systems for the emulator, and testing facilities (such as test roms) for your emulator.
You can request developer access to these repositories if you need this, by sending an email to the course email address
| library | documentation | repository |
|---|---|---|
| tudelft-nes-ppu | https://docs.rs/tudelft-nes-ppu | gitlab |
| tudelft-nes-test | https://docs.rs/tudelft-nes-test | gitlab |
If you want to use other, publicly available libraries, you are allowed to. However, they cannot be libraries that implement large parts of the project for you. If you're in doubt about whether you're allowed to use the library, talk to your TA.
-
Properly emulating the MMC3 mapper in particular may involve modifying the PPU library we provide. ↩
Getting Started
This chapter will provide you with information to help you get a smooth start to the project.
Gitlab
Each group has been provided with a Gitlab repository. You cannot push directly to the master branch. Instead, make proper use of branches and merge requests.
Template project
Each group will get a template project. A mostly empty project with some defaults filled in. It already has some required
dependencies set up, and quite importantly sets the optimization level to 1. The default optimization level of 0
is too slow to both run the emulator and ppu in real time. You can the --release cargo flag for even more optimizations.
Tasks
Creating the emulator is quite a big project. It may be hard to find a good starting point. Therefore, here are a few hints for things you can do first.
get_cpu
First, make a start at implementing the get_cpu function on the TestableCpu trait. This function is called by the testing framework, gives you a rom and expects a new cpu object (or an error).
Rom parsing
To build a cpu, you need to parse the binary data in the rom that is supplied. It is recommended that you start with a simple ROM mapper like NROM. The ROM will follow the iNES file format. You can find more links and information about the format(s) on the links page.
Instruction Parsing and Executing
The rom contains information about the instructions to run, the graphics for the PPU, and which mapper to use (you can read up on what a mapper is here)
The instructions are stored in so-called PRG-ROM (program rom), while graphics data is found in CHR-ROM (character rom).
The CPU cannot directly access CHR-ROM, only the PPU can. Similarly, the PPU cannot access PRG-ROM. Only the cpu can. Since we implemented the PPU for you, dealing with it is quite simple. But you are responsible for implementing the CPU.
PRG-ROM contains CPU instructions. These are encoded as one or more bytes, and to execute them they need to be parsed.
The first instruction to execute is located at a certain address in memory. This exact address is stored in memory too, but always at the same place. This place is called the reset vector which located at 0xfffd and 0xfffc on the 6502.
Further Steps
After implementing parsing and (some) executing of instructions you can start with the CPU's tick function. This is called once every 3 pixels that are drawn on the screen by the PPU. This is the same ratio as the real NES used.
Once you can run some instructions, you could start looking at things like interrupt handling, correct startup state and more and some of the bonuses. You can also run some of the more advanced tests from the testing framework.
Useful links
To help you figure out where you can find which information we have provided a list of links together with the subjects they are useful for. You are of course free to use other sources of information as well.
Instructions
- https://www.masswerk.at/6502/6502_instruction_set.html
- http://www.6502.org/tutorials/6502opcodes.html
CPU registers
Addressing Modes
General overview of the 6502:
Video explaining memory mirroring:
Initial cpu state:
Weirdness of BRK:
Mappers:
Rom file header:
Interrupts
CPU Memory map
Unofficial Instructions Information
Gamepak information
- https://nescartdb.com/search (can be used to find games that use a certain mapper)
Test Roms
iNES file format
Files with the suffix .nes are ROM files of game cartridges your emulator can play.
These ROMS are stored in the iNES file format.
iNES files store the contents of the cartridge ROM, and information on what additional hardware is present inside the cartridge.
The iNES spec has been extended with many features over the last two decades, but only a few essential parts need to be implemented to run almost every ROM.
In particular, you may ignore everything about the iNES 2.0 extension for this assignment.
If you do want to make your emulator run games that require information from the iNES 2.0 header to work you are free to do so, of course!
iNES files start with a sixteen byte header, followed by the ROM contents. The program rom (PRG-ROM) follows after the header. The character rom (CHR-ROM) follows after the PRG ROM. The format of an iNES file is described in detail below. For more information, see the useful links page.
Header
The iNES header is exactly 16 bytes long.
The first four bytes are always NES followed by the number 26 1
The fifth byte (index 4) records how large the program ROM is in 16KiB (16384 byte) units.
The sixth byte (index 5) records how large the character ROM is in 8KiB (8192 byte) units.
If the sixth byte is zero, the cartridge uses character RAM instead of character ROM.
The amount of character RAM is specified in a messy way that you do not need to implement, you can simply assume it's 8KiB large and most games will work fine.
The seventh and eight byte (index 6 and 7) specify more hardware features such as the mirroring mode and mapper. Parts that are labeled as 'not important' are rarely used, and there is no need to implement them.
Seventh byte Adapted from nesdev wiki:
76543210
||||||||
|||||||+- Mirroring: 0: horizontal (vertical arrangement) (CIRAM A10 = PPU A11)
||||||| 1: vertical (horizontal arrangement) (CIRAM A10 = PPU A10)
||||||+-- 1: Cartridge contains battery-backed PRG RAM ($6000-7FFF) or other persistent memory
|||||+--- Trainer, not important
||||+---- 1: Ignore mirroring control or above mirroring bit; instead provide four-screen VRAM
|||| Note: very few games use this
++++----- Lower four bits of mapper number
According to NesCartDB, only four official NES games ever used four-screen mirroring.
Eight byte Adapted from nesdev wiki:
76543210
||||||||
|||||||+- VS Unisystem, not important
||||||+-- PlayChoice-10, not important
||||++--- Not important
++++----- Upper four bits of mapper number
All other bytes of the header are not important.
-
26is the ASCII character that implied the end of a file on old computers. ↩