Lecture 1.2
Contents
Programs, processes and threads
Programs
Before we continue talking about threads, it's useful to talk about some definitions. Namely, what exactly is the difference between a program, a process and a thread.
Let's start with programs. Programs are sequences of instructions, often combined with static data. Programs usually live in files, sometimes uncompiled (source code), sometimes compiled. Usually, when a language directly executes source code, we call this an interpreted language. Interpreted language usually rely on some kind of runtime that can execute the source code. This runtime is usually a compiled program.
When a program is stored after it is compiled, we usually call that a "binary". The format of a binary may vary. When there's an operating system around, it usually wants binaries in a specific format. For example, on Linux, binaries are usually stored in the ELF format. However, especially if you are running code on a system without an operating system, the compiled program is sometimes literally a byte-for-byte copy of the representation of that program in the memory of the system that will run the program. From now on, when we talk about a program running under an operating system, you can assume that that operating system is Linux. The explanation is roughly equivalent for other operating systems, but details may vary.
Processes
When you ask Linux to run a program, it will create a process. A process is an instance of a program. This instantiation is called loading a program, and the operating system will initialize things like the stack (pointer) and program counter such that the program can start running. Each process has its own registers, own stack, and own heap.
Each process can also assume that it owns the entirety of memory. This is of course not true, there are other processes also running, also using parts of memory. A system called virtual memory makes this possible. Every time a process tries to access a memory location, the location (known as the virtual address) is translated to a physical address. Two processes can access the same virtual address, and yet this translation makes sure that they actually access two different physical addresses. Note that generally, an operating system is required to do this translation.
A process can fork. When it does this, the entire process is cloned. All values on the stack and heap are duplicated1, and we end up with two processes. After a fork, one of the two resulting processes can start doing different things. This is how all2 processes are created after the first process (often called the init process). The operating starts the first process, and it then forks (many times) to create all the processes on the system.
Because each process has its own memory, if one forked process writes to a global variable, the other process will not see this update. It has its own version of the variable.
Threads
A thread is like a process within a process. When a new thread is created, the new thread gets its own stack and own registers. But, unlike with forking, the memory space stays shared. That means that global variables stay shared, references from one thread are valid in another thread, and data can easily be exchanged by threads. Last lecture we have of course seen that this is not always desirable, for example, when this causes data races.
Even though threads semantically are part of a process, Linux actually treats processes and threads pretty much as equals. The scheduler, about which you'll hear about more after this, schedules both processes and threads.
Scheduler
Due to forking, or spawning threads, the operating system may need to manage tens, or hundreds of processes at once. Though modern computers can have quite large numbers of cores, usually not hundreds. To create the illusion of parallelism, the operating system uses a trick: it quickly alternates the execution of processes.
After a process runs for a while (on Linux this time is variable), the register state of the process are saved in memory, allowing a different process to run. If at some point the original process is chosen again to run, the registers are reverted to the same values they were when it was scheduled out. The process won't really notice that it didn't run for a while.
Even though the scheduler tries to be fair in the way it chooses processes to run, processes can communicate with the scheduler in several ways to modify how it schedules the process. For example:
- When a process sleeps for a while (
see
std::thread::sleep), the scheduler can immediately start running another process. The scheduler could even try to run the process again as close as possible to the sleep time requested. - A process can ask the scheduler to stop executing it, and instead run another thread or process. This can be useful
when a process has to wait in a loop for another thread to finish. Then it can give the other thread more time run.
See
std::thread::yield_now - Processes can have different priorities, in Linux this is called the niceness of a process.
- Sometimes, using a synchronization primitive may communicate with the scheduler to be more efficient. For example, when a thread is waiting for a lock, and the lock is released, the scheduler could schedule that thread next.
- When a process has to wait for an IO operation to run, it can ask the operating to system to be run again when the IO operation has completed. Rust can do this by using tokio for example.
Concurrency vs Parallelism
Sometimes, the words concurrency and parallelism are used interchangeably. However, their meanings are not the same. The difference is as follows: concurrency can exist on a system with a single core. It's simply the illusion of processes running at the same time. However, it may indeed be just an illusion. By alternating the processes, they don't run at the same time at all.
In contrast, parallelism is when two processes are indeed running at the same time. This is therefore only possible on a system with more than one core. However, even though not all system have parallelism, concurrency can still cause data races.
For example, let's look at the example from last lecture:
static int a = 3;
int main() {
a += 1;
}
What could happen on a single core machine where threads are run concurrently is the following:
- Thread 1 reads
aintoaregister - Thread 1 increments the register
- Thread 1 is scheduled out, and thread 2 is allowed to run
- Thread 2 read
ainto a register - Thread 2 increments the register
- Thread 2 writes the new value (of 4) back to memory
- Thread 2 is scheduled out, and thread 1 is allowed to run
- Thread 1 writes the new value (also 4) back to memory
Both threads have tried to increment a here, and yet the value is only 1 higher.
Channels
Up to now, we've looked at how we can share memory between threads. We often want this so that threads can coordinate or communicate in some way. You could call this communication by sharing memory. However, a different strategy sometimes makes sense. This started with C. A. R. Hoare's communicating sequential processes, but the Go programming language, a language in which concurrency plays a central role, likes to call this "sharing memory by communicating".
What it boils down to, is the following: sometimes it's very natural, or more logical, not to update one shared memory location, but instead to pass messages around. Let's look at an example to illustrate this:
fn some_expensive_operation() -> &'static str { "🦀" } use std::sync::mpsc::channel; use std::thread; fn main() { let (sender, receiver) = channel(); // Spawn off an expensive computation thread::spawn(move || { let result = some_expensive_operation(); sender.send(result).unwrap(); }); // Do some useful work for awhile // Let's see what that answer was println!("{}", receiver.recv().unwrap()); }
This example comes from the rust mpsc documentation.
Here we want to do some expensive operation, which may take a long time, and do it in the background. We spawn a thread to do it, and then want to do something else before it has finished. However, we don't know exactly how long the expensive operation will take. It may take shorter than doing some useful work, or longer.
So we use a channel. A channel is a way to pass messages between threads. In this case, the message is the result of the
expensive operation. When the operation has finished, the result is sent over the channel, at which point the useful work
may or may not be done already. If it wasn't done yet, the message is simply sent and the thread can exit. When finally
the receiver calls .recv() it will get the result from the channel, since it was already done. However, if the useful
work is done first, it will call .recv() early. However, there's no message yet. If this is the case, the receiving
end will wait until there is a message.
A channel works like a queue. Values are inserted on one end, and removed at the other end. But, with a channel, the ends are in different threads. The threads can use this to update each other about calculations that are performed. This turns out to be quite efficient, sometimes locking isn't even required to send messages. You can imagine that for example when there are many items in the queue, and one thread pops from one end but another push on the other, the threads don't even interfere with each other since they write and read data far away from each other. In reality, it's a bit more subtle, but this may give you some intuition on why this can be quite efficient.
Multi consumer and multi producer
You may have noticed that in Rust, channels are part of the std::sync::mpsc module. So what does mpsc mean?
It stands for multi-producer-single-consumer. Which is a statement about the type of channel it provides. When
you create a channel, you get a sender and a receiver, and these have different properties.
First, both senders are Send but not Sync. That means, they can be sent or moved to other threads, but they cannot be used at the same time from different threads. That means that if a thread wants to use a sender or receiver, it will need ownership of it.
Importantly, you cannot clone receivers. That effectively means that only one thread can have the receiver. On the other hand, you can clone senders. If a sender is cloned, it still sends data to the same receiver. Thus, it's possible that multiple threads send messages to a single consumer. That's what the name comes from: multi-producer single-consumer.
But that's not the only style of channel there is. For example, the crossbeam library (has all kinds of concurrent data structures) provides an mpmc channel. That means, there can be multiple consumers as well. However, every message is only sent to one of the consumers. Instead, multiqueue provides an mpmc channel where all messages are sent to all receivers. This is sometimes called a broadcast queue.
Bounded channels
In rust, by default, channels are unbounded. That means, senders can send as many messages as they like before a receiver needs to take messages out of the queue. Sometimes, this is not desired. You don't always want producers to work ahead far as this may fill up memory quickly, or maybe by working ahead the producers are causing the scheduler not to schedule the consumer(s) as often.
This is where bounded channels are useful. A bounded channel has a maximum size. If a sender tries to insert more items than this size, they have to wait for a receiver to take out an item first. This will block the sending thread, giving a receiving thread time to take out items. In effect, the size bound on the channel represents a maximum on how much senders can work ahead compared to the receiver.
A special case of this is the zero-size bounded channel. Here, a sender can never put any message in the channel's buffer. However, this is not always undesired. It simply means that the sender will wait until a sender can receive the message, and then it will pass the message directly to the receiver without going into a buffer. The channel now works like a barrier, forcing threads to synchronize. Both threads have to arrive to their respective send/recv points before a message can be exchanged. This causes a lock-step type behaviour where the producer produces one item, then waits for the consumer to consume one item.
Bounded channels are also sometimes called synchronous channels.
Atomics
Atomic variables are special variables on which we can perform operations atomically. That means that we can for example increment a value safely in multiple threads, and not lose counts like we saw in the previous lecture. In fact, because operations on atomics are atomic, we don't even need to make them mutable to modify them. This almost sounds too good to be true, and it is. Not all types can be atomic, because atomics require hardware support. Additionally, operating on them can be significantly slower than operating on normal variables.
I ran some benchmarks on my computer. None of them actually used multithreading, so you wouldn't actually need a mutex or an atomic here. However, it does show what the raw performance penalty of using atomics and mutexes is compared to not having one. When there is contention over the variable, speeds may differ a lot, but of course, not using either an atomic or mutex then isn't an option anymore. Also, each reported time is actually the time to do 10 000 increment operations, and in the actual benchmarked code I made sure that nothing was optimized out by the compiler artificially making code faster.
All tests were performed using criterion, and the times are averaged over many runs. Atomics seem roughly 5x slower than not using them, but about 2x faster than using a mutex.
#![allow(unused)] fn main() { // Collecting 100 samples in estimated 5.0037 s (1530150 iterations) // Benchmarking non-atomic: Analyzing // non-atomic time: [3.2609 µs 3.2639 µs 3.2675 µs] // Found 5 outliers among 100 measurements (5.00%) // 3 (3.00%) high mild // 2 (2.00%) high severe // slope [3.2609 µs 3.2675 µs] R^2 [0.9948771 0.9948239] // mean [3.2696 µs 3.2819 µs] std. dev. [20.367 ns 42.759 ns] // median [3.2608 µs 3.2705 µs] med. abs. dev. [10.777 ns 21.822 ns] fn increment(n: &mut usize) { *n += 1; } // Collecting 100 samples in estimated 5.0739 s (308050 iterations) // Benchmarking atomic: Analyzing // atomic time: [16.387 µs 16.408 µs 16.430 µs] // Found 4 outliers among 100 measurements (4.00%) // 4 (4.00%) high mild // slope [16.387 µs 16.430 µs] R^2 [0.9969321 0.9969237] // mean [16.385 µs 16.415 µs] std. dev. [63.884 ns 89.716 ns] // median [16.367 µs 16.389 µs] med. abs. dev. [33.934 ns 68.379 ns] fn increment_atomic(n: &AtomicUsize) { n.fetch_add(1, Ordering::Relaxed); } // Collecting 100 samples in estimated 5.1363 s (141400 iterations) // Benchmarking mutex: Analyzing // mutex time: [36.148 µs 36.186 µs 36.231 µs] // Found 32 outliers among 100 measurements (32.00%) // 16 (16.00%) low severe // 4 (4.00%) low mild // 6 (6.00%) high mild // 6 (6.00%) high severe // slope [36.148 µs 36.231 µs] R^2 [0.9970411 0.9969918] // mean [36.233 µs 36.289 µs] std. dev. [116.84 ns 166.02 ns] // median [36.267 µs 36.288 µs] med. abs. dev. [32.770 ns 75.978 ns] fn increment_mutex(n: &Mutex<usize>) { *n.lock() += 1; } }For atomics, I used the relaxed memory ordering here since the actual ordering really doesn't matter, as long as all operations occur. I did test with different orderings, and it made no difference here.
Atomics usually work using special instructions or instruction modifiers, which instruct the hardware to temporarily lock a certain memory address while an operation, like an addition, takes place. Often, this locking actually happens on the level of the memory caches. Temporarily, no other cores can update the values in the cache. Do note that this is an oversimplification, atomics are quite complex.
Operations on Atomics
To work with atomics variables, you often make use of some special operations defined on them. First, there are the "fetch" operations.
They perform an atomic fetch-modify-writeback sequence. For example, the .fetch_add(n) function on atomic integers, adds n to an atomic
integer by first fetching the value, then adding n to it, and then writing back (all atomically). There is a large list of such fetch operations.
For example, atomic integers define the following:
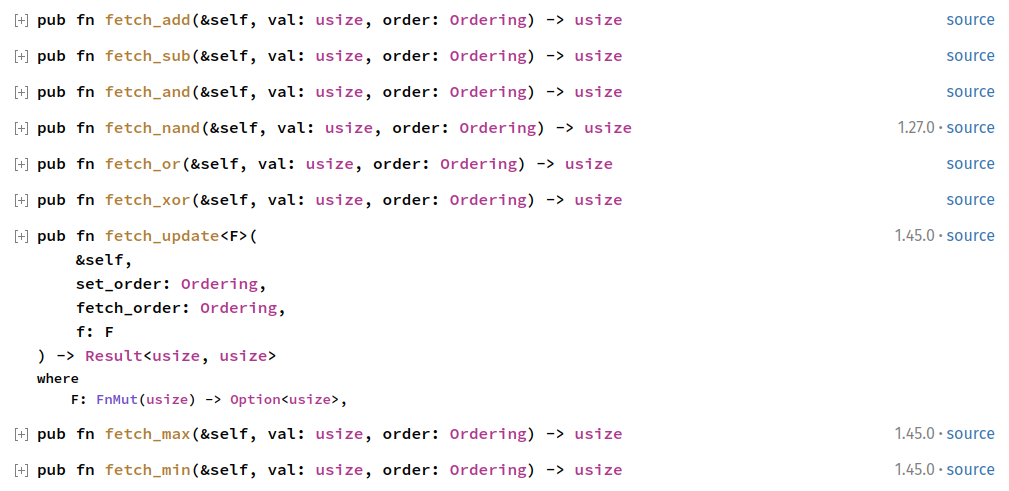
The other common operation on atomics is the compare-exchange operation. Let's look at a little real-world example. Let's implement a so-called spinlock (like a custom mutex, that simply waits in an infinite loop until the lock is available). It's quite a bad design, and inefficient, but it works nonetheless:
#![allow(unused)] fn main() { struct SpinLock<T> { locked: AtomicBool, // UnsafeCells can magically make immutable things mutable. // This is unsafe to do and requires us to use "unsafe" code. // But if we ensure we lock correctly, we can make it safe. value: UnsafeCell<T> } impl<T> SpinLock<T> { pub fn lock(&self) { while self.locked.compare_exchange(false, true).is_err() { std::thread::yield_now(); } // now it's safe to access `value` as mutable, since // we know the mutex is locked and we locked it self.locked.store(false); } } }
So what's happening here? locked is an atomic boolean. That means, that we can perform atomic operations on it.
When we want to lock the mutex (to access the value as mutable), we want to look if the lock is free. We use a compare exchange operation for this.
Compare exchange looks if the current value of an atomic is equal to the first argument, and if it is, it sets it equal to the second argument. So what's
happening here is that the compare_exchange looks if the value of locked is false (unlocked), and if so, set it to locked. If the value of locked was
indeed false, we just locked it and can continue. We know for sure we are the only thread accessing the value.
However, if we failed to do the exchange, another thread must have locked the lock already. In that case (when the compare_exchange returned an error), we execute
the loop body and retry again and again, until at some point another thread unlocks the mutex and the compare_exchange does succeed. The yield_now function makes
this all a bit more efficient, it tells the scheduler to give another thread some time. That increases the chance that in the next loop cycle the lock is unlocked.
Orderings
Because atomics can have side effects (in other threads for example), without needing to be mutable, the compiler cannot make certain assumptions about them automatically. Let's study the following example:
#![allow(unused)] fn main() { let mut x = 1; let y = 3; x = 2; }
The compiler may notice that the order of running x and y does not matter, and may reorder it to this:
#![allow(unused)] fn main() { let mut x = 1; x = 2; let y = 3; }
Or even this:
#![allow(unused)] fn main() { let mut x = 3; let y = 3; }
let y = 3 does not touch x, so the value of x is not actually important at that moment. However, with atomics, ordering
can be very important. When certain operations are reordered, compared to other operations, your logic may break. Let's say you
have a program like the following (this is pseudocode, not rust. All variables are atomic and can influence other threads):
#![allow(unused)] fn main() { // for another thread to work properly, v1 and v2 may // *never* be true at the same time v1 = false; v2 = true; // somewhere in the code v2 = false; v1 = true; }
Since between v2 = false and v1 = true, nothing uses either v1 or v2, the compiler may assume that setting
v1 and v2 can be reordered to what's shown below. Maybe that's more efficient.
#![allow(unused)] fn main() { // for another thread to work properly, v1 and v2 may // *never* be true at the same time v1 = false; v2 = true; // somewhere in the code v1 = true; // here, both v1 and v2 are true!!!!! v2 = false; }
However, since atomics may be shared between threads, another thread may briefly observe both v1 and v2 to be true
at the same time!
Therefore, when you update an atomic in Rust (and in other languages too, this system is pretty much copied from c++), you also need to specify what the ordering of that operation is. And not just to prevent the compiler reordering, some CPUs can actually also reorder the execution of instructions, and the compiler may need to insert special instructions to prevent this. Let's look on how to do that:
First let's look at the Relaxed ordering:
use std::sync::atomic::{Ordering, AtomicUsize}; fn main() { let a = AtomicUsize::new(0); let b = AtomicUsize::new(1); // stores the value 1 with the relaxed ordering a.store(1, Ordering::Relaxed); // adds 2 to the value in a with the relaxed ordering b.fetch_add(2, Ordering::Relaxed); }
Relaxed sets no requirements on the ordering of the store and the add. That means, that other threads may actually
see b change to 2 before they see a change to 1.
Memory ordering on a single variable (a single memory address) is always sequentially consistent within one thread. That means that with
#![allow(unused)] fn main() { let a = AtomicUsize::new(0); a.store(1, Ordering::Relaxed); a.fetch_add(2, Ordering::Relaxed); }Here the value of
awill first be 0, then 1 and then 3. But if the store and add were reordered, you may expect to see first 0, then 2 and then 3, suddenly the value 2 appears. However, this is not the case. Because both variables operate on the same variable, the operations will be sequentially consistent, and the variableawill never have the value 2.Orderings are only important to specify how the ordering between updates two different variables should appear to other threads, or how updates to the same variable in two different threads should appear to third threads.
This ordering is pretty important for the example above with the spinlock. Both the store and the compare_exchange take an ordering. In fact,
compare exchange actually takes two orderings (but the second ordering parameter can almost always be Relaxed.)
#![allow(unused)] fn main() { use std::sync::atomic::{AtomicBool, Ordering::*}; use std::cell::UnsafeCell; struct SpinLock<T> { locked: AtomicBool, // UnsafeCells can magically make immutable things mutable. // This is unsafe to do and requires us to use "unsafe" code. // But if we ensure we lock correctly, we can make it safe. value: UnsafeCell<T> } impl<T> SpinLock<T> { pub fn lock(&self) { while self.locked.compare_exchange(false, true, Relaxed, Relaxed).is_err() { std::thread::yield_now(); } // now it's safe to access `value` as mutable, since // we know the mutex is locked and we locked it self.locked.store(false, Relaxed); } } }
This code does not what we want it to do! If there are two threads (a and b) that both try to get this lock, and a third thread (c) currently holds the lock. It's possible that thread c unlocks the lock, and then both a and b at the same time see this, and both lock the lock.
To change this, we can use the SeqCst ordering. SeqCst makes sure that an operation appears sequentially consistent to other operations in other threads.
So when an operation X is SeqCst, all previous operations before X will not appear to other threads as happening after X, and all future operations
won't appear to other threads as happening before X. This is true, even if some of those other operations are not SeqCst. So for the spinlock, c will unlock
the lock, then, for example a could be first with trying to lock the lock. It will stop b from accessing the variable until it has completed the update.
And when a has updated the variable, the lock is locked and b will have to wait until the lock is unlocked again.
In general,
SeqCstshould be your default memory ordering. BecauseSeqcCstgives stronger guarantees to the ordering operations, it may make your program slightly slower than when you useRelaxed. However, even using sequentially consistent atomics will be a lot faster than using mutexes. AndSeqCst` will never accidentally produce the wrong result. The worst kind of bug is one where due to a wrong ordering, your program makes a mistake once in a million executions. That's almost impossible to debug.
For an actual spinlock, you'll actually not see SeqCst used often. Instead, there are two different orderings (Acquire and
Release, often used in pairs) which provide fever guarantees than SeqCst, but enough to implement these kinds of locks. Their
names actually come from what you use to implement a lock. To acquire a lock, you use Acquire ordering, and to release (unlock) a lock,
you use Release ordering. Acquire and Release operations form pairs, specifically ordering those correctly.
This can make code slightly faster.
Actually using different orderings can be quite complicated. If you want to know more, there have been loads of scientific papers about this. This one for example. And the Rust and C++ documentation about it aren't bad at all either.
The final spinlock implementation is as follows. Note again, that making a lock like this is often not such a good choice, and you should almost always use the one from the standard library.
#![allow(unused)] fn main() { use std::sync::atomic::{AtomicBool, Ordering::*}; use std::cell::UnsafeCell; struct SpinLock<T> { locked: AtomicBool, // UnsafeCells can magically make immutable things mutable. // This is unsafe to do and requires us to use "unsafe" code. // But if we ensure we lock correctly, we can make it safe. value: UnsafeCell<T> } impl<T> SpinLock<T> { pub fn lock(&self) { while self.locked.compare_exchange(false, true, Acquire, Relaxed).is_err() { std::thread::yield_now(); } // now it's safe to access `value` as mutable, since // we know the mutex is locked and we locked it self.locked.store(false, Release); } } }
After you have read this lecture, you are ready to work on assignment 1
Resources
-
On linux, values aren't actually cloned immediately. Only when one process modifies a value in a page, only that page will be cloned. Unmodified pages will stay shared to save memory. ↩
-
That's not entirely true. Operating systems have evolved, and new system calls exist now that optimize for example the common case in which a
forksystem call is immediately followed by anexecsystem call. ↩