Software Systems
This is the homepage for the software systems course. You can find most course information here.
This course is part of the CESE masters programme. This course is a continuation of the curriculum of Software Fundamentals and will help prepare you for the Embedded Systems Lab.
For students who did not follow Software Fundamentals
Software Fundamentals is marked as a prerequisite for Software Systems. On the course's website you can find the slides of the course, and read back from the provided lecture notes. The reason it's marked as a prerequisite, is that we expect that you know the basics of the Rust programming language before taking Software Systems.
Software fundamentals was a course exclusively for students that didn't already have a background in computer science. That's because we expect that if you did have a computer science background, you can pick up on Rust's properties pretty quickly from our notes and the rust book. We advise you to read through this, and invest a few hours to get acquainted with Rust before taking Software Systems. What may help is that the assignments of Software Fundamentals are still available on weblab. We won't manually grade any more solutions, but many assignments are fully automatically graded.
Part 1
This course consists of two parts over 8 weeks. The first 4 weeks will have weekly lectures and assignments. In part one, we will have 4 weeks, mainly about three subjects:
- Programming with concurrency
- Measuring and optimizing programs for performance
- Programming for embedded systems (without the standard library). We will spend 2 weeks on this.
This part will be taught by Vivian Roest.
For this part we recommend the book Rust Atomics and Locks by Mara Bos, as further reading material.
Part 2
In part two, which is the rest of the course, we will look at another 3 subjects related to model-based software development. We will cover the following main subjects:
- UML, a standardized modelling language to visualize the design of software
- Finite state machines.
- Domain specific languages and (rust) code generation based on them.
This second part will be taught by Rosilde Corvino and Guohao Lan
Deadlines
In both parts there will be exercises with roughly weekly deadlines. The first deadline for part 1 is already early, in the second week.
You do each assignment in a group of 2. This group will be the same for each assignment, and you can sign up for a group in Brightspace under the "collaboration" tab. After you do so, you get a gitlab repository with a template for the assignment within a day or so.
| Assignment | Graded | deadline always at 18:00 | Percentage of grade |
|---|---|---|---|
| PART ONE | |||
| 1 - Concurrency | ✅ | Wednesday, week 3 (27 nov) | 12.5% |
| 2 - Performance | ✅ | Wednesday, week 4 (4 dec) | 12.5% |
| 3 - Programming ES | ✅ | Wednesday, week 6 (18 dec) | 25.0% |
| PART TWO | |||
| 4 - UML | ✅ | Friday, week 7 (10 jan) | 10% |
| 5 - FSM | ✅ | Friday, week 8 (17 jan) | 10% |
| 6 - DSL | ✅ | Friday, week 10 (31 jan) | 10% |
| 7 - Reflection | ✅ | Friday, week 10 (31 jan) | 20% |
Note that you need a minimum grade of a 5.0 for each of the parts to pass this course.
All assignments (at least for part 1) are published at the start of the course. That means you could technically work ahead. However, note that we synchronized the assignments with the lectures. This means that if you do work ahead, you may be missing important context needed to do the assignments.
The time for the deadline for assignment 2 may look a lot shorter than the other deadlines. That's because we extended the deadline for assignment 1 to give you a little more time at the start of the course, not because the second deadline is actually much shorter.
Late Submissions
When you submit code after the deadline, we will grade you twice. Once on what work you did submit before the deadline, and once what you did after the deadline. However, we will cap the grade from after the deadline at a 6.0.
Labs
Every week (on Thursdays) there will be lab sessions with TAs. In these lab sessions you can ask questions and discuss problems you are having.
Lecture notes
Each lecture will have an associated document with an explanation of what is discussed in the slides. This document will be published under lecture notes. We call these the lecture notes. You can use these to study ahead (before the lecture) which we recommend, so you can ask more specific questions in the lectures. And we do invite you to ask lots of questions! However, in the case you could not make it to a lecture, it should also give you a lot of the information covered in the lectures in writing.
All lecture slides are also published here
Advent of Code
During this course, there will be the yearly advent of code. Every day, a new programming challenge is published, getting harder every day. It's quite fun, and great practice if you haven't been programming for that long yet! There is a course leaderboard with ID (
356604-2d88ced0).Note: this is just for fun. It's not mandatory at all.
Staff
The lectures of this course will be given by Vivian Roest during the first part of the course and by Rosilde Corvino and Guohao Lan during the second part.
During the labs you will mostly interact with the TA team
- George Hellouin de Menibus (Head TA)
- Pepijn Kremers
Contact
If you need to contact us, you can find us at the course email address: softw-syst-ewi@tudelft.nl.
For private matters related to the course, please direct your emails to: Vivian at v.c.roest@student.tudelft.nl, Guohao at G.Lan@tudelft.nl and Rosilde at rosilde.corvino@tno.nl
Note that we prefer that you use the course email address.
Lecture slides
Last Updated: 2024-12-19
Part 1
Part 2 (New)
- Lecture 5 (intro)
- Lecture 5 (UML, Use case, and component diagrams)
- Lecture 6 (Class and sequence diagrams)
- Lecture 7 (FSM)
- Lecture 8 (DSL and conclusion)
- Jupyter Notebook for UML
Part 2 (last year)
Slides will have changes from last year, but here they are anyways
- Lecture 5 (intro)
- Lecture 5 (UML, Use case diagrams)
- Lecture 6 (Class, component, deployment, and sequence diagrams)
- Lecture 7 (FSM basics)
- Lecture 7 (Composite states, history nodes, orthogonal states)
- Lecture 8 (DSL and conclusion)
Software Setup
Linux
Note on Ubuntu
If you have Ubuntu:
- Be aware that Ubuntu is not recommended by this course
- Carefully read the text below!
- DO NOT INSTALL
rustcorcargoTHROUGHapt. Install using official installation instructions and userustup- before installation, make sure you have
build-essential,libfontconfigandlibfontconfig1-devinstalled- Be prepared for annoying problems
We recommend you to use Linux for this course. It is not at all impossible to run the software on Windows or OSX, in fact, it might work quite well. However, not all parts of for example the final project have been tested on these systems.
Since everything has been tested on Linux, this is what we can best give support on. On other platforms, we cannot always guarantee this, although we will try!
If you're new to Linux, we highly recommend Fedora Linux to get started.
You might find that many online resources will recommend Ubuntu to get started, but especially for Rust development this
may prove to be a pain. If you install Rust through the official installer (rustup), it can work just fine on Ubuntu.
However, if you installed rust through apt it will not work.
Fedora also provides a gentle introduction to Linux, but will likely provide a better experience. For this course and for pretty much all other situations as well.
See Toolchain how to get all required packages.
Windows
If you really want to try and use Windows, please do so through WSL (Windows Subsystem for Linux). To do this, install "Fedora Linux" through the windows store and follow the editor specific setup to use WSL.
Toolchain
To start using rust, you will have to install a rust toolchain. To do so, you can follow the instructions on https://www.rust-lang.org/tools/install. The instructions there should be pretty clear, but if you have questions about it we recommend you ask about it in the labs.
To install all required packages for Fedora run the following:
sudo dnf install code rust cargo clang cmake fontconfig-devel
Warning
Do not install
rustcorcargothrough your package manager on Ubuntu, Pop_os!, Mint, Debian or derived linux distributions. Read our notes about these distros here and then come back.Due to their packaging rules, your installation will be horribly out of date and will not work as expected. On Fedora we have verified that installing rust through
dnfdoes work as expected. For other distributions follow the installation instructions above and do not use your package manager. See our notes on Linux.
Editor setup
To use any programming language, you need an editor to type text (programs) into. In theory, this can be any (plain-text) editor.
However, we have some recommendations for you.
CLion/Rust Rover (Jetbrains IDE)
In class, we will most likely be giving examples using Rust Rover. It is the editor some TAs for the course use. To use it you can get a free student-license at https://www.jetbrains.com/community/education/#students
You will have to download the rust plugin for CLion too. This is easy enough (through the settings menu), and CLion might even prompt you for it on installation. If you can't figure it out, feel free to ask a question in the labs.
If using Windows make sure to also follow the wsl specific documentation.
Visual Studio Code
Visual Studio Code (not to be confused with "visual studio") is an admittedly more light-weight editor that has a lot of the functionality CLion has too. In any case, the teachers and TAs have some experience using it so we can support you if things go wrong. You can easily find it online, you will need to install the "rust analyzer" plugin, which is actually written in Rust and is quite nice.
If using Windows make sure to also follow the wsl specific documentation.
Other
Any other editor (vim, emacs, ed) you like can be used, but note that the support you will get from teachers and TAs will be limited if at all. Do this on your own risk. If you're unfamiliar with programming tools or editors, we strongly recommend you use either CLion or VSCode.
Lecture Notes
Week 1
Week 2
Week 3
Week 4
Lecture 1.1
Contents
- Course Information
- Threads
- Data races
- Global variables and Data Race prevention in Rust
- Mutexes
- Mutexes in Rust
- Lock Poisoning
- Sharing heap-allocated values between threads
- Read-Write locks
Course Information
In this lecture we discussed the setup of the course and deadlines too. However, you can already find those on the homepage of this website
Threads
Most modern CPUs have more than one core. Which means that, in theory, a program can do more than a single thing at the same time. In practice this can be done by creating multiple processes or multiple threads within one process. How this works will be explained in lecture 1.2.
For now, you can think of threads as a method with which your program can execute multiple parts of your program at the same time. Even though the program is being executed in parallel, all threads still share the same memory * except* for their stacks1. That means that, for example, a global variable can be accessed by multiple threads.
Data races
This parallelism can cause a phenomenon called a data race. Let's look at the following C program:
static int a = 3;
int main() {
a += 1;
}
And let's now also look at the associated assembly:
main:
push rbp
mov rbp,rsp
mov eax,DWORD PTR [rip+0x2f18] # 404028 <a>
add eax,0x1
mov DWORD PTR [rip+0x2f0f],eax # 404028 <a>
mov eax,0x0
pop rbp
ret
Notice, that after some fiddling with the stack pointer, the += operation consists of three instructions:
- loading the value of
ainto a register (eax) - adding
1to that register - storing the result back into memory
However, what happens if more than one thread were to execute this program at the same time? The following could happen:
| thread 1 | thread 2 |
|---|---|
load the value of a into eax | load the value of a into eax |
add 1 to thread 1's eax | add 1 to thread 2's eax |
store the result in a | store the result in a |
Both threads ran the code to increment a. But even though a started at 3, and was incremented by both threads, the
final value of a if 4. Not 5. That's because both threads read the value of 3, added 1 to that, and both
stored back the value 4.
To practically demonstrate the result of such data races, we can look at the following c program:
#include <stdio.h>
#include <threads.h>
int v = 0;
void count(int * delta) {
// add delta to v 100 000 times
for (int i = 0; i < 100000; i++) {
v += *delta;
}
}
int main() {
thrd_t t1, t2;
int d1 = 1, d2 = -1;
// run the count function with delta=1
thrd_create(&t1, count, &d1);
// run the count function with delta=-1 at the same time
thrd_create(&t2, count, &d2);
thrd_join(t1, NULL);
thrd_join(t2, NULL);
printf("%d\n", v);
}
Since we increment and decrement v 100 000 times, you'd expect the result to be 0. However, that's not the case. You
can run this program yourself to see (just compile it with a compiler that supports C11), but I've run it a couple of
times and these were the results of my 8 runs:
| run 1 | run 2 | run 3 | run 4 | run 5 | run 6 | run 7 | run 8 |
|---|---|---|---|---|---|---|---|
-89346 | 28786 | 23767 | -83430 | -63039 | -15282 | -82377 | -65402 |
You see, the result is always different, and never 0. That's because some of the additions and subtractions are lost
due to data races. We will now look at why this happens.
Global variables and Data Race prevention in Rust
It turns out, sharing memory between threads is often an unsafe thing to do. Generally, there are two ways to share memory between threads. One option we've seen, where multiple threads access a global variable. The other possibility, is that two thread get a pointer or reference to a memory location that is for example on the heap, or on the stack of another thread.
Notice that for example, in the previous c program, the threads could have also modified the delta through the int *
passed in. The deltas for the two threads are stored on the stack of the main thread. But, because the c program never
updates the delta, it only reads the value, sharing the delta is something that's totally safe to do.
Thus, sharing memory between threads can be safe. As long as at most one thread can mutate the memory, all is fine!
In Rust, there's a rule that these mechanics may remind you of. If not, take a look at the lecture notes from Software Fundamentals. A piece of memory can, at any point in time, only be borrowed by a single mutable reference or any number of immutable references - references that cannot change what's stored at the location they reference. These rules make it fundamentally impossible to create a data race involving references to either the heap or another thread's stack.
But what about global variables? Can those still cause data races? Let's try to recreate the C program from above in Rust:
use std::thread; static mut v: i32 = 0; fn count(delta: i32) { for _ in 0..100_000 { v += delta; } } fn main() { let t1 = thread::spawn(|| count(1)); let t2 = thread::spawn(|| count(-1)); t1.join().unwrap(); t2.join().unwrap(); println!("{}", v); }
In Rust, you make a global variable by declaring it static, and we make it mutable, so we can modify it in
count(). thread::spawn creates threads, and .join() waits for the thread to finish. But, if you try compiling
this you will encounter an error:
error[E0133]: use of mutable static is unsafe and requires unsafe function or block
--> src/main.rs:31:9
|
31 | v += delta;
| ^^^^^^^^^^ use of mutable static
|
= note: mutable statics can be mutated by multiple threads:
aliasing violations or data races will cause undefined behavior
The error even helpfully mentions that this can cause data races.
Why then, can you even make a static variable mutable? If any access causes the program not to compile? Well, this
compilation error is actually one we can circumvent. We could put the modification of the global variable in
an unsafe block. We will talk about the exact behaviour of unsafe blocks in lecture 3
That means, we can make this program compile by modifying it like so:
use std::thread; static mut v: i32 = 0; fn count(delta: i32) { for _ in 0..100_000 { // add an unsafe block unsafe { v += delta; } } } fn main() { let t1 = thread::spawn(|| count(1)); let t2 = thread::spawn(|| count(-1)); t1.join().unwrap(); t2.join().unwrap(); // add an unsafe block unsafe { println!("{}", v); } }
Even though the program now compiles, we did introduce the same data race problem as we previously saw in C. This program will rarely give 0 as its result. Is there a way to solve this?
Mutexes
Let's first look how we can solve the original data race problem in C. What you can do to make sure data races do not occur, is to add a critical section. A critical section is a part of the program, in which you make sure that no other threads execute that part at the same time. One way to create a critical section is to use a mutex. A mutex's state can be seen as a boolean. It's either locked, or unlocked. A mutex can safely be shared between threads, and if one thread tries to lock the shared mutex, one of two things can occur:
- The mutex is unlocked. If this is the case, the mutex is immediately locked.
- The mutex is currently locked by another thread. The thread that tries to lock it has to wait.
If a thread has to wait to lock the thread, generally the thread is suspended such that it doesn't consume any CPU resources while it waits. The OS may schedule another thread that is not waiting on a lock.
However, what's important is that this locking operation is atomic. In other words, a mutex really can only be locked by one thread at a time without fear of data races. Let's go back to C and see how we would use a mutex there:
int v = 0;
mtx_t m;
void count(int * delta) {
for (int i = 0; i < 100000; i++) {
// start the critical section by locking m
mtx_lock(&m);
v += *delta;
// end the section by unlocking m. This is very important
mtx_unlock(&m);
}
}
int main() {
thrd_t t1, t2; int d1 = 1, d2 = -1;
// initialize the mutex.
mtx_init(&m, mtx_plain);
thrd_create(&t1, count, &d1);
thrd_create(&t2, count, &d2);
thrd_join(t1, NULL);
thrd_join(t2, NULL);
printf("%d\n", v);
}
The outcome of this program, in contrast to the original program, is always zero. That's because any time v is updated,
the mutex is locked first. If another thread starts executing the same code, it has to wait until the other thread unlocks it,
therefore the two threads can't update v at the same time.
But still, a lot of things can go wrong in this c program. For example, we need to make sure that any time we use v, we lock the mutex. If we forget it once, our program is unsafe. And if we forget to unlock the lock once? Well, then the program may get stuck forever.
Mutexes in Rust
In Rust, the process of using a mutex is slightly different. To start, a mutex and the variable it protects are not
separated. Intead of making a v and an m like in the C program above, we combine the two:
#![allow(unused)] fn main() { let a: Mutex<i32> = Mutex::new(0); }
Here, a is a mutex, and inside the mutex, an integer is stored. However, the storage location of our value within the
mutex is private. That means, you cannot access it from the outside. The only way to read or write the value inside a
mutex is to lock it. This conveniently makes a safety concern we'd have in C impossible: you can never update the
value without locking the mutex.
In Rust, the lock function returns a so-called mutex guard. Let's look at that:
use std::sync::Mutex; fn main() { let a: Mutex<i32> = Mutex::new(0); // locking returns a guard. we'll talk later at what the unwrap is for. let mut guard = a.lock().unwrap(); // the guard is a mutable pointer to the integer inside our mutex // that means we can use it to increment the value, from what was initially 0 *guard += 1; // the scope of the main function ends here. This drops the `guard` // variable, and automatically unlocks the mutex }
The guard both acts as a way to access the value inside the mutex, and as an indicator of how long to lock the mutex. As soon as the guard is dropped (i.e. goes out of scope), it automatically unlocks the mutex that it was associated with.
What may surprise you, is that we never declared a to be mutable. The reason mutability is important in Rust, is to
prevent data races and pointer aliasing. Both of those involve accessing the same piece of memory mutably at the same
time. But a mutex already prevents that: we can only lock a mutex once. That means that since using a mutex already
prevents both mutable aliasing and data races, so we don't really need the mutability rules for mutexes. This is all possible,
because the .lock() function does not need a mutable reference to the mutex. And that allows us to share references to this mutex safely between threads since Rust's rules would prevent us from sharing a mutable reference between threads.
With that knowledge, let's look at the an improved Rust version of the counter program:
use std::thread; use std::sync::Mutex; static v: Mutex<i32> = Mutex::new(0); fn count(delta: i32) { for _ in 0..100_000 { // add an unsafe block *v.lock().unwrap() += delta; } } fn main() { let t1 = thread::spawn(|| count(1)); let t2 = thread::spawn(|| count(-1)); t1.join().unwrap(); t2.join().unwrap(); // add an unsafe block println!("{}", v.lock().unwrap()); }
Lock Poisoning
You may notice that we need to use unwrap every time we lock. That's because lock returns
a Result. Which
means, it can fail. To learn why, we need to consider the case in which a program crashes while it holds a lock.
When a thread crashes (or panics, in Rust language), it doesn't crash other threads, nor will it exit the program. That means, that if another thread was waiting to acquire the lock, it may be stuck forever when the thread that previously had the lock crashed before unlocking it.
To prevent threads getting stuck like that, the lock is "poisoned" when a thread crashes while holding it. From that
moment onward, all other threads that try to lock the same lock, will fail to lock, and instead see the Err() variant of the
Result. And what does unwrap do? It crashes the thread when it sees an Err() variant. In effect, this makes sure that
if one thread crashes while holding the lock, all threads crash when acquiring the same lock. And even though crashing
may not be desired behaviour, it's a lot better than being stuck forever.
If you really want to make sure your threads don't crash when the lock is poisoned, you could handle the error by using matching. But, it's actually not considered bad practice to unwrap lock results.
Sharing heap-allocated values between threads
Sometimes, it's not desirable to use global variables to share information between threads. Instead, you may want to pass a reference to a local variable to a thread. For example, with the counter example we may want multiple pairs of threads to be counting up and down at the same time. But that's not possible when we use a global, since that's shared between all threads.
Let's look at how we may try to implement this:
use std::thread; use std::sync::Mutex; fn count(delta: i32, v: &Mutex<i32>) { for _ in 0..100_000 { *v.lock().unwrap() += delta } } fn main() { // v is a local variable let v = Mutex::new(0); // we pass an immutable reference to it to count // note: this is possible since locking doesn't require // a mutable reference let t1 = thread::spawn(|| count(1, &v)); let t2 = thread::spawn(|| count(-1, &v)); t1.join().unwrap(); t2.join().unwrap(); println!("{}", v.lock().unwrap()); }
But you'll find that this doesn't work. That's because it's possible for sub-threads to run for longer than the main
thread. It could be that main() has already returned and deallocated v before the counting has finished.
As it turns out, this isn't actually possible because we join the threads before that happens. But this is something Rust cannot track. Scoped threads could solve this, but let's first look into how to solve this without using scoped threads.
What we could do is allocate v on the heap. The heap will be around for the entire duration of the program, even
when main exits.
In Software Fundamentals
we have learned that we can do this by putting our value inside a Box.
fn main() { let v = Box::new(Mutex::new(0)); // rest }
But Box doesn't allow us to share its content between threads (or even two functions) because that would make it
impossible to figure out when to deallocate the value. If you think about it, if we share the value between the two
threads, which thread should free the value? The main thread potentially can't do it if it exited before the threads
did.
Rc and Arc
As an alternative to Box, there is the Rc type. It also allocates its contents on the heap, but it allows us to
reference those contents multiple times. So how does it know when to deallocate?
Rc stands for "reference counted". Reference counting means that every time we create a new reference to the Rc,
internally a counter goes up. On the flip side, every time we drop a reference, the counter goes down. When the counter reaches
zero, nothing references the Rc any more and the contents can safely be deallocated.
Let's look at an example:
use std::rc::Rc; fn create_vectors() -> (Rc<Vec<i32>>, Rc<Vec<i32>>) { // here we create a reference counted value with a vector in it // The reference count starts at 1, since a references the Vec let a = Rc::new(vec![1, 2, 3]); // here we clone a. Cloning an Rc doesn't clone the contents. // Instead, a new reference to the same Vec is created. Because // we create 2 more references here, at the end the reference // count is `3` let ref_1 = a.clone(); // doesn't clone the vec! only the reference! let ref_2 = a.clone(); // doesn't clone the vec! only the reference! // so here, the reference count is 3 // but only ref_1 and ref_2 are returned. Not a. // Instead, a is dropped at the end of the function. // But dropping a won't deallocate the Vector since the // reference count is still 2. (ref_1, ref_2) } fn main() { // here we put ref_1 and ref_2 in a and b. // However, both a and b refer to the same vector, // with a reference count of 2. let (a, b) = create_vectors(); // Both are the same vector println!("{:?}", a); println!("{:?}", b); // here, finally both a and b are dropped. This makes the // reference count first go down to 1, (when a is dropped) // and then to 0. When b is dropped, it notices the reference // count reaching zero and it frees the vector since it is now. // sure nothing else references the vector anymore }
To avoid data races, an Rc does not allow you to mutate its internals. If you want to anyway, we could use a Mutex again
since a Mutex allows us to modify an immutable value by locking.
Note that an
Rcis slightly less efficient than using normal references orBoxes. That's because every time you clone anRcor drop anRc, the reference count needs to be updated.
Send and Sync
Let's try to write the original counter example with a reference counted local variable:
use std::rc::Rc; use std::sync::Mutex; use std::thread; fn count(delta: i32, v: Rc<Mutex<i32>>) { for i in 0..100_000 { *v.lock().unwrap() += delta } } fn main() { // make an Rc let v = Rc::new(Mutex::new(0)); // clone it twice for our two threads let (v1, v2) = (v.clone(), v.clone()); // start the counting as we have done before let t1 = thread::spawn(|| count(1, v1)); let t2 = thread::spawn(|| count(-1, v2)); t1.join().unwrap(); t2.join().unwrap(); println!("{}", v.lock().unwrap()); }
You will find that this still does not compile! As it turns out, it is not safe for us to send an Rc from one thread
to another or to use one concurrently from multiple threads. That's because every time an Rc is cloned or dropped, the
reference counter has to be updated. If we make mistakes with that, we might free the contained value too early, or not
at all. But if we update the reference count from multiple threads, we could create a data race again. We can solve this
by substituting our Rc for an Arc.
Just like an Rc is slightly less efficient than a Box, an Arc is slightly less efficient than an Rc. That's because
when you clone an Arc, the reference count is atomically updated. In other words, it uses a critical section to prevent
data races (though it doesn't actually use a mutex, it's a bit smarter than that).
use std::sync::{Arc, Mutex}; use std::thread; fn count(delta: i32, v: Arc<Mutex<i32>>) { for i in 0..100_000 { *v.lock().unwrap() += delta } } fn main() { // make an Rc let v = Arc::new(Mutex::new(0)); // clone it twice for our two threads let (v1, v2) = (v.clone(), v.clone()); // start the counting as we have done before let t1 = thread::spawn(|| count(1, v1)); let t2 = thread::spawn(|| count(-1, v2)); t1.join().unwrap(); t2.join().unwrap(); println!("{}", v.lock().unwrap()); }
And finally, our program works!
But there is another lesson to be learned here: Apparently, some datatypes can only work safely when they are
contained within a single thread. An Rc is an example of this, but there's also Cells and RefCells, and
for example, you also can't really move GPU rendering contexts between threads.
In Rust, there are two traits (properties of types): Send and Sync that govern this.
- A type has the
Sendproperty, if it's safe for it to be sent to another thread - A type has the
Syncproperty, if it's safe for it to live in one thread, and be referenced and read from in another thread.
An Rc is neither Send nor Sync, while an Arc is both as long as the value in the Arc is also Send and Sync.
Send and Sync are automatically implemented for almost any type. A type only doesn't automatically get
these properties if the type explicitly opts out of being Send or Sync, or if one of the members of the type
isn't Send or Sync.
For example, an integer is both Send and Sync, and so is a struct only containing integers.
But an Rc explicitly opts out of being Send and Sync:
#![allow(unused)] fn main() { // from the rust standard library impl<T: ?Sized> !Send for Rc<T> {} impl<T: ?Sized> !Sync for Rc<T> {} }
And a struct with in it an Rc:
#![allow(unused)] fn main() { use std::rc::Rc; struct Example { some_field: Rc<i64>, } }
is also not Send and not Sync.
It is possible for a type to be only Send or only Sync if that's required.
Scoped threads
In Rust 1.63, a new feature was introduced named scoped threads. This allows you to tell the compiler that threads must terminate before the end of a function. And that means, it becomes safe to share local variables with threads.
Let us, for the last time, look at the counter example, but implement it without having to allocate a reference counted type on the heap:
use std::sync::Mutex; use std::thread; fn count(delta: i32, v: &Mutex<i32>) { for i in 0..100_000 { *v.lock().unwrap() += delta } } fn main() { let v = Mutex::new(0); // create a scope thread::scope(|s| { // within the scope, spawn two threads s.spawn(|| count(1, &v)); s.spawn(|| count(-1, &v)); // at the end of the scope, the scope automatically // waits for the two threads to exit }); // here the threads have *definitely* exited. // and `v` is still alive here. println!("{}", v.lock().unwrap()); }
Because the scope guarantees the threads to exit before the main thread does, it's safe to borrow variables from the local scope of the main function. This means that allocating on the heap becomes unnecessary.
Read-Write locks
In some cases, a Mutex is not the most efficient locking primitive to use. Usually that's when a lock is read way more
often than it's written to. Any time the code wants to read from a Mutex, it has to lock it, disallowing any other
threads to either read or write to it. But when a thread just want to read from a
Mutex, it's perfectly safe for other threads to also read from it at the same time. This is the problem that
an std::sync::RwLock solves. It's like a Mutex, but has two different lock functions. read (which returns an
immutable reference to its internals) and write, which works like lock on mutexes. A RwLock allows multiple
threads to call read at the same time. You can find more documentation at
them here.
-
Technically there are also thread-local variables which are global, but also not shared between threads. Instead, every thread will get its own copy of the variable. ↩
Lecture 1.2
Contents
Programs, processes and threads
Programs
Before we continue talking about threads, it's useful to talk about some definitions. Namely, what exactly is the difference between a program, a process and a thread.
Let's start with programs. Programs are sequences of instructions, often combined with static data. Programs usually live in files, sometimes uncompiled (source code), sometimes compiled. Usually, when a language directly executes source code, we call this an interpreted language. Interpreted language usually rely on some kind of runtime that can execute the source code. This runtime is usually a compiled program.
When a program is stored after it is compiled, we usually call that a "binary". The format of a binary may vary. When there's an operating system around, it usually wants binaries in a specific format. For example, on Linux, binaries are usually stored in the ELF format. However, especially if you are running code on a system without an operating system, the compiled program is sometimes literally a byte-for-byte copy of the representation of that program in the memory of the system that will run the program. From now on, when we talk about a program running under an operating system, you can assume that that operating system is Linux. The explanation is roughly equivalent for other operating systems, but details may vary.
Processes
When you ask Linux to run a program, it will create a process. A process is an instance of a program. This instantiation is called loading a program, and the operating system will initialize things like the stack (pointer) and program counter such that the program can start running. Each process has its own registers, own stack, and own heap.
Each process can also assume that it owns the entirety of memory. This is of course not true, there are other processes also running, also using parts of memory. A system called virtual memory makes this possible. Every time a process tries to access a memory location, the location (known as the virtual address) is translated to a physical address. Two processes can access the same virtual address, and yet this translation makes sure that they actually access two different physical addresses. Note that generally, an operating system is required to do this translation.
A process can fork. When it does this, the entire process is cloned. All values on the stack and heap are duplicated1, and we end up with two processes. After a fork, one of the two resulting processes can start doing different things. This is how all2 processes are created after the first process (often called the init process). The operating starts the first process, and it then forks (many times) to create all the processes on the system.
Because each process has its own memory, if one forked process writes to a global variable, the other process will not see this update. It has its own version of the variable.
Threads
A thread is like a process within a process. When a new thread is created, the new thread gets its own stack and own registers. But, unlike with forking, the memory space stays shared. That means that global variables stay shared, references from one thread are valid in another thread, and data can easily be exchanged by threads. Last lecture we have of course seen that this is not always desirable, for example, when this causes data races.
Even though threads semantically are part of a process, Linux actually treats processes and threads pretty much as equals. The scheduler, about which you'll hear about more after this, schedules both processes and threads.
Scheduler
Due to forking, or spawning threads, the operating system may need to manage tens, or hundreds of processes at once. Though modern computers can have quite large numbers of cores, usually not hundreds. To create the illusion of parallelism, the operating system uses a trick: it quickly alternates the execution of processes.
After a process runs for a while (on Linux this time is variable), the register state of the process are saved in memory, allowing a different process to run. If at some point the original process is chosen again to run, the registers are reverted to the same values they were when it was scheduled out. The process won't really notice that it didn't run for a while.
Even though the scheduler tries to be fair in the way it chooses processes to run, processes can communicate with the scheduler in several ways to modify how it schedules the process. For example:
- When a process sleeps for a while (
see
std::thread::sleep), the scheduler can immediately start running another process. The scheduler could even try to run the process again as close as possible to the sleep time requested. - A process can ask the scheduler to stop executing it, and instead run another thread or process. This can be useful
when a process has to wait in a loop for another thread to finish. Then it can give the other thread more time run.
See
std::thread::yield_now - Processes can have different priorities, in Linux this is called the niceness of a process.
- Sometimes, using a synchronization primitive may communicate with the scheduler to be more efficient. For example, when a thread is waiting for a lock, and the lock is released, the scheduler could schedule that thread next.
- When a process has to wait for an IO operation to run, it can ask the operating to system to be run again when the IO operation has completed. Rust can do this by using tokio for example.
Concurrency vs Parallelism
Sometimes, the words concurrency and parallelism are used interchangeably. However, their meanings are not the same. The difference is as follows: concurrency can exist on a system with a single core. It's simply the illusion of processes running at the same time. However, it may indeed be just an illusion. By alternating the processes, they don't run at the same time at all.
In contrast, parallelism is when two processes are indeed running at the same time. This is therefore only possible on a system with more than one core. However, even though not all system have parallelism, concurrency can still cause data races.
For example, let's look at the example from last lecture:
static int a = 3;
int main() {
a += 1;
}
What could happen on a single core machine where threads are run concurrently is the following:
- Thread 1 reads
aintoaregister - Thread 1 increments the register
- Thread 1 is scheduled out, and thread 2 is allowed to run
- Thread 2 read
ainto a register - Thread 2 increments the register
- Thread 2 writes the new value (of 4) back to memory
- Thread 2 is scheduled out, and thread 1 is allowed to run
- Thread 1 writes the new value (also 4) back to memory
Both threads have tried to increment a here, and yet the value is only 1 higher.
Channels
Up to now, we've looked at how we can share memory between threads. We often want this so that threads can coordinate or communicate in some way. You could call this communication by sharing memory. However, a different strategy sometimes makes sense. This started with C. A. R. Hoare's communicating sequential processes, but the Go programming language, a language in which concurrency plays a central role, likes to call this "sharing memory by communicating".
What it boils down to, is the following: sometimes it's very natural, or more logical, not to update one shared memory location, but instead to pass messages around. Let's look at an example to illustrate this:
fn some_expensive_operation() -> &'static str { "🦀" } use std::sync::mpsc::channel; use std::thread; fn main() { let (sender, receiver) = channel(); // Spawn off an expensive computation thread::spawn(move || { let result = some_expensive_operation(); sender.send(result).unwrap(); }); // Do some useful work for awhile // Let's see what that answer was println!("{}", receiver.recv().unwrap()); }
This example comes from the rust mpsc documentation.
Here we want to do some expensive operation, which may take a long time, and do it in the background. We spawn a thread to do it, and then want to do something else before it has finished. However, we don't know exactly how long the expensive operation will take. It may take shorter than doing some useful work, or longer.
So we use a channel. A channel is a way to pass messages between threads. In this case, the message is the result of the
expensive operation. When the operation has finished, the result is sent over the channel, at which point the useful work
may or may not be done already. If it wasn't done yet, the message is simply sent and the thread can exit. When finally
the receiver calls .recv() it will get the result from the channel, since it was already done. However, if the useful
work is done first, it will call .recv() early. However, there's no message yet. If this is the case, the receiving
end will wait until there is a message.
A channel works like a queue. Values are inserted on one end, and removed at the other end. But, with a channel, the ends are in different threads. The threads can use this to update each other about calculations that are performed. This turns out to be quite efficient, sometimes locking isn't even required to send messages. You can imagine that for example when there are many items in the queue, and one thread pops from one end but another push on the other, the threads don't even interfere with each other since they write and read data far away from each other. In reality, it's a bit more subtle, but this may give you some intuition on why this can be quite efficient.
Multi consumer and multi producer
You may have noticed that in Rust, channels are part of the std::sync::mpsc module. So what does mpsc mean?
It stands for multi-producer-single-consumer. Which is a statement about the type of channel it provides. When
you create a channel, you get a sender and a receiver, and these have different properties.
First, both senders are Send but not Sync. That means, they can be sent or moved to other threads, but they cannot be used at the same time from different threads. That means that if a thread wants to use a sender or receiver, it will need ownership of it.
Importantly, you cannot clone receivers. That effectively means that only one thread can have the receiver. On the other hand, you can clone senders. If a sender is cloned, it still sends data to the same receiver. Thus, it's possible that multiple threads send messages to a single consumer. That's what the name comes from: multi-producer single-consumer.
But that's not the only style of channel there is. For example, the crossbeam library (has all kinds of concurrent data structures) provides an mpmc channel. That means, there can be multiple consumers as well. However, every message is only sent to one of the consumers. Instead, multiqueue provides an mpmc channel where all messages are sent to all receivers. This is sometimes called a broadcast queue.
Bounded channels
In rust, by default, channels are unbounded. That means, senders can send as many messages as they like before a receiver needs to take messages out of the queue. Sometimes, this is not desired. You don't always want producers to work ahead far as this may fill up memory quickly, or maybe by working ahead the producers are causing the scheduler not to schedule the consumer(s) as often.
This is where bounded channels are useful. A bounded channel has a maximum size. If a sender tries to insert more items than this size, they have to wait for a receiver to take out an item first. This will block the sending thread, giving a receiving thread time to take out items. In effect, the size bound on the channel represents a maximum on how much senders can work ahead compared to the receiver.
A special case of this is the zero-size bounded channel. Here, a sender can never put any message in the channel's buffer. However, this is not always undesired. It simply means that the sender will wait until a sender can receive the message, and then it will pass the message directly to the receiver without going into a buffer. The channel now works like a barrier, forcing threads to synchronize. Both threads have to arrive to their respective send/recv points before a message can be exchanged. This causes a lock-step type behaviour where the producer produces one item, then waits for the consumer to consume one item.
Bounded channels are also sometimes called synchronous channels.
Atomics
Atomic variables are special variables on which we can perform operations atomically. That means that we can for example increment a value safely in multiple threads, and not lose counts like we saw in the previous lecture. In fact, because operations on atomics are atomic, we don't even need to make them mutable to modify them. This almost sounds too good to be true, and it is. Not all types can be atomic, because atomics require hardware support. Additionally, operating on them can be significantly slower than operating on normal variables.
I ran some benchmarks on my computer. None of them actually used multithreading, so you wouldn't actually need a mutex or an atomic here. However, it does show what the raw performance penalty of using atomics and mutexes is compared to not having one. When there is contention over the variable, speeds may differ a lot, but of course, not using either an atomic or mutex then isn't an option anymore. Also, each reported time is actually the time to do 10 000 increment operations, and in the actual benchmarked code I made sure that nothing was optimized out by the compiler artificially making code faster.
All tests were performed using criterion, and the times are averaged over many runs. Atomics seem roughly 5x slower than not using them, but about 2x faster than using a mutex.
#![allow(unused)] fn main() { // Collecting 100 samples in estimated 5.0037 s (1530150 iterations) // Benchmarking non-atomic: Analyzing // non-atomic time: [3.2609 µs 3.2639 µs 3.2675 µs] // Found 5 outliers among 100 measurements (5.00%) // 3 (3.00%) high mild // 2 (2.00%) high severe // slope [3.2609 µs 3.2675 µs] R^2 [0.9948771 0.9948239] // mean [3.2696 µs 3.2819 µs] std. dev. [20.367 ns 42.759 ns] // median [3.2608 µs 3.2705 µs] med. abs. dev. [10.777 ns 21.822 ns] fn increment(n: &mut usize) { *n += 1; } // Collecting 100 samples in estimated 5.0739 s (308050 iterations) // Benchmarking atomic: Analyzing // atomic time: [16.387 µs 16.408 µs 16.430 µs] // Found 4 outliers among 100 measurements (4.00%) // 4 (4.00%) high mild // slope [16.387 µs 16.430 µs] R^2 [0.9969321 0.9969237] // mean [16.385 µs 16.415 µs] std. dev. [63.884 ns 89.716 ns] // median [16.367 µs 16.389 µs] med. abs. dev. [33.934 ns 68.379 ns] fn increment_atomic(n: &AtomicUsize) { n.fetch_add(1, Ordering::Relaxed); } // Collecting 100 samples in estimated 5.1363 s (141400 iterations) // Benchmarking mutex: Analyzing // mutex time: [36.148 µs 36.186 µs 36.231 µs] // Found 32 outliers among 100 measurements (32.00%) // 16 (16.00%) low severe // 4 (4.00%) low mild // 6 (6.00%) high mild // 6 (6.00%) high severe // slope [36.148 µs 36.231 µs] R^2 [0.9970411 0.9969918] // mean [36.233 µs 36.289 µs] std. dev. [116.84 ns 166.02 ns] // median [36.267 µs 36.288 µs] med. abs. dev. [32.770 ns 75.978 ns] fn increment_mutex(n: &Mutex<usize>) { *n.lock() += 1; } }For atomics, I used the relaxed memory ordering here since the actual ordering really doesn't matter, as long as all operations occur. I did test with different orderings, and it made no difference here.
Atomics usually work using special instructions or instruction modifiers, which instruct the hardware to temporarily lock a certain memory address while an operation, like an addition, takes place. Often, this locking actually happens on the level of the memory caches. Temporarily, no other cores can update the values in the cache. Do note that this is an oversimplification, atomics are quite complex.
Operations on Atomics
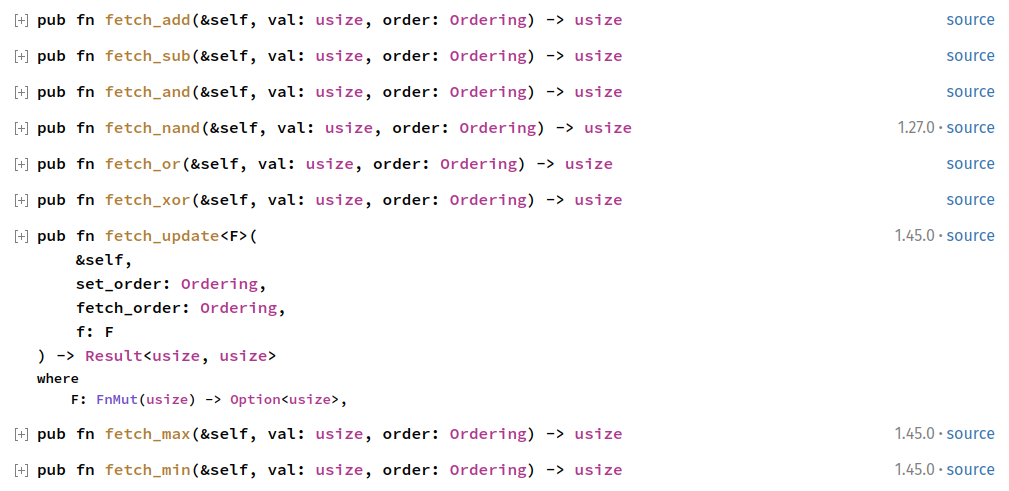
To work with atomics variables, you often make use of some special operations defined on them. First, there are the "fetch" operations.
They perform an atomic fetch-modify-writeback sequence. For example, the .fetch_add(n) function on atomic integers, adds n to an atomic
integer by first fetching the value, then adding n to it, and then writing back (all atomically). There is a large list of such fetch operations.
For example, atomic integers define the following:
The other common operation on atomics is the compare-exchange operation. Let's look at a little real-world example. Let's implement a so-called spinlock (like a custom mutex, that simply waits in an infinite loop until the lock is available). It's quite a bad design, and inefficient, but it works nonetheless:
#![allow(unused)] fn main() { struct SpinLock<T> { locked: AtomicBool, // UnsafeCells can magically make immutable things mutable. // This is unsafe to do and requires us to use "unsafe" code. // But if we ensure we lock correctly, we can make it safe. value: UnsafeCell<T> } impl<T> SpinLock<T> { pub fn lock(&self) { while self.locked.compare_exchange(false, true).is_err() { std::thread::yield_now(); } // now it's safe to access `value` as mutable, since // we know the mutex is locked and we locked it self.locked.store(false); } } }
So what's happening here? locked is an atomic boolean. That means, that we can perform atomic operations on it.
When we want to lock the mutex (to access the value as mutable), we want to look if the lock is free. We use a compare exchange operation for this.
Compare exchange looks if the current value of an atomic is equal to the first argument, and if it is, it sets it equal to the second argument. So what's
happening here is that the compare_exchange looks if the value of locked is false (unlocked), and if so, set it to locked. If the value of locked was
indeed false, we just locked it and can continue. We know for sure we are the only thread accessing the value.
However, if we failed to do the exchange, another thread must have locked the lock already. In that case (when the compare_exchange returned an error), we execute
the loop body and retry again and again, until at some point another thread unlocks the mutex and the compare_exchange does succeed. The yield_now function makes
this all a bit more efficient, it tells the scheduler to give another thread some time. That increases the chance that in the next loop cycle the lock is unlocked.
Orderings
Because atomics can have side effects (in other threads for example), without needing to be mutable, the compiler cannot make certain assumptions about them automatically. Let's study the following example:
#![allow(unused)] fn main() { let mut x = 1; let y = 3; x = 2; }
The compiler may notice that the order of running x and y does not matter, and may reorder it to this:
#![allow(unused)] fn main() { let mut x = 1; x = 2; let y = 3; }
Or even this:
#![allow(unused)] fn main() { let mut x = 3; let y = 3; }
let y = 3 does not touch x, so the value of x is not actually important at that moment. However, with atomics, ordering
can be very important. When certain operations are reordered, compared to other operations, your logic may break. Let's say you
have a program like the following (this is pseudocode, not rust. All variables are atomic and can influence other threads):
#![allow(unused)] fn main() { // for another thread to work properly, v1 and v2 may // *never* be true at the same time v1 = false; v2 = true; // somewhere in the code v2 = false; v1 = true; }
Since between v2 = false and v1 = true, nothing uses either v1 or v2, the compiler may assume that setting
v1 and v2 can be reordered to what's shown below. Maybe that's more efficient.
#![allow(unused)] fn main() { // for another thread to work properly, v1 and v2 may // *never* be true at the same time v1 = false; v2 = true; // somewhere in the code v1 = true; // here, both v1 and v2 are true!!!!! v2 = false; }
However, since atomics may be shared between threads, another thread may briefly observe both v1 and v2 to be true
at the same time!
Therefore, when you update an atomic in Rust (and in other languages too, this system is pretty much copied from c++), you also need to specify what the ordering of that operation is. And not just to prevent the compiler reordering, some CPUs can actually also reorder the execution of instructions, and the compiler may need to insert special instructions to prevent this. Let's look on how to do that:
First let's look at the Relaxed ordering:
use std::sync::atomic::{Ordering, AtomicUsize}; fn main() { let a = AtomicUsize::new(0); let b = AtomicUsize::new(1); // stores the value 1 with the relaxed ordering a.store(1, Ordering::Relaxed); // adds 2 to the value in a with the relaxed ordering b.fetch_add(2, Ordering::Relaxed); }
Relaxed sets no requirements on the ordering of the store and the add. That means, that other threads may actually
see b change to 2 before they see a change to 1.
Memory ordering on a single variable (a single memory address) is always sequentially consistent within one thread. That means that with
#![allow(unused)] fn main() { let a = AtomicUsize::new(0); a.store(1, Ordering::Relaxed); a.fetch_add(2, Ordering::Relaxed); }Here the value of
awill first be 0, then 1 and then 3. But if the store and add were reordered, you may expect to see first 0, then 2 and then 3, suddenly the value 2 appears. However, this is not the case. Because both variables operate on the same variable, the operations will be sequentially consistent, and the variableawill never have the value 2.Orderings are only important to specify how the ordering between updates two different variables should appear to other threads, or how updates to the same variable in two different threads should appear to third threads.
This ordering is pretty important for the example above with the spinlock. Both the store and the compare_exchange take an ordering. In fact,
compare exchange actually takes two orderings (but the second ordering parameter can almost always be Relaxed.)
#![allow(unused)] fn main() { use std::sync::atomic::{AtomicBool, Ordering::*}; use std::cell::UnsafeCell; struct SpinLock<T> { locked: AtomicBool, // UnsafeCells can magically make immutable things mutable. // This is unsafe to do and requires us to use "unsafe" code. // But if we ensure we lock correctly, we can make it safe. value: UnsafeCell<T> } impl<T> SpinLock<T> { pub fn lock(&self) { while self.locked.compare_exchange(false, true, Relaxed, Relaxed).is_err() { std::thread::yield_now(); } // now it's safe to access `value` as mutable, since // we know the mutex is locked and we locked it self.locked.store(false, Relaxed); } } }
This code does not what we want it to do! If there are two threads (a and b) that both try to get this lock, and a third thread (c) currently holds the lock. It's possible that thread c unlocks the lock, and then both a and b at the same time see this, and both lock the lock.
To change this, we can use the SeqCst ordering. SeqCst makes sure that an operation appears sequentially consistent to other operations in other threads.
So when an operation X is SeqCst, all previous operations before X will not appear to other threads as happening after X, and all future operations
won't appear to other threads as happening before X. This is true, even if some of those other operations are not SeqCst. So for the spinlock, c will unlock
the lock, then, for example a could be first with trying to lock the lock. It will stop b from accessing the variable until it has completed the update.
And when a has updated the variable, the lock is locked and b will have to wait until the lock is unlocked again.
In general,
SeqCstshould be your default memory ordering. BecauseSeqcCstgives stronger guarantees to the ordering operations, it may make your program slightly slower than when you useRelaxed. However, even using sequentially consistent atomics will be a lot faster than using mutexes. AndSeqCst` will never accidentally produce the wrong result. The worst kind of bug is one where due to a wrong ordering, your program makes a mistake once in a million executions. That's almost impossible to debug.
For an actual spinlock, you'll actually not see SeqCst used often. Instead, there are two different orderings (Acquire and
Release, often used in pairs) which provide fever guarantees than SeqCst, but enough to implement these kinds of locks. Their
names actually come from what you use to implement a lock. To acquire a lock, you use Acquire ordering, and to release (unlock) a lock,
you use Release ordering. Acquire and Release operations form pairs, specifically ordering those correctly.
This can make code slightly faster.
Actually using different orderings can be quite complicated. If you want to know more, there have been loads of scientific papers about this. This one for example. And the Rust and C++ documentation about it aren't bad at all either.
The final spinlock implementation is as follows. Note again, that making a lock like this is often not such a good choice, and you should almost always use the one from the standard library.
#![allow(unused)] fn main() { use std::sync::atomic::{AtomicBool, Ordering::*}; use std::cell::UnsafeCell; struct SpinLock<T> { locked: AtomicBool, // UnsafeCells can magically make immutable things mutable. // This is unsafe to do and requires us to use "unsafe" code. // But if we ensure we lock correctly, we can make it safe. value: UnsafeCell<T> } impl<T> SpinLock<T> { pub fn lock(&self) { while self.locked.compare_exchange(false, true, Acquire, Relaxed).is_err() { std::thread::yield_now(); } // now it's safe to access `value` as mutable, since // we know the mutex is locked and we locked it self.locked.store(false, Release); } } }
After you have read this lecture, you are ready to work on assignment 1
Resources
-
On linux, values aren't actually cloned immediately. Only when one process modifies a value in a page, only that page will be cloned. Unmodified pages will stay shared to save memory. ↩
-
That's not entirely true. Operating systems have evolved, and new system calls exist now that optimize for example the common case in which a
forksystem call is immediately followed by anexecsystem call. ↩
Lecture 2
This lecture can be seen as a summary of the Rust performance book. Although this lecture is independently created from that book, the Rust performance book is a good resource, and you will see many of the concepts described here come back in-depth there. These lecture notes strictly follow the live lectures, so we may skip one or two things that may interest you in the Rust performance book. We highly recommend you to use it when doing Assignment 2
Contents
- Benchmarking
- Profiling
- What does performance mean?
- Making code faster by being clever
- Calling it less
- Making existing programs faster
- Resources
Benchmarking
Rust is often regarded as quite a performant programming language. Just like C and C++, Rust code is compiled into native machine code, which your processor can directly execute. That gives Rust a leg up over languages like Java or Python, which require a costly runtime and virtual machine in which they execute. But having a fast language certainly doesn't say everything.
The reason is that the fastest infinite loop in the world is still slower than any program that terminates. That's a bit hyperbolic of course, but simply the fact that Rust is considered a fast language, doesn not mean that any program you write in it is immediately as fast as it can be. In these notes, we will talk about some techniques to improve your Rust code and how to find what is slowing it down.
Initially, it is important to learn about how to identify slow code. We can use benchmarks for this. A very useful tool to
make benchmarks for rust code is called criterion.
Criterion itself has lots of documentation on how to use it. Let's look at a little example from the documentation.
Below, we benchmark a simple function that calculates Fibonacci numbers:
use criterion::{black_box, criterion_group, criterion_main, Criterion};
fn fibonacci(n: u64) -> u64 {
match n {
0 => 1,
1 => 1,
n => fibonacci(n-1) + fibonacci(n-2),
}
}
pub fn fibonacci_benchmark(c: &mut Criterion) {
c.bench_function("benchmarking fibonacci", |b| {
// if you have setup code that shouldn't be benchmarked itself
// (like constructing a large array, or initializing data),
// you can put that here
// this code, inside `iter` is actually measured
b.iter(|| {
// a black box disables rust's optimization
fibonacci(black_box(20))
})
});
}
criterion_group!(benches, fibonacci_benchmark);
criterion_main!(benches);With cargo bench you can run all benchmarks in your project. It will store some data in your target folder to record
what the history of benchmarks is that you have ran. This means that if you change your implementation (of the Fibonacci
function in this case), criterion will tell you whether your code has become faster or slower.
It's important to briefly discuss the black_box. Rust is quite smart, and sometimes optimizes away the code that you
wanted to run!
For example, maybe Rust notices that the fibonacci function is quite simple and that fibonacci(20) is simply 28657.
And because the Fibonacci function has no side effects (we call such a function "pure"), it may just insert at compile time the
number 28657 everywhere you call fibonacci(20).
That would mean that this benchmark will always tell you that your code runs in pretty much 0 seconds. That'd not be ideal.
The black box simply returns the value you pass in. However, it makes sure the rust compiler cannot follow what is going
on inside. That means, the Rust compiler won't know in advance that you call the fibonacci function with the value 20,
and also won't optimize away the entire function call. Using black boxes is pretty much free, so you can sprinkle them
around without changing your performance measurements significantly, if at all.
Criterion tells me that the example above takes roughly 15µs on my computer.
It is important to benchmark your code after making a change to ensure you are actually improving the performance of your program.
You usually put benchmarks in a folder next to
srccalledbenches, just like how you would put integration tests in a folder calledtest. Cargo understands these folders, and when you put rust files in those special folders, you can import your main library from there, so you can benchmark functions from them.
Profiling
Profiling your code is, together with benchmarking, is one of the most important tools
for improving the performance of your code. In general, profiling will show you where in your
program you spend the most amount of time. However, there are also more specific purpose profiling tools
like cachegrind which can tell you about cache hits amongst other things, some of these are contained with the valgrind program.
You can find a plethora of profilers in the rust perf book.
Profiling is usually a two-step process where you first collect data and analyse it afterwards.
Because of the data collection it is beneficial to capture program debug information,
however this is, by default, disabled for Rust's release profile. To enable this and to thus capture
more useful profiling data add the following to your Cargo.toml:
[profile.release]
debug = true
Afterwards you can either use the command line perf tool or your IDE's integration,
specifically CLion has great support for profiling built-in1.
perf install guide
We would like to provide an install guide, but for every linux distro this will be different
It's probably faster to Google "How to install perf for (your distro)" than to ask the TA's
If using the command line you can run the following commands, to profile your application:
cargo build --release
perf record -F99 --call-graph dwarf -- ./target/release/binary
Afterwards you can view the generated report in a TUI (Text-based User Interface) using (press '?' for keybinds):
perf report --hierarchy
Using this data you can determine where your program spends most of its time, with that you can look at those specific parts in your code and see what you can improve there.
You can also try to play around with this on your Grep implementation of assignment one,
to get a feel of how it works (e.g. try adding a sleep somewhere).
Before running it on the bigger projects like that of assignment 2.
Important for users of WSL1: perf does not properly work on WSL1, you can check if you run WSL1 by executing
wsl --list --verbose, if this command fails you are for sure running WSL 1, otherwise check the version column, if it says1for the distro you are using, you can upgrade it usingwsl --set-version (distro name) 2.
For some people it might be easier to use cargo flamegraph, you can install this using cargo install flamegraph.
This will create an SVG file in the root folder which contains a nice timing graph of your executable.
What does performance mean?
So far, we've only talked about measuring the time performance of a program. This is of course not the only measure of performance. For example, you could also measure the performance of a program in memory usage. In these lecture notes we will mostly talk about performance related to execution speed, but this is always a tradeoff. Some techniques which increase execution speed also increase program size. Actually, decreasing th memory usage of a program can sometimes yield speed increases. We will briefly talk about this throughout these notes, for example in the section about optimization levels we will also mention optimizing for code size.
Making code faster by being clever
The first way to improve performance of code, which is also often the best way, is to be smarter (or rely on the smarts of others). For example, if you "simply" invent a new algorithm that scales linearly instead of exponentially this will be a massive performance boon. In most cases, this is the best way to improve the speed of programs, especially when the program has to scale to very large input sizes. Some people have been clever and have invented all kinds of ways to reduce the complexity of certain pieces of code. However, we will not talk too much about this here. Algorithmics is a very interesting subject, and we many dedicated courses on it here at the TU Delft.
In these notes, we will instead talk about more general techniques you can apply to improve the performance of programs. Techniques where you don't necessarily need to know all the fine details of the program. So, let us say we have a function that is very slow. What can we do to make it faster? We will talk about two broad categories of techniques. Either:
- You make the function itself faster
- You try to call the function (or nested functions) less often. If the program does less work, it will often also take less time.
Calling it less
Let's start with the second category, because that list is slightly shorter.
Memoization
Let's look at the Fibonacci example again. You may remember it from the exercises from Software Fundamentals. If we want
to find the 100th Fibonacci number, it will probably take longer than your life to terminate. That's because to
calculate
fibonacci(20), first, we will calculate fibonacci(19) and fibonacci(18). But actually, calculating fibonacci(19)
will
again calculate fibonacci(18). Already, we're duplicating work. Our previous fibonacci(20) example will
call fibonacci(0)
a total of 4181 times.
Of course, we could rewrite the algorithm with a loop. But some people really like the recursive definition of the Fibonacci function because it's quite concise. In that case, memoization can help. Memoization is basically just a cache. Every time a function is called with a certain parameter, an entry is made in a hashmap. The key of the entry is the parameters of the function, and the value is the result of the function call. If the function is then again called with the same parameters, instead of running the function again, the memoized result is simply returned. For the fibonacci function that looks something like this:
use std::collections::HashMap; fn fibonacci(n: u64, cache: &mut HashMap<u64, u128>) -> u128 { // let's see. Did we already calculate this value? if let Some(&result) = cache.get(&n) { // if so, return it return result; } // otherwise, let's calculate it now let result = match n { 0 => 0, 1 => 1, n => fibonacci(n-1, cache) + fibonacci(n-2, cache), }; // and put it in the cache for later use cache.insert(n, result); result } fn main() { let mut cache = HashMap::new(); println!("{}", fibonacci(100, &mut cache)); }
(run it! You'll see it calculates fibonacci(100) in no-time. Note that I did change the result to a u128,
because fibonacci(100) is larger than 64 bits.)
Actually, this pattern is so common, that there are standard tools to do it. For example,
the memoize crate allows you to simply annotate a function. The code to do the
caching is then automatically generated.
use memoize::memoize;
#[memoize]
fn fibonacci(n: u64) -> u128 {
match n {
0 => 1,
1 => 1,
n => fibonacci(n-1) + fibonacci(n-2),
}
}
fn main() {
println!("{}", fibonacci(100));
}One thing you may have observed, is that this cache should maybe have a limit. Otherwise, if you call the function often enough, the program may start to use absurd amounts of memory. To avoid this, you may choose to use an eviction strategy.
The memoize crate allows you to specify this by default, by specifying a maximum capacity or a time to live (for example, an entry is deleted after 2 seconds in the cache). Look at their documentation, it's very useful.
Lazy evaluation and iterators
Iterators in Rust are lazily evaluated. This means they don't perform calculations unless absolutely necessary. For example if we take the following code:
fn main() { let result = || { vec![1, 2, 3, 4].into_iter().map(|i: i32| i.pow(2)).nth(2) }; println!("{}", result().unwrap()); }
Rust will only do the expensive pow operation on the third value, as that is the only
value we end up caring about (with the .nth(_) call). If you combine many iterator calls after each other
they can also be automatically combined for better performance. You can find the available methods on iterators
in the Rust documentation.
I/O buffering
Programs communicate with the kernel through system calls. It uses them to read and write from files, print to the screen and to send and receive messages from a network. However, each system call has considerable overhead. An important technique that can help reduce this overhead is called I/O buffering.
Actually, when you are printing, you are already using I/O buffering. When you print a string in Rust or C, the characters are not individually written to the screen. Instead, nothing is shown at all when you print. Only when you print a newline character, will your program actually output what you printed previously, all at once.
When you use files, you can make this explicit. For example, let's say we want to process a file 5 bytes at a time. We could write:
use std::fs::File; use std::io::Read; fn main() { let mut file = File::open("very_large_file.txt").expect("the file to open correctly"); let mut buf = [0; 5]; while file.read_exact(&mut buf).is_ok() { // process the buffer } }
However, every time we run read_exact, we make (one or more) system calls. But with a very simple change, we can reduce that
a lot:
use std::fs::File; use std::io::{BufReader, Read}; fn main() { let file = File::open("very_large_file.txt").expect("the file to open correctly"); let mut reader = BufReader::new(file); let mut buf = [0; 5]; while reader.read_exact(&mut buf).is_ok() { // process the buffer } }
Only one line was added, and yet this code makes a lot fewer system calls. Every time read_exact is run,
either the buffer is empty, and a system call is made to read as much as possible. Then, every next time
read_exact is used, it will use up the buffer instead, until the buffer is empty.
Lock contention
When lots of different threads are sharing a Mutex and locking it a lot, then most threads to spend most of their time waiting on the mutex lock, rather than actually performing useful operations. This is called Lock contention.
There are various ways to prevent or reduce lock contention.
The obvious, but still important, way is to really check if you need a Mutex.
If you don't need it, and can get away by e.g. using just an Arc<T> that immediately
improves performance.
Another way to reduce lock contention is to ensure you hold on to a lock
for the minimum amount of time required. Important to consider for this
is that Rust unlocks the Mutex as soon as it gets dropped, which is usually at the end of scope
where the guard is created. If you want to make really sure the Mutex gets unlocked, you can manually
drop it using drop(guard).
Consider the following example:
use std::thread::scope; use std::sync::{Arc, Mutex}; use std::time::{Instant, Duration}; fn expensive_operation(v: i32) -> i32 { std::thread::sleep(Duration::from_secs(1)); v+1 } fn main() { let now = Instant::now(); let result = Arc::new(Mutex::new(0)); scope(|s| { for i in 0..3 { let result = result.clone(); s.spawn(move || { let mut guard = result.lock().unwrap(); *guard += expensive_operation(i); }); } }); println!("Elapsed: {:.2?}", now.elapsed()); #}
Here we lock the guard for the result before we run the expensive_operation.
Meaning that all other threads are waiting for the operation to finish rather than
running their own operations. If we instead change the code to something like:
use std::thread::scope; use std::sync::{Arc, Mutex}; use std::time::{Instant, Duration}; fn expensive_operation(v: i32) -> i32 { std::thread::sleep(Duration::from_secs(1)); v+1 } fn main() { let now = Instant::now(); let result = Arc::new(Mutex::new(0)); scope(|s| { for i in 0..3 { let result = result.clone(); s.spawn(move || { let temp_result = expensive_operation(i); *result.lock().unwrap() += temp_result; }); } }); println!("Elapsed: {:.2?}", now.elapsed()); #}
The lock will only be held for the minimum time required ensuring faster execution.
Moving operations outside a loop
It should be quite obvious, that code inside a loop is run more often than code outside a loop. However, that means that any operation you don't do inside a loop, and instead move outside it, saves you time. Let's look at an example:
#![allow(unused)] fn main() { fn example(a: usize, b: u64) { for _ in 0..a { some_other_function(b + 3) } } }
The parameter to the other function is the same every single repetition. Thus, we could do the following to make our code faster:
#![allow(unused)] fn main() { fn example(a: usize, b: u64) { let c = b + 3; for _ in 0..a { some_other_function(c) } } }
Actually, in a lot of cases, even non-trivial ones, the compiler is more than smart enough to do this for you. The assembly generated for the first example shows this:
example::main:
push rax
test rdi, rdi
je .LBB0_3
add rsi, 3 ; here we add 3
mov rax, rsp
.LBB0_2: ; this is where the loop starts
mov qword ptr [rsp], rsi
dec rdi
jne .LBB0_2
.LBB0_3: ; this is where the loop ends
pop rax
ret
However, in very complex cases, the compiler cannot always figure this out.
To easily see what optimizations the Rust compiler makes, I highly recommend the Compiler Explorer. I used it to generate the examples above. Here's a link to my setup for that. Try to make some changes, and see if the compiler still figures it out!
Static allocation / reducing allocation
Dynamic memory allocation takes time. Every time malloc is called, the program spends a few nanoseconds handling that request.
(this blog post has got some very cool benchmarks!).
In Rust, malloc can sometimes be a bit hidden. As a rule of thumb, malloc is used when performing any of the following
operations:
Vec::new(),HashMap::new(),String::new(), and sometimes when inserting into any of these.Box::new()- Cloning any of the above
Arc::new()orRc::new()(note: cloning does not performmallocfor these types, which makes them extra useful)
Using dynamic memory allocation is sometimes unavoidable, and often very convenient. But when you are trying to optimize code for performance, it is useful to look at what allocations can be avoided, and which can be moved out of loops (and maybe can be reused between loop iterations). The best-case scenario is of course when you can remove allocations altogether. For example, by only using fixed-size arrays, and references to values on the stack.
Different allocations
Next week, when we talk about embedded Rust, you will see that we start using a custom memory allocator. The reason we will do that there, is that we will be programming for an environment where there is no Operating System providing an allocator. However, there are faster allocators out there than Rust's default. You can experiment with using a different one, and see how the performance changes.
Arena allocators
Another way to reduce allocations, is using an arena allocator. An arena allocator is a very fast memory allocator
which often does not support freeing individual allocations. You can only allocate more and more, until you delete
the entire arena all at once. For example, when you are rendering a video, you could imagine having an arena for every
frame that is rendered. All the memory is allocated at the start, and then that frame renders, storing intermediate results
in the arena. After rendering, only the final frame/image is left, and the entire arena can be deallocated.
typed_arena is a crate which provides an arena allocator for homogeneous types,
while bumpalo allows storage of differently typed values inside the arena.
Making existing programs faster
Even when applying all the techniques to write faster code we discussed sofar, there is a limit. That's because you are dependent on a compiler compiling your code into machine code, and your cpu executing that machine code quickly. Not all programs have the same needs, which means that you can gain a lot of performance by configuring the compiler correctly and making sure you take full advantage of the hardware the code is run on.
Inlining
Inlining is a compiler optimization which effectively literally puts the code of a function at its callsite. This eliminates function call overhead. On the flip side this can make the size of your program substantially larger, which may also cause more cache misses.
You can hint the Rust compiler to inline a function by adding the attribute macro #[inline] on top of a function.
Cachegrind can be a useful tool for determining what to inline.
This also has a chapter in the perf book for a more detailed explanation.
Optimization level
Most obvious of all, is the optimization level. By default, Rust compiles your code in optimization-level 0. That's the worst there is. For development, this is great! However, when actually running a program, using a higher optimization level is well worth the increased compilation time. There are 6 optimization settings:
- 0, 1, 2, 3: don't optimize, optimize a bit, optimize a bit more, and optimize a lot respectively
- "s", "z": optimize for size (a bit and a lot respectively)
To get the best performance, often, opt-level 3 is best. However, do try them all and see the difference for yourself.
To specify an optimization level, you have to add profiles to your Cargo.toml file. For example:
[profile.dev]
opt-level = 1
[profile.release]
opt-level = 3 # 3 is the default for release
This says, that if the release profile is selected, the optimization should be set to 3. The default build profile is "dev", which
is what is used when you run cargo run. To select the release profile, you can run cargo run --release.
A separate profile
benchis used while benchmarking, which will inherit from the release profile.
To see what the optimization level does, let's look at an example in godbolt. Here, I created a simple function
which copies a slice, and how it compiles with opt-level 0, opt-level 3 and opt-level "z". Of course, the one with "z" is by far the smallest. The
opt-level 0 still has a lot of functions in it from the standard library, which have all vanished in the opt-level 3 version. In fact, the opt-level
3 version does something very fancy: SIMD. under .LBB0_4, you see that some very weird instructions are used, that operate on very weird registers
like xmm0. Those are the 128 bit registers.inline
Target CPU
Now that we're talking about compiler options, it's worth mentioning the target CPU option. Even opt-level 3 will generate code that is compatible with a lot of different CPUs. However, sometimes, you know exactly on what CPU the code is going to run. With the target-cpu flag, you can specify exactly what model of CPU should be compiled to. You can set it to native to compile for the same CPU as the compiler currently runs on.
Concretely, not all x86 CPUs support the 256 or even 512 bit registers. However, especially for the code from the previous godbolt example, these registers can help a lot (since they can copy more data per instruction). Here you can clearly see the difference between the code generated with a target cpu set, and not set.
Rust even supports running different functions depending on what hardware is available, to do this you can use the target_feature macros,
as shown here.
Link-time optimization
When the Rust compiler compiles your code, every crate forms its own compilation unit. That means that optimizations are usually performed only within a single crate. This also means that when you use many libraries in your program, some optimizations may not be applied. For example, functions from other crates cannot be inlined. You can change this with the "lto" flag in the compilation profile. With LTO, more optimizations are performed after compiling individual crates, when they are linked together into one binary.
Branch prediction
CPUs use branch prediction to determine which branch in a conditional (if, match, etc.) statement is most likely to be taken.
The one it deems most likely it will usually start pre-emptively executing. However, if the CPU guesses the wrong branch this incurs
a penalty or slow down. In Rust, you can hint to the CPU and the Compiler which functions are unlikely to be executed (and thus branches
calling this function are also marked as cold/unlikely) using
the #[cold] attribute macro, also see the rust docs.
#[cold]
fn rarely_executed_function() { }PGO and Bolt
PGO or Profile Guided Optimization is a process by where you generate an execution trace, and then feed that information to the compiler to inform it what code is actually being executed and how much. The compiler can then use this information to optimize the program for a specific workload.
For Rust we can use cargo-pgo to achieve this. Research shows that this can achieve performance improvements of up to 20.4% on top of already optimized programs.
The general workflow for building optimized binaries is something like this:
- Build binary with instrumentation
- Add extra information to your program to facilitate profiling
- Gather performance profiles
- Run a representative workload while gathering data
- Run it for as long as possible, at least a minute
- Build an optimized binary using generated profiles
- Use the data colleceted in the previous step to inform the compiler
- The optimized binary is only optimized for the profiling data and thus specific workloads that are given. The program might perform worse on substantially different workloads.
Zero Cost Abstractions
Rust has many higher level features like closures, collections, iterators, traits, and generics. But these are made in such a way that they try to obey the following principles:
- What you don’t use, you don’t pay for
- What you do use, you couldn’t hand code any better.
Rust calls this a "Zero Cost Abstraction", meaning you should not need to worry too much about the performance penalty these abstractions incur.
Static and Dynamic Dispatch
When code is written to be abstracted over the kind of data it gets, there are two ways to deal with this in Rust.
The first way is to use Generics as was explained in Software Fundamentals. Rust internally does this using something called Monomorphization, which effectively makes a different version of your function for every type it is actually called with. This does of course mean that your binary size will be larger but, you won't pay the overhead it costs to determine this at runtime.
The second way to do this is through something called Trait Objects, this defers the binding of methods until runtime, through something called virtual dispatch. This gives more freedom for writing your code as the compiler does not need to know all the ways you will call this method at compile time, like with generics. However, you do then incur a runtime cost for using this.
Zero-Copy Design
Rust makes it really easy to design programs to be "Zero-Copy", this means that the program continually reinterpret a set of data instead of copying and moving it around. An example you could think of is network packets. Network packets have various headers, like size, which determine what comes afterwards. A naive solution is just to read the headers then copy the data out of it into a struct you've made beforehand. However, this can be very slow if you are receiving lots of data.
This is where you would want to design your program to instead of copying the data into a new struct, have fields which are slices (pointers with a lengths) of memory and populate those accordingly. Many popular libraries in the Rust ecosystem like Serde (the serialization/deserialization library) do exactly this. You can also do it more manually yourself, with help of crates like Google's zerocopy.
Memory Management
Lastly something to consider when optimizing programs is also memory management. The various ways you use or interact with memory can also have performance considerations.
A simple and obvious case is that cloning (or operations that invoke memcpy in general) is usually considered quite slow
it can therefore often beneficial to work with references rather than cloning a lot.
Another thing to take into account is that a lot of performance optimizations are bad for memory usage, think of things like unrolling loops or the aforementioned monomorphization. If you are working on a memory constrained system it might therefore be wise to tune down some optimizations in favour of memory.
Conversely, a bigger memory footprint can also have a negative performance impact in general, this can be due to caches or misaligned accesses. On a modern computer there exists a lot of caches of various sizes, and if a single function can neatly fit into one of those caches it can actually speed up computation heavy programs significantly. This means that sometimes "lower" opt levels can actually be faster. It is therefore yet again very important to note that there is no 'silver bullet' with regards to optimization, and you should always verify that you are actually increasing the speed of your program with the help of benchmarks.
There are also some ways within rust to try and reduce or improve your memory footprint. One of those ways are packed or bit-aligned structs as shown in the rust book. Another way to improve your memory footprint is to use constructs such as bitflags or bitvec which allow you to pack data even more closely together by using the minimum amount of bits you need.
For example, using eight bools in Rust, it uses eight bytes, while eight flags can fit within one u8. 2
extern crate bitflags; use std::mem::size_of; use bitflags::bitflags; struct Bools { a: bool, b: bool, c: bool, d: bool, e: bool, f: bool, g: bool, h: bool, } bitflags! { struct Flags: u8 { const A = 0b00000001; const B = 0b00000010; const C = 0b00000100; const D = 0b00001000; const E = 0b00010000; const F = 0b00100000; const G = 0b01000000; const H = 0b10000000; } } fn main(){ println!("Size of Bools Struct: {} byte(s)", size_of::<Bools>()); // 8 println!("Size of Flags Struct: {} byte(s)", size_of::<Flags>()); // 1 }
Some of these optimizations rust can do itself however.
For example when using a NonZero integer Rust can use that single missing bit
to store the state of an option (either Some or None).
use std::num::NonZeroU8; use std::mem::size_of; fn main() { type MaybeU8 = Option::<NonZeroU8>; println!("Size of MaybeU8: {} byte(s)", size_of::<MaybeU8>()); // 1 }
In conclusion, these are all trade-offs to be made, and no single solution will fit all. So be careful to consider which techniques you apply without thinking or checking.
Resources
-
https://www.jetbrains.com/help/clion/cpu-profiler.html ↩
-
it is worth nothing that the 8 bytes representation can often be faster if you are only accessing one bool at a time due to alignment. ↩
Lecture 3
Contents
No OS, no standard library
This explanation is a summary of the lecture. For more general knowledge about rust embedded development, I highly recommend the rust embedded book
Until now, in both Software Fundamentals and previous weeks in Software Systems, all the code you have made is designed to work on top of an operating systems. Either Linux, Windows, or sometimes even MacOS. A program that runs on top of an operating system generally has to care less about unimportant things. The operating system will take care of that. Scheduling threads? Interacting with peripherals? Allocating memory? The operating system generally handles it.
But sometimes, having an operating system is not feasible, required or desired. Some hardware is simply not supported by major operating systems. Or a specific peripheral has no driver for the operating system you want to use. Booting an operating system usually also takes a while, and some performance may be lost since the operating system has to perform tasks in the background. Or perhaps, you simply want to write an operating system itself.
When a program runs without an OS, some services aren't available by default. For example:
- A filesystem
- Threads and subprocesses
- An allocator
- support for interaction with peripherals
- graphics
- a standard output to print to, or standard input to get input from
- startup code initializing the program
But, where previously the operating system may have prevented you from creating these yourself, without an operating system around, the program is free to manage all the hardware by itself.
However, there is a problem. Rust has a pretty large standard library. Many of the services provided by the standard
library rely on the operating system. For example, std::thread only
works when it can spawn threads through the operating system, std::vec needs
an allocator and std::fs is literally made to manipulate a filesystem.
This means that a rust program that runs without an operating system, does not have access to the standard library. We often call
those programs "no-std", and they are marked in their main.rs file with the following annotation at the top of the file:
#![allow(unused)] #![no_std] fn main() { // the program }
Although the standard library is not available for no-std programs, they can just have dependecies like normal. You can
still specify those in the Cargo.toml file. However, all dependencies of a no-std program must also be marked as no-std.
For some libraries this is an optional feature, for some it's the default. A list is available here
core and alloc
Not all services in the standard library depend on an operating system. For example, many built-in types such as Option and Result,
and many traits such as Eq, Ord and Clone should be perfectly usable when there's no operating system. And indeed, you can. Sofar,
we've used the rust standard library and the word std pretty interchangeably. But actually, they are not the same. The standard library
comes in tiers.
coreis the set of all standard library items that don't rely on an operating system in any way.allocis the set of all standard library items that rely only on an allocator.Vecs are part of this.stdis the set of standard library items that require an operating system to work.stdis a superset ofallocandcore. 4coreis always available, even when you specified your program to be no-std.allocis conditionally available. It can only work if there is an allocator. Thus, if your program supplies one, you can importalloc. That works as follows:
#![allow(unused)] #![no_std] fn main() { // required, since this is technically not entirely stable yet. #![feature(alloc_error_handler)] // enable the alloc crate. Only works if an allocator is provided. extern crate alloc; // import some allocator use some_allocator::SomeAllocator; // this tag marks a special global variable. The type of it must implement // the `Allocator` trait. If this is not supplied, alloc cannot work and your // program won't compile. #[global_allocator] static ALLOCATOR: SomeAllocator = SomeAllocator::new(); // This function is called when an allocation fails. // For example, memory may have ran out. #[alloc_error_handler] fn alloc_error(layout: Layout) -> ! { panic!("Alloc error! {layout:?}"); } // A program using Vecs and other features from alloc can now follow }
There are a number of allocators available for no-std programs. A list of them can be found here.
You may have noticed the return type of alloc_error is
!. This means that the function will never return. Because it doesn't return, a real return type is also not necessary. You can create a program that never returns by using an infinite loop:#![allow(unused)] fn main() { fn never_returns() -> ! { loop {} } }
Panicking
When a Rust program panics, it generally performs a process called unwinding. That means that it will walk the stack backwards, and then crashes, printing a trace of the stackframes such that you can debug where it went wrong. But, what should happen when a program running on bare-metal1 crashes? There is no such thing as exiting the process and printing a message. Exiting just means giving control back to a parent process, but the program is the only thing running on the system.
When a program runs without an operating system, it has to assume its the only thing running, and that its running forever. On an embedded device, this means that the program is the first and only thing that runs once the device is turned on, and that it will run until the device is turned off. That means that if a program panics, the only real thing that it can do is either
- reboot/restart from the start of the program
- wait in an infinite loop
So, what happened when the panic function is executed in no-std rust?
For a no-std program to be valid (and compile), it has to define a panic handler:
#![allow(unused)] #![no_std] fn main() { // maybe put the code that initializes `alloc` here // when a panic occurs, this function is called #[panic_handler] fn panic(info: &PanicInfo) -> ! { // just go into an infinite loop if it does loop {} } }
Starting up
In normal rust, a program defines a main function, which is the first code to be executed. This works, because
the operating system will call it2 when the program is executed. But, we cannot assume there is an operating system
in no-std Rust!
Starting up depends on the environment. A no-std program can do one of several things. When a no-std program actually runs under
an operating system (maybe one that's not supported by rust by default), it can define a function with the appropriate name.
For example, a no-std program on linux could define the __start function.
However, if the program is supposed to be executed when a computer boots up (maybe you're making an operating system or a
program for a microcontroller), then the processor generally defines how it will start running user defined code. For those
of you who followed Software Fundamentals, you will know that on the NES
there was a reset vector. A location in memory containing the initial program counter. Other processors will have similar,
yet slightly different conventions.
However, often when we work with a well-supported processor architecture, or microcontrollers with good support, we can use hardware abstraction layers to greatly simplify this.
By default, all names in rust are "mangled". That means, in the final compiled program, they have slightly different names. In a Rust program, there can be multiple functions with the same name defined in different modules for example. In the compiled program, the functions will have different "mangled" names to disambiguate.
When a function needs to have a precise name such as
__starton linux, then you will have to add the#[no_mangle]attribute to it to make sure it will actually get that name in the compiled program:#![allow(unused)] fn main() { #[no_mangle] fn __start() { } }
Hardware abstraction
From now on, we will assume we are making a program that has to run on a bare-metal microcontroller. For this course, you will use an nrf51822 processor in the assignments.
Many bare-metal programs have similar needs. They need to boot up, initialize some data, set up some interrupt handlers and interact with some peripherals. These steps often work almost the same for systems with similar architectures. Also, it is not uncommon for systems to use the same standards for communicating with peripherals. Pretty common standards include I2C, CAN, SPI, PCI(E), etc.
Because no-std programs can just import libraries, naturally people have made libraries to solve some of these problems. Actually, each of the previously mentioned standards link to a rust library that makes it easier to use these standards. For example, they provide an interface to generically interact with components connected over for example i2c.
Many processors, or processor families also come with libraries that make it easy to use the interfaces that that processor provides. For example, for the assignments in this course we use an nrf51822 microcontroller. There are libraries which specifically for the NRF51 family of processors, allows you to set up interrupts, or access memory mapped IO safely. The library already hardcodes the memory locations of the different memory mapped devices.
Memory mapped IO
Many microcontrollers allow access to peripherals through memory-mapped IO. That means that specific addresses in memory are set up not as a memory location, but as a port to a peripheral. When the processor writes or reads to that location, it actually communicates with the peripheral device. Memory mapped IO is sometimes abbreviated as MMIO.
The locations in memory of MMIO can differ per processor or processor family. Generally, you have to look at the datasheet of the specific device to find the addresses. However, often a PAC library exists that remembers the addresses for you.
PACs
PAC is short for peripheral access crate. They provide an interface to easily access peripherals of a specific device. There are different PACs for different devices. You can find a list here. They will for example contain all the addresses of MMIO peripherals, and provide functions to write and read from and to those locations.
For example, nrf51-pac defines a module called uart0. In it, there is a struct with all the fields from the NRF uart API.
You will see that these fields match up with the register overview of the UART in the manual for the NRF51 series on page 154.
Often, PACs are automatically generated from a hardware's description. We will talk about this more next week. But it does mean a PAC is not always very easy to use. It requires knowledge of some conventions. The nice thing is, since it's all automatically generated, the conventions will be the same across all PACs for different hardware. However, this will take some time to get used to
Structs for Memory Mapped IO
If you think about it, a struct is simply a specification for the layout of some memory. A struct like
#![allow(unused)] fn main() { struct Example { a: u32, b: u8, c: u8, } }
Defines a region of memory of 48 bits (or 6 bytes)3, with specific names for the first 4 bytes, the 5th and the 6th byte.
Quite often, the manual of a microprocessor will list the locations and layout of memory mapped IO. For example, the reference manual of the NRF51 series processors, will list this for the I2C interface:
 This says that, there are two (separate) I2C interfaces on the chip (the instances). One at address
This says that, there are two (separate) I2C interfaces on the chip (the instances). One at address 0x40003000 and
another one at address 0x40004000. Each of the instances has a number of control registers listed below. Each has an offset
from its base address (so that's the 0x40003000 or 0x40004000).
You may notice that this is actually quite similar to the definition of a struct. This is exactly what a PAC will be, a definition for structs that are equivalent to the layout of such MMIO regions. Let's look at the rust PAC for the nrf51, and its definition for the I2C interface:
#![allow(unused)] fn main() { #[repr(C)] pub struct RegisterBlock { pub tasks_startrx: TASKS_STARTRX, pub tasks_starttx: TASKS_STARTTX, pub tasks_stop: TASKS_STOP, pub tasks_suspend: TASKS_SUSPEND, pub tasks_resume: TASKS_RESUME, pub events_stopped: EVENTS_STOPPED, pub events_rxdready: EVENTS_RXDREADY, pub events_txdsent: EVENTS_TXDSENT, pub events_error: EVENTS_ERROR, pub events_bb: EVENTS_BB, pub events_suspended: EVENTS_SUSPENDED, pub shorts: SHORTS, pub intenset: INTENSET, pub intenclr: INTENCLR, pub errorsrc: ERRORSRC, pub enable: ENABLE, pub pselscl: PSELSCL, pub pselsda: PSELSDA, pub rxd: RXD, pub txd: TXD, pub frequency: FREQUENCY, pub address: ADDRESS, pub power: POWER, /* private fields */ } }
(source: https://docs.rs/nrf51-pac/latest/nrf51_pac/twi0/struct.RegisterBlock.html)
As you can see, the fields in this struct exactly match the manual of the NRF51. Note that some /* private fields */ are missing,
those are extra fields inserted for the alignment of the other registers, so they are located exactly at the right positions as the manual says.
The types of the field are also interesting. They are almost all different, and that's because each field may have different requirements for the values that can be stored in them (maybe the frequency field cannot have certain values). The values of these specific types make sure that you cannot write (without unsafe code) write wrong values to the fields.
Navigating the documentation for these types may be a bit difficult. You will have to do this in the third assignment. The documentation for PACs isn't great, that's because it's automatically generated code. The assumption is that you also have the manual for the chip the PAC was generated for, it has more information about the hardware. The PAC is just so you cannot make any mistakes by writing to the wrong register for example. Keep this in mind!
It often does not make sense for users of PACs to actually create instances of these MMIO structs themselves. That's because there physically only are a limited number of instances of that MMIO region (maybe only 1). And the actual locations of these structs are also limited. They can really only exist at the base addresses of these MMIO regions. Therefore, as a user of a PAC, you won't be constructing these structs yourself.
Instead, you'll ask the library to do it for you. It will give you a reference to all the instances of the MMIO structs. The references will
all point to the correct regions in memory. You do this with the Peripherals struct (this struct is present in any PAC crate). You can do this as follows:
use nrf51::Peripherals; fn main() { let peripherals = Peripherals::take().unwrap(); // instance of the SPI RegisterBlock struct, you can // write to fields of this to interact with the SPI device. let spi = &peripherals.SPI0; }
Let's say we want to write code that sets the frequency of the I2C signal. On the Spi struct, there's a field called frequency,
and you can see above that its type is FREQUENCY. Let's write to it:
use nrf51::Peripherals; fn main() { let peripherals = Peripherals::take().unwrap(); let spi = &peripherals.SPI0; // this is unsafe, most values are invalid for this register. // 0x0001 would likely crash the chip. spi.frequency.write(|w| unsafe {w.bits(0x0001)} ); // this is always safe however spi.frequency.write(|w| w.frequency().k125()); }
So what's happening on this last line? first, we're choosing the field spi.frequency, and call the write() function on it.
Instead of simply writing a value, write() takes a "closure" (a sort of lambda function).
This may feel cumbersome, but remember that a PAC is really low level. Structuring it this way actually allows the rust to generate code
that will be extremely close to hand-written assembly.
The closure gets a parameter w, and we can call methods For example, the bits() method. This allows us to put a specific
binary value in the frequency register. But, bits is unsafe to use. That's because not all values in the register are valid
frequencies for the chip. Maybe the chip crashes when you write certain values. However, since, through the PAC, rust knows that
this field is of type FREQUENCY, there is also a method frequency() which only allows us to put valid values into the register.
When using the unsafe
bits()function, always check the documentation what values are valid
For example, the k125() sets the chip to 125kbps. Other values like m1 (for 1 mbps) are possible too. But
Through PACs, all registers which have "semantics", i.e. they represent a frequency, a number, a power state, or a configuration value can only be (safely) written with values which fit these semantics. This prevents you from ever accidentally order the chip to do something unspecified.
HALs
HAL is short for hardware abstraction layer. A HAL is a higher level abstraction, usually built on top of a PAC. Let's again take
the NRF51 as an example. There is a crate called nrf51-hal. For example, some NRF51 processors will
have hardware accelerated cryptographic functions. While through a PAC, you'd interact with the registers directly, the HAL will provide an
encrypt() and decrypt() function that does everything for you.
Architecture specific
It sometimes doesn't make sense to put support for a specific device in either a PAC or a HAL. That's because some devices or hardware features are not shared per manufacturer, or series, but for the entire architecture. For example, the way you set up interrupts, set up memory protection, or even boot the entire chip. For some architectures, there are crates which provide support for systems with that architecture. For example,
cortex_mprovides support for all ARM cortex M processorscortex_m_rt(rt means runtime) provides code to boot cortex_m processors (so you don't need to touch assembly ever again)alloc_cortex_mprovides an allocator on ARM cortex M systems, so you can useBox,Vecand other standard collections in your code.
corex_aLikecortex_m, but for cortex A processorsriscvprovides similar operations ascortex_m, but for riscv processorsriscv-rtprovides similar operations ascortex_m_rt, but for riscv processors
x86provides similar operations ascortex_m, but for x86 processorsavr_halprovides low-level support for arduinos and related AVR-based processors. Unfortunately the support is worse than the other entries on this list.
All in all, this list allows you to run rust code on a large selection of microcontrollers available on the market without much hassle. Most of these provide templates to get started quickly. If you're interested, you might take a look through the rust embedded github organisation. They have loads of other projects that make writing rust for microcontrollers easy.
Safety abstractions and unsafe code
To switch to unsafe Rust, use the unsafe keyword and then start a new block that holds the unsafe code. You can take five actions in unsafe Rust that you can’t in safe Rust, which we call unsafe superpowers. Those superpowers include the ability to:
- Dereference a raw pointer
- Call an unsafe function or method
- Access or modify a mutable static variable
- Implement an unsafe trait
- Access fields of unions
It’s important to understand that unsafe doesn’t turn off the borrow checker or disable any other of Rust’s safety checks: if you use a reference in unsafe code, it will still be checked. The unsafe keyword only gives you access to these five features that are then not checked by the compiler for memory safety. You’ll still get some degree of safety inside of an unsafe block.
In addition, unsafe does not mean the code inside the block is necessarily dangerous or that it will definitely have memory safety problems: the intent is that as the programmer, you’ll ensure the code inside an unsafe block will access memory in a valid way.
People are fallible, and mistakes will happen, but by requiring these five unsafe operations to be inside blocks annotated with unsafe you’ll know that any errors related to memory safety must be within an unsafe block. Keep unsafe blocks small; you’ll be thankful later when you investigate memory bugs.
To isolate unsafe code as much as possible, it’s best to enclose unsafe code within a safe abstraction and provide a safe API, which we’ll discuss later in the chapter when we examine unsafe functions and methods. Parts of the standard library are implemented as safe abstractions over unsafe code that has been audited. Wrapping unsafe code in a safe abstraction prevents uses of unsafe from leaking out into all the places that you or your users might want to use the functionality implemented with unsafe code, because using a safe abstraction is safe.
One important note here is that using unsafe code is not always bad. We say that not all unsafe code is unsound. However, the compiler simply cannot and will not check this, making you, the programmer responsible. Any time you use an unsafe code block, you should properly document why yes this code has to be unsafe but also yes the code is sound nonetheless. Sometimes this soundness relies on some preconditions being checked.
The text also mentions the word "Safe abstraction". So what's that? A good example is a Mutex.
In general, it is unsafe to modify a variable from multiple threads. However, accessing and modifying
values inside mutexes from multiple threads is fine. That's because when accessing a value in a
Mutex, you are forced to lock that Mutex first. And this locking makes sure that nothing else is allowed
to access the variable until unlocked.
The important takeaway is, that Mutex actually uses unsafe code under the hood. It allows you to reference
a mutable variable from multiple threads. And yet, using a Mutex is totally safe. Because of the interface Mutex
exposes, it is actually impossible to violate any safety guarantees. Thus, a Mutex makes sure that however it is used,
all the internal unsafe code is always sound.
We call things like a Mutex a safety abstraction. Some things in Rust are only safe when specific conditions are met.
In the case of the mutex, this condition is aliasing a mutable reference (from multiple threads!). The compiler cannot
check those conditions. But instead of manually checking the conditions before you do something unsafe, you make an abstraction.
Some way that makes the unsafe thing unconditionally safe. A Mutex does this by only giving access to the internals when locking.
UnsafeCell
Mutexis not the only abstraction for aliasing mutable references. There is also theCell<T>,RefCell<T>andRwLock<T>. The first two are like locks, but can only be used in single threaded scenarios and are therefore much more efficient. The last is simply a more efficient lock when reading is more common than writing to the internals.At the root of all these types lies the
UnsafeCell. TheUnsafeCellhas some built-in compiler support and is therefore a bit magical. It is actually the only safe way to modify a value without needing a mutable reference. However, usingUnsafeCellis always unsafe as the name implies. When using it, you are responsible to make sure that the inner value is not actually ever accessible to two threads at the same time. You will see that the sourcecode of aMutexuses theUnsafeCelltoo, and only accesses it after theMutexis locked.#![allow(unused)] fn main() { pub struct Mutex<T: ?Sized> { inner: sys::MovableMutex, // <-- C-style mutex poison: poison::Flag, data: UnsafeCell<T>, // <-- UnsafeCell used here } }
Actually, indexing an array could also be seen as such a safe abstraction. Internally, indexing an array just offsets a pointer, but this
is only safe if the offset-location is in-bounds. The unsafe version of this operation is called get_unchecked
which does not do any safety checking and is therefore marked "unsafe". However, the indexing operation on arrays is safe because it checks whether the index
is in bounds, and crashes if it is not. A crash is not very nice of course, but at least it is safer than a buffer overflow leading to some kind of security vulnerability.
If you'd like reading more about this, I personally thought David Tolnay's and Alex Ozdemir's posts were very good.
In assignment 3 you are tasked to implement safe abstractions for mutation (there called OwnMutex). You should use UnsafeCell as a basis here.
Resources
-
When we refer to bare-metal code, we mean code that runs without any operating system around it. For example, the program runs alone on a microcontroller. It is the first and only thing started at boot, and is solely responsible to manage all the hardware on that system. ↩
-
Technically, that depends on the operating system. Linux will jump to the
__startlabel by default.stdRust makes sure that main is called at some point after__startis executed. ↩ -
Due to struct packing rules, the exact layout of the struct may not be 6 bytes since that may be less efficient in certain situations. You can add the attribute
#[repr(packed)]to a struct to force the layout to be exactly what was specified, and#[repr(C)]to force a struct to have the same layout as a C compiler would give it. ↩
Lecture 4
Contents
- Unsafe Code
- Foreign Function Interfaces
- Nightly features and release cycle
- Cross compilation
- Messaging protocols
Unsafe Code
This section is a very short version of what you can also read in the rust book
In rust, memory safety is checked by the compiler. It does this using a complicated set of rules that will reject some code and accept other code. However, not all memory safe code is accepted. The rules that govern the memory safety are a bit too conservative. Especially when you want to start doing low-level things, you may run into this.
However, in Rust it is possible to temporarily disable some (but not all!!!) of the compiler's checks so you can do things
which you know is safe but the compiler cannot check. We mark such sections with the keyword unsafe:
fn main() { unsafe { // this code has fewer checks } }
Inside these unsafe blocks, you are allowed to do the following things:
- Dereference a raw pointer (can lead to user-after-free or buffer overflows!)
- Access or modify a mutable static variable (can lead to race conditions!)
- Access fields of unions (this allows you to interpret data that should be an int as for example a float)
- Call an unsafe function or method (an unsafe function can do any of the above)
- Implement an unsafe trait (some traits have certain requirements which will cause memory unsafety when not satisfied)
Raw pointers are something different than references. We write references as
&Tor&mut Twhile we write a raw pointer as*const Tor*mut T. However, unlike references, pointers can be null, may alias (even*mut) and rust won't make any assumptions about them
As mentioned earlier, using unsafe code doesn't imply that it's wrong. In other words, not all unsafe code is unsound.
However, safe code can never be unsound, if it were the compiler would catch it. Inside unsafe blocks, the compiler will not
always detect unsound code.
Undefined behavior
Some operations in a language are explicitly undefined behavior. That's not because the designers of the language were lazy, but because this gives the compiler freedom to optimize certain programs. For example:
fn some_fn() -> Option<u32> {unimplemented!()} fn main() { let a: Option<u32> = example(); a.unwrap(); }The
unwrapcall here has to check whetherais Some orNone. However, if we know that example will never returnNonewe can useunsafe{a.unwrap_unchecked()}instead. WhenaisSome(x)this will returnx. However, what happens when suddenly a turns out to beNoneanyway? Inunwrap_unchecked, this is undefined behavior.With unwrap, this would check this and panic. But with
unwrap_unchecked, the compiler is perfectly allowed to leave out that check (hence it isunsafeto use). What happens when you do use it onNone? We don't know. Most likely, it will just give us a random integer here, from somewhere else on the stack. This is exactly what you are responsible for when you useunsafecode. You should make sure that this can never actually happen (by for example ensuringexamplereally never can returnNone).
Assumptions
Often, unsafe code relies on certain assumptions. These assumptions may be true in your code, but the compiler
cannot reason about them being true in general. For example:
- This variable can never be zero
- This pointer is always within bounds
- This pointer is never null
- This variable is only ever accessed from one thread
- There is only one core on this machine
- Interrupts are turned off here
- This memory is still allocated
- This function doesn't decrease the value of my variable
In unsafe code, you, the programmer are responsible for making sure that in your code your assumptions are true.
You can do this by explicitly checking that they are true like below:
#![allow(unused)] fn main() { // unsound when a is null unsafe fn dereference(a: *mut usize) -> usize { *a } // TODO: is this the only assumption we have to check? fn safe_dereference(a: *mut usize) -> usize { // make sure a is not null assert_ne!(a as usize, 0); unsafe { dereference(a) } } }
Alternatively, you can just reason through your code to prove that your code cannot break your assumptions.
These two techniques are the same as what the compiler does: reasoning and inserting checks. However, in unsafe code that's
your responsibility, since the compiler cannot always reason as well as you can.
In the code example above, we also see a function marked as unsafe. That means that the function can only be called inside
of an unsafe block. This is often done when the soundness of a function depends on the caller making sure that certain conditions are true
IMPORTANT
When you use an
unsafeblock, it is often a good idea to put a comment above reasoning through your assumptions and why they are true. If you are then later debugging, you can check your assumptions again.More importantly, it is a very good practice to put such comments above
unsafefunctions explaining what a caller must check before it is sound to call that function.In fact,
clippy, Rust's linter can warn when you don't have such a comment
Abstraction
Almost everything in Rust is an abstraction over unsafe code. Abstractions over unsafe code can be fully safe to use,
as long as they make sure to check all their assumptions before running unsafe code.
For example, a Box has to call malloc and free to allocate and deallocate memory. These functions give back raw pointers,
which sometimes may even be NULL. However, Box will check that this is not the case. As long as you have access to the Box,
the Box will also not free the memory associated with it. That means you can never accidentally use the memory after it is
freed (since that can only happen when you have no access to it anymore).
Similarly to how Box abstracts over managing memory:
- Mutex abstracts shared mutability
- Vec abstracts growing and shrinking memory
- println! and File abstracts system calls
- std::io::Error abstracts errno
- Channel abstracts
Foreign Function Interfaces
Sometimes, it becomes necessary to communicate with programs written in other languages besides Rust. There are two good options for this:
- Passing around messages through some kind of shared channel. This channel could be a network socket, http api, unix socket, file, unix pipe, etc. As long as source and destination agree on what bytes mean what this works.
- Going through C
The latter is what we will talk about in this section. C has become, besides just a programming language, also a common way of communicating between languages. Many languages provide some kind of API which allows that language to call a C function. In some languages that's easier than in others (python is very easy for this for example), but it often exists. Data passed from and to C functions will be converted to use C's data representation.
This approach has some downsides. For example, we are limited to the data types which C supports. Some datatypes in Rust for example aren't very nicely supported. For example, enums or slices. But that's not exclusive to Rust, C doesn't really have a concept of classes for example. So any language that uses classes has to work around that.
Such interfaces to other languages like C are called foreign function interfaces. They work by linking code together. Each language uses their own compiler to compile their own code, and later the resulting object files are pasted together into one big binary. The individual object files will define symbols (basically names of things in them, like functions).
Some object files will be "looking" for a symbol that they don't define themselves. The linker will connect the object files such that when one object file is "looking" for a symbol and another provides that symbol, the resulting binary connects those two together.
Above we describe static linking. There's also dynamic linking, where at runtime the program can import more symbols from a shared object file.
When a program in another language (like C) wants to use some Rust code, that code will be "looking" for a certain symbol during linking.
// says "there exists a function somewhere called do_rust_thing".
// however, we did not define it in c. Later, during linking
extern void do_rust_thing(int a);
int c_thing() {
// call that function
do_rust_thing(int a);
}
do_rust_thing is declared here, but we gave no definition. However, we can do that in Rust. As long as the name is the
same, the linker will resolve this.
#![allow(unused)] fn main() { use std::ffi::c_int; pub fn do_rust_thing(a: c_int) { println!("{}", a); } }
However, here we have to be careful. Rust uses a process called name-mangling. In the final object file, there won't be a
symbol do_rust_thing. Instead, there will be something like _ZN7example13do_rust_thing17hccc9c26c6bcb35a8E (which you can see
does contains the name of our function). This mangling is necessary since in Rust it's possible to define multiple different functions with
the same name. This for example happens when you implement the same trait for multiple types.
We can avoid this by using #[no_mangle]
#![allow(unused)] fn main() { use std::ffi::c_int; #[no_mangle] pub fn do_rust_thing(a: c_int) { println!("{}", a); } }
Next, C uses a different ABI than Rust. That basically means that the way it passes arguments to functions and gets return values from functions is slightly different. Different ABIs may for example use different registers for certain parameters, and C supports functions with a variable number of argument, which Rust does not.
That means that for all the parameters to do_rust_thing to be interpreted correctly by both sides, we need to make sure that the ABI
is the same. The easiest in this case is to ask Rust to change the ABI for the do_rust_thing function, which we can do as follows:
#![allow(unused)] fn main() { use std::ffi::c_int; #[no_mangle] pub extern "C" fn do_rust_thing(a: c_int) { println!("{}", a); } }
You may have noticed that we use a type called
c_inthere. That's a type that is guaranteed to be equivalent to anintin c.
Here we specify the ABI to be "C". There are other ABIs we can choose, but we want this function to be callable from C so that's what we will choose.
We can do the same the other way around. In Rust we can say that we "expect" a c function to be defined somewhere. We can write that as follows:
use std::ffi::c_int; // tell the Rust compiler to expect extern "C" { pub fn some_c_function( a: c_int, ); } fn main() { unsafe {some_c_function(3)} }
#include <stdio.h>
void some_c_function(int a) {
printf("%d", a);
}
Again, we have to specify that we're working with the "C" ABI. Inside the extern block we can define a number of function
signatures without a function body. In our main function we can now simply call this function, the linker will take care of
actually connecting this to the function defined in C. As you can see, calling a C function in Rust is actually unsafe. That is
because the c compiler has much fewer safety guarantees than Rust has. Simply calling a C function can cause memory unsafety.
To actually make sure the programs are linked together, we need to instruct the compiler to do some work for us
When we want to call Rust code from C, we may need to compile our Rust binary as a "shared object file" and we can even use
cbindgento automatically generate a C header (.h) file.Alternatively, we may want to automatically compile and link our C files when we want to call functions in that C file from Rust. We can use build scripts (little Rust programs that are run before compilation, which can for example call another compiler) to automatically compile C files as part of
cargo run. A crate calledcccan be used to actually call the c compiler.
Nightly features and release cycle
The Rust compiler is made in Rust. That means that to compile a new Rust compiler, you need an old Rust compiler. This means that when new features are added to Rust, they can't immediately be used in the Rust compiler sourcecode itself, since the older compiler doesn't support them yet. This process of using an old compiler to create a new compiler is called bootstrapping.
Rust compilers are constantly being built and published. Most often there's the nightly compiler, which is automatically created every night base on the current master branch of rust's git repository. You can use these nightly compilers if you want to use upcoming features or still unstable features of the Rust language.
Then, every 6 weeks, the current nightly released is branched off which becomes the beta release. Beta releases are mostly meant for testing. If bugs are found in beta, they are removed before they get into stable, the last type of rust compiler we have to talk about. New stable compilers are released every 6 weeks (at the same time as the next beta branches off of main). The hope is that most bugs in new features are removed when a stable version is released. Therefore, stable Rust is the version you'll use most often.
You can read more about this here
There is however a very good reason to use nightly sometimes. New features are constantly added to Rust. Even when they are already fully implemented, they may not be scheduled to be in the next beta or stable compiler for a long time. However, with a nightly compiler you can enable these experimental features anyway! (use at your own risk)
For example, it is currently (sorry if this is outdated by the time you're reading this!) not possible to create a type alias
with impl SometTrait in them For example, the following code is not legal.
#![allow(unused)] fn main() { type U32Iterator = impl Iterator<Item = u32>; }
However, there does exist an implementation of this in the nightly compiler. There's an issue for it and although it's not yet stabilized and there's little documentation for it, it is fully implemented.
To use it, you download a nightly compiler (rustup toolchain add nightly), put this annotation at the top of your main.rs or
lib.rs file:
#![feature(type_alias_impl_trait)]
and compile with cargo +nightly run. Now the example from above is accepted by the Rust compiler.
Cross compilation
Cross compilation in Rust allows us to compile our Rust programs for different target architectures, such as ARM or RiscV, or maybe just for different operating systems (compiling for Windows from Linux) without needing to have that target architecture (or operating system) on the machine we compile on. This can be useful for creating binaries for devices with limited resources (maybe it's not possible to compile on the target device itself!) or for testing our programs on different architectures (within emulators for example).
To set up cross compilation in Rust, we need to first install the necessary tools for the target architecture. For an ARM architecture, this may include the ARM cross compiler and the necessary libraries. We can do that through rustup:
rustup target add thumbv6m-none-eabi
Once the tools are installed, we can add the target architecture to our .cargo/config file. This file allows us to configure cargo, the Rust package manager, to automatically cross compile our programs.
To add the target architecture to our .cargo/config file, we can add a section like the following:
[build]
target = "thumbv6m-none-eabi"
This configures cargo to use the target we want it to: thumbv6m-none-eabi which is also the one we just installed.
We could also add a runner for this specific architecture by adding the following in the same .cargo/config file:
[target.thumbv6m-none-eabi]
runner = "run some command here, maybe start an emulator"
The command gets the location of the compiled binary as its first parameter.
Now we can simply run
cargo run
This will automatically use build the binary for the ARM architecture and run it with our configured runner.
Messaging protocols
When we talked about foreign function interfaces, we briefly mentioned the fact that sometimes we can also use some kind of channel to communicate between languages. For example, TCP or UDP sockets, an HTTP api, unix sockets, the list goes on. Even the UART interface you are making is a communication channel. Of course such communication channels are not just useful for communicating between languages. Maybe you just want to communicate between two programs on the same, or on different machines. For the assignment you have to talk from an emulator to a host computer over UART.
However, we can't just send anything over a communication channel 1. Bytes or byte sequences or are usually easy, but this depends a bit on what kind of communication channel you are using. In any case, sending things like pointers or references is usually quite hard. They're just numbers you might say! But they refer to a location on your computer. For a pointer to make sense to someone we send it to, we also have to send whatever it is pointing to. Let's assume we use UART which only transmits single bytes. How can we transmit arbitrary types over such a communication channel?
The process of converting an arbitrary type into bytes is called serialization. The opposite process of taking a sequence
of bytes. Very simple serialization you can do by hand. For example, you can just turn a u32 into 4 bytes. However, anything
more complex can quickly become hard. Luckily, there is serde. (literally serialization deserialization).
With serde we can annotate any type that we want to be able to serialize. It will automatically generate all the required to serialize it. But not just into bytes. Serde always works in two parts. It always requires some kind of backend that takes types annotated by serde, and turns those into the actual serialized representation. That's not just bytes.
- postcard and can turn types into byte sequences
- serde_json can turn types into json
- toml can turn types into toml, the same format the Rust Cargo.toml uses
- And the list goes on
So, let's look at an example on how we can turn our types into bytes:
use serde::{Serialize, Deserialize}; use postcard::{to_vec, from_bytes}; #[derive(Serialize, Deserialize, PartialEq)] struct Ping { // Some data fields for the ping message timestamp: u64, payload: Vec<u8>, } fn main() { let original = Ping { timestamp: 0x123456789abcdef, payload: vec![0, 1, 2, 3, 4, 5, 6, 7, 8], }; let serialized = to_vec(&original); // serialized now is just a Vec<u8> representing the original message // can fail because our bytes could not represent our Ping message let deserialized: Ping = from_bytes(serialized.deref()).unwrap(); assert_eq!(original, deserialized); }
Serde will recursively go through your structs and enums and make sure that when you serialize a type it will be turned into its bytes in its entirety.
Usually, for these kinds of protocols, it's useful to make our message type an enum. That way we can add more message types later by just adding variants to our enum.
With Serde, both the sending end and receiving end need to agree on the datatypes they use. When the sending end sends a message with a datatype containing an u8, while the receiving end has a type with a u32 in that place, deserializing will fail.
Therefore, it can be useful to make the messages you send a library that's imported by both the sending end and the receiving end. That way the types are guaranteed to be the same.
Starting and ending messages
When sending messages over a channel like UART, you have to be careful. UART only allows you to transmit and receive single bytes of information. How does a receiver know where messages that take up multiple bytes start? There are multiple options, for example you could define some kind of header that defines the start of a message. You have to make sure here that the header never appears in your message which can be hard. You might need to do some escaping/byte stuffing/bit stuffing. It may also help to include the length of the next message at the start of every message to let the receiver know how many bytes to expect.
In any case, it's impossible to have the messages that are transmitted to have all the following properties:
- any byte can be sent over the wire. Data bytes are always seen as data and control bytes are always seen as control bytes
- simple to transmit. It's easiest if we can just write our serialized message directly, however if we have to do escaping then we may need to analyze the message first
- easy to find starts and ends of messages
Message integrity
For many, if not all systems it's critical that we don't misinterpret messages we receive. Therefore we want to make sure that whatever we receive is actually the message that the receiver wanted to send. Imagine if a few bytes are corrupted and instead of putting a motor on a drone to 20%, we put it to 100%.
To ensure that what we receive is actually correct we can use checksums. A checksum is a sort of hash. The sender calculates a number, usually a few bytes based on what they send. The receiving end then does the same for the bytes that it received. If the checksum the receiver calculates does not match the checksum that was sent along with the message, the receiver knows that some part of the message was corrupted (or maybe the checksum itself was corrupted!)
What the receiver does with that may depend on the message. It may choose to ignore messages like that, or could ask for a retransmission.
Assignments
For the assignments, we are giving every group their own git repository. This is how you hand in your assignments, we will grade your last commit. On the repository, you will find 3 separate (and unrelated) folders. One for each of the three assignments.
The repositories will be made as soon as you enter a group on brightspace, usually within a day. Once you have been assigned a group and git repository, please don't leave your group in brightspace since we won't update the repositories anymore (so permissions may become a problem).
Concurrency Assignment
Grep
For this assignment, you will be implementing a concurrent version of grep using some of the concurrency primitives you learned about in the lecture. Afterwards, you are going to dive into the inner workings of some of these primitives.
Grep is a command-line utility for searching a file or directory for lines that match a regular expression.
For example, this searches the current directory for files that contain rust or Rust.
You can use Grep to search through a directory for specific words in files with the following command:
grep -r "[Rr]ust" .
You may be more familiar with using grep together with pipes. For example:
cat <somefile> | grep <somestring>
This is however not what you will implement in this assignment. Instead, the tool you will make will only be able
to search through directories (recursively). The program will function like grep -r. This is very similar to
what a well-known tool does called ripgrep. We won't ask you to match
ripgrep's performance, since ripgrep has been optimized a lot. However, what may be interesting to know is that
the author of ripgrep is also the author of the regex library that you will most likely use for this assignment.
Example usage
A simple example can be found in the template in ./examples/example1/. It contains a single file.
If you run cargo run -- banana ./examples/example1/, the expected output is:
>>> (#0) ./examples/example1/file.txt
apple banana pear
^^^^^^
For a slightly more complex example, take a look at ./examples/example2/.
If you run cargo run -- banana ./examples/example2/, the expected output is:
>>> (#0) ./examples/example2/file1.txt
banana
^^^^^^
>>> (#1) ./examples/example2/dir/file3.txt
banana
^^^^^^
Finally, it is possible to specify multiple directories.
If we specify both examples using cargo run -- banana ./examples/example1/ ./examples/example2/, the expected output is:
>>> (#0) ./examples/example2/file1.txt
banana
^^^^^^
>>> (#1) ./examples/example1/file.txt
apple banana pear
^^^^^^
>>> (#2) ./examples/example2/dir/file3.txt
banana
^^^^^^
For a big example, if you run the following on the linux source code (use git clone https://github.com/torvalds/linux --depth=1 to clone the repo), you should find 6 results.
The [mM]icrodevice is the regex that grep should try to match, the . is the directory it should search in, . meaning the current directory.
cargo run -- [mM]icrodevice .
Learning Objectives
In this assignment, the goal is to learn about:
- Implementing concurrency using Rust's primitives
- Understanding and utilizing atomic operations
- Exploring Rust’s threading and parallelism libraries
- Optimizing concurrent code for performance
Requirements
This assignment consists of two main parts.
- Source code you hand in through a GitLab repository you get (7 points)
- A report which should be a PDF you hand in the root of the same git repository (3 points)
With each part you can gain points, which start counting at 0 and are capped at a 10 which will be your grade. It is required to hand in both source code and a report. Not doing one of the two at all means you fail the assignment.
Source Code: 7 points
In order to receive up to 4 points for this assignment, the code you hand in must:
- Be able to search a file or directory for all occurrences of a regex pattern.
- This means if a pattern matches multiple times in a single file, you must report all matches
- Print output while it is searching. (It shouldn't buffer the results and print them at the end)
- Print the results only using the provided
Displayimplementation. Results should be put intoGrepResultstructs and printed. This will make sure their formatting is consistent. - Make sure the
search_ctrnumbers during printing are in increasing order. - Make sure the output is well-formed.
- Be concurrent, that is, should use multiple threads.
- Be thread safe. Any pattern that may work for a limited input, or which depends on being lucky with how the scheduler schedules your threads is considered incorrect.
- Not use any unsafe code.
- Compile on stable rust (1.81).
- Dynamically determine how many threads it should use based on the number of cores the system has.
- You must not spawn many times more threads than your system has cores. On large folders, you should not spawn millions of threads.
Banned Libraries
You are not allowed to use any libraries except what is provided for the core part For additional points you may import rayon, tokio or another async executor to complete the bonus tasks
To gain additional points, you can do any of the following tasks:
- Be faster than GNU
grepand show this in your report based on a benchmark: 2 points - Your code does not panic (hint:
Mutexis special): 0.5 points - Experiment with rayon: 1 point
- Implement the same code you have using
rayonlibrary, and choose this topic for one of your report subjects
- Implement the same code you have using
- Experiment with async: 1 point
- Implement the same code you have using async rust, and choose this topic for one of your report subjects
For these extra points make sure all versions of your solution are available on the main branch.
Rayon and Async Rust
You can also choose
rayonorasync rustas your report subject and not implement grep using it. That is still a valid report, but will not get you the 1 extra point for the source code section
Report: 3 points
Write a report consisting of the following
- Write up on two topics (one per team member) of your choice from the list below: 2 points
- performance report with benchmark if your implementation is faster than GNU
grep1 point
The report must not exceed 3 pages:
- 1 page maximum for each topic
- Additional page for the performance report
You should choose two subjects from the following list, one per group member. Note that you do not actually need to implement your code using any of these techniques.
A report that aims to get a 10 should, both in style and in citation, try to emulate Stacked borrows: an aliasing model Rust
What to write?
The goal of the report is to showcase your grasp of a concept. Rather than demonstrating that you’ve understood the documentation, aim to go beyond it in your investigation. The expectation is for the topics to be explored, analyzed, and deeply understood. Teach us something new—something we might not know! Explore various resources such as papers, blog posts, and videos (We expect you to cite at least one reputable source). The idea is to craft each topic write-up like a small-scale exploratory paper. You could also think of creative ways to apply the concept differently than usual. It’s up to you—make it fun, make it interesting!
ArcvsRcin std: explain the differences, when you would use each, and how each works internally. Talk about the difference between strong and weak reference counts, and whatSendandSyncmean. Generally show to us that you understand the implementation.MutexvsRwLockin std: explain the differences, in which situations you would use each, and how each works internally. Talk about how aRwLockis implemented, and what the term "interior mutability" means and what this has to do with aMutex. Generally show to us that you understand the two.- (
std::sync::mpsc) Channels: explain how a channel works internally. Talk about the different channel variants, and based on what factors Rust chooses the variant at runtime. This may mean you have to look at the source code implementation of channels. Talk about the advantages of a channel compared to a Mutex. Generally show to us that you understand how channels work. - Atomics and Memory Ordering: Explain how atomics work in hardware on x86_64, and how they relate to the cache of a cpu. Explain what a memory ordering is, and why the different memory orderings are important and how this relates to memory models. Why does
compare_exchangeneed two memory orderings? Also demonstrate the use of an atomic variable in yourgrepassignment. - Rayon vs Advanced Computing Systems: you may notice that the
rayonlibrary can do many things that the OpenMP library can do which you used during the Advanced Computing Systems course. Report on how rayon schedules tasks, how it is different to OpenMP and what your experience of using it is compared to OpenMP. Also talk about what the advantage is of using rayon over the custom thread-based approach you used for the base implementation of yourgrepassignment. Note that you can also implementgrepusing rayon for bonus points, see the requirements forgrep. - Async/Await: Rust has a feature that allows code to asynchronously wait for jobs to complete, moving scheduling from the operating system to user space. Report on how async/await works, how it is different to async/await in other languages like for example Python, C# or JavaScript, and in what situations you might want to use async/await over normal threading. Also discuss what an executor is. Note that you can also implement
grepusing async/await for bonus points, see the requirements forgrep.
Performance
In this assignment, you will be improving the performance of a raytracer.
A raytracer is a program which simulates the physics of light. Through a scene of objects, light rays are reflected and refracted to create a rendered image. However, unlike the real world, rays of light are not cast from light sources. Instead, they are cast from the camera and simulated through the scene towards light sources. That way, all the light rays which don't hit the camera do not need to be simulated. A raytracer is like a camera simulated in reverse.
The image below is raytraced with the reference implementation, on the reference hardware (listed below) in about 30 minutes. Below we say our reference render runs in 10 seconds, but that's only because the reference image (which you can find in your repository) is a lot lower quality.
In the image, the only light source is the lamp on the ceiling. The raytracer will programmatically scatter and reflect rays around all the objects in the scene. Since fewer rays hit the wall behind the tall block and find their way into the camera, a shadow is formed there. Well, I say "find their way into the camera", but the way a raytracer works is the other way around of course. Fewer rays from the camera hit the ceiling light there.
The graininess is formed since for each pixel, a couple of rays are traced with slightly different properties, which all reflect in slightly different ways. The more samples we take, the less grainy the image becomes.

The template you get, started out as an acceptable raytracer. On our machine with:
- 32Gb Ram
- AMD Ryzen 9 5900HX with 8 cores + hyper-threading
It could render an image (with the same configuration as we give you) in under 10 seconds. Of course, the actual performance may differ on your hardware. However, we deliberately changed the code to make it extremely slow and inefficient. Now it's your job to find the performance issues and fix or mitigate them.
Assignment
Find and describe at least 5 sufficiently distinct techniques to improve the performance of the code. Ensure these techniques are applied to the entire codebase and not ad-hoc. Apply at least 3 of the techniques discussed in class. You can make any modification to the codebase you like, as long as you don't violate any of the following requirements:
- The changed program should still output a raytraced image in render.bmp, which (ignoring differences due to random number generation) should be the same as the reference raytraced image.
- You cannot hardcode the output, or any intermediate steps. The program should still actually perform raytracing.
- You cannot import existing libraries which already implement (any substantial part of) raytracing.
- If you use unsafe code, it should be accompanied by a (correct) safety disclaimer proving its soundness.
Note that it should not be necessary to change or understand the raytracing algorithm. Even if you don't fully understand know how raytracing works, you can still do this assignment.
Overview
In the project root there are two important folders. configurations and src. In configurations there
are files that are loaded to configure the raytracer. In the src folder you
will find a number of subdirectories which contain parts of the raytracer:
configcontains the code to parse the configuration filesraytracercontains the code that casts rays into the scene from the camerascenecontains the code that keeps track of the entire scene, and all the triangles, and vertices in itrenderercontains code to construct the raytracer. Usually this is executed based on the configuration fileshadercontains shaders. A shader is a function that's executed for every cast ray which basically turns it and the information gathered from it into a colorutilcontains some utilities, like an abstraction for 3d Vectors and a struct representing a color.generatorcontains a sort-of scheduler. There are two options,basicwhich just sequentially fires rays for each pixel in the final image, whilethreadedwill split up the work and divide it over a number of threads. For example, when there are supposed to be 5 threads, the image is carved up into 5 parts and each thread will raytrace a part.datastructurecontains code that can hold the scene in an efficient format. This format (a sort of 3d Tree) makes it possible to figure out whether a ray hit a triangle in logarithmic time instead of linear time. Note that we kept in this reasonably efficient datastructure, so you do not need to worry about optimizing it. You can assume it's reasonably efficient, and in any case it's not a simple datastructure, so it may take a lot of time to make it better.
Running the raytracer
You can simply use cargo run to execute the raytracer. By default, it uses configurations/reference.yml as a
configuration file. You should keep the settings the same (changing them won't count as a performance improvement!).
However, the default config specifies a 500x500 image. After some performance improvements, this should be fine. However,
initially, this size will take ages to render.
You can experiment with rendering at smaller sizes to test changes in your code more easily.
You will see that there is both a lib.rs and a main.rs file. The main.rs is so you can simply run cargo run. However,
when you want to import the raytracer in benchmarks, you will actually use raytracer as a library through the lib.rs file.
In both the main.rs and lib.rs files you will find a path to a configuration file that is used, which may be useful
to change if you have multiple configurations. Note that we already removed quite a lot of configuration options, the original
raytracer had more. Again, you shouldn't have to touch the configuration much.
Hint: it may help to start with some profiling to see what parts of the program are slow.
Learning Objectives
In this assignment, the goal is to learn about:
- Understanding performance optimization techniques
- Profiling code for bottlenecks
- Implementing and evaluating optimizations
- Benchmarking and properly documenting the results
Grading requirements
The goal of this assignment is on finding performance optimizations and properly documenting them. Finding the most improvement is of secondary importance and should not be the main focus!
For a passing grade of a 6:
- Apply at least 3 of the performance improvement techniques discussed in class
- Apply at least 5 (distinct) performance optimizations
- For every new method you find to improve the codebase, you should report on how it improved the code compared to a previous version which already had some optimizations instead of comparing it simply against the baseline.
- Write at least 1 benchmark using criterion or another established benchmarking tool to evaluate the performance of your changes.
- Write a report containing the following in a coherent structure:
- For every optimization, write at least 150 words in which you:
- Describe what it is and how it works
- Describe why it makes the code faster
- Describe how you discovered this optimization. Why did you go for this approach? Did it have the effect you expected?
- Show some kind of benchmark (does not need to be with criterion) which proves it made the code faster compared to a previous version of your code
- You do not get any points if you don't write about it in your report.
- In what order you discovered each of the optimizations.
- What hardware you used to benchmark, and in what way does that impact the benchmarks you ran
- When writing this report, you can follow the Overleaf template (zip_file_download) provided by us, you can preview it here or just use it as a guideline for your own structure and format.
- For every optimization, write at least 150 words in which you:
To gain extra points:
- Find more ways to increase the performance of the code (depending on the complexity, your description and the effect it has, roughly 1 point per optimization)
- Separate benchmarks (using criterion or established benchmarking tool) for each of your optimizations and the effect they have compared to the baseline or to the previous optimizations: 1 point
- Make sure to substantiate why you are making the benchmarks and what you are comparing them to either previous ones or baseline.
- After you hand your assignment in, we will benchmark your code against our original. If your code is faster than the reference you get 0.5 bonus. You can ask TAs to benchmark your code before you hand in. NOTE THAT THIS IS NOT THE POINT OF THIS ASSIGNMENT. It's a cool bonus, but the goal of this assignment is not to make a fast raytracer, but to find optimization possibilities in a large codebase, and describe those. Making an actually fast program is NOT THE MAIN GOAL.
Important:
Read the grading requirements carefully. The point of this assignment is NOT to make the fastest possible raytracer but to find ways to improve it. We mainly grade your report, if you wrote a bad report and have the fastest raytracer imaginable in the world, it still means you do not pass this assignment.
Embedded Systems
In this assignment you are going to build a small program running inside an emulator which emulates a Stellaris LM3S6965 microcontroller with an ARM M3 core.
You will be building a kind of GPS step counter that records changes in position, counts steps and displays some information in a graphical interface.
You will design a protocol to communicate with your system and implement a UART driver which provides a channel to communicate over.
Installation Requirements
You need to install two programs, namely QEMU for ARM (emulates ARM devices) and some tools to build a valid program to run inside the emulator
- for QEMU:
qemu-system-arm(this is the name of the binary, which might not work on some Linux distros) - for the tooling:
cargo install cargo-binutils(or the equivalent with your package manager if that's supported)
A note on Operating Systems
This assignment is only well tested on Linux. We are pretty sure this does not work on Windows, possible with some hassle on WSL2. For MacOS we have heard people being succesful but we have no personal experience with it
Furthermore, you will be compiling programs to run in an ARM emulator. That means that the Rust compiler will be tasked to generate ARM assembly code. This is called cross-compilation, and is quite easy with Rust. You simply have to run the following command:
rustup target add thumbv7m-none-eabi
This command will download all the required files to generate thumbv7m assembly code (ARM). After this, rust will know
how to compile arm programs. You can take a look at other supported targets with rustup target list. Make sure that thumbv7
is highlighted in this list, marking it as installed.
During labs, we've seen that some people have some issues installing some components related to
cargo-binutils. What seems to solve this, is after adding the arm target to the compiler running#![allow(unused)] fn main() { rustup update rustup component add llvm-tools-preview }And to make sure that your path variable (run
echo $PATH) contains/home/yourname/.cargo/bin
Description of the assignment
This assignment is split up in two parts.
Part 1: UART
First, you'll implement a UART driver for the Stellaris LM3S6965. A rough template is already provided.
The manual for the Stellaris LM3S6965 can be found here. It is very useful, and contains all the information you need, make sure to read it carefully. Additionally, the PAC crate we include can help you out. While implementing your UART driver, very carefully think about which kinds of operations might be undefined behaviour.
The driver
In the template we already provide, what we call, the runner. This is a program that starts the qemu emulator of the Stellaris LM3S6965 with your program running inside it through a library we provide. Afterwards, you can communicate with the program running inside the emulator over simulated UART serial, just as if the Stellaris board was attached to your computer through a wire, but without actually needing the hardware.
To test your UART driver, we already provide a basic skeleton in the runner that simply prints any bytes it receives over serial. Your driver should in the end be capable of both sending and receiving messages to the emulated Stellaris board.
Abstractions
For this assignment, carefully think about what abstractions you need to ensure that your UART driver has no undefined behaviour.
Also recall what you learned about this in the lectures.
To write your code, you will need to use unsafe code. However, keep in mind that for every use of an
unsafe block in your code, you are expected to explain why that block is necessary there, and what pre-conditions,
post-conditions and/or invariants need to hold for that unsafe block to be sound,
and show that those conditions are actually checked, to make the code indeed sound.
Note that this may be more verbose than you will make your explanations in the field (though we do recommend it), but this explanation is part of your assessment,
so it needs to be complete.
Part 2: Protocol
Once you have built a driver for the UART peripheral of the Stellaris LM3S6965, you should be able to exchange simple byte-sized messages. However, almost any real-world application requires a more elaborate communication protocol than this. In the second part of this assignment, you will be designing such a protocol to communicate with the board, and to send it higher level commands to draw things on the screen.
Next quarter, during the Embedded Systems Lab, you will be communicating with a flying drone similarly, over UART. Therefore, you can see this as a practice assignment for that course. We encourage you to reflect on what you made, and to see what you can improve for next quarter if you did not like how you did it in this assignment.
Creating a shared library
The types that will be serialized will most likely be the same for both the runner and the board. It may be useful to create a library of code that is shared between the two (i.e. compiled both for the runner and the server). That way, if you add fields to structs, they are updated both for the runner and server.
You can just create it using cargo new --lib library_name, and then add library_name to members the
root Cargo.toml.
We also recommend adding the following to the top of the lib.rs to enable the standard library while testing this shared code.
#![cfg_attr(not(test), no_std)]
#[cfg(test)]
extern crate std;
// your code hereCommunicating reliably
Because we use an emulator, communication is 100% reliable. But that's not generally true in the real world. What if a byte is dropped? To make sure your system works when the connection is unreliable, you should add checksums to all communication. Similarly, you must make sure that if bytes are lost from a single message, future messages are readable again.
Learning Objectives
In this assignment, the goal is to learn about:
- Programming without an operating system
- Creating safe abstractions over unsafe code
- Using peripheral/hardware abstraction libraries
- UART and serial communication
- Creating a simple, fault-tolerant message protocol
Requirements
Note that in the template, signatures are a guideline to help you, but may need to be changed to support for example error handling.
Note that there are a number of "TODO"s in the template code. You should resolve these.
You will be building a tiny application that processes messages and displays information on the screen.
External Library Policy
Explicitly allowed:
- Logging libraries
- Serialization libraries
- Data structure libraries
- Data integrity libraries
- User parsing libraries
- Framebuffer drawing libraries
Explicitly not allowed:
- UART Libraries
- Mutex Library
UART driver
- You must create a safe interface through which to send and receive UART messages
- You must provide a safe abstraction for global mutable state (Mutex)
- You must preventing two threads executing at once. Of course there are no threads in the system you are implementing the driver for, but concurrency is still an issue.
- This may need
unsafecode, you must add an explanation on why your implementation is still sound.
- You must provide buffering such that long messages can be sent and received.
- The buffer must be fixed-size, and must be sized appropriately for the messages that are sent over them.
- If the buffer fills up, the program must not crash.
Communication
While the emulator runs, it should keep track of a "location" and amount of steps.
- You should be able to record changes in position (dx/dy in meters) and remember that state in the program.
- You should be able to record "a step" that is also kept track by the program running in the emulator
- You should be able to send a message to the program to change the currently viewed page
- You should use checksums to verify the integrity of your messages
- If messages are dropped, or corrupted, you should make sure that your system can continue reading future messages. Test this.
- You must use the
serdelibrary
Interface
In this section, some choices are left up to you. You can be a bit creative here.
- The Graphical Interface must contain two views
- A map of where the user has walked, 1 pixel = 1 meter. You can assume the user won't walk far enough to leave the screen boundaries.
- A simple counter view which shows total number of steps taken
- The runner should get a simple interactive interface in which you can simulate sending messages to the system by typing commands. You should be to send messages corresponding to the following actions:
- A single step being taken, and the corresponding dx/dy movement.
- A help page (for us) so we know what to type
- A command to request the current total number of steps recorded by the Stellaris board
- A reset command, that resets the state of the Stellaris board to its initial state, so 0 steps taken
General
- Every use of unsafe code must be sound (i.e. we will assess your use of unsafe code and check that what you are doing is sound).
- Every use of unsafe code should have a comment explain the entire reasoning required to understand why that block of unsafe code is indeed sound.
Grading
You should implement each of the numbered requirements above as specified. Your grade starts at a 10, and for each requirement you don't implement to spec, a point is removed. Partial points may be subtracted for partially correct implementations.
Getting started
Look in the uart.rs file. Some hints and function signatures are already given for you to implement. If you have any
questions about them, feel free to come to the lab and ask them to one of the TAs.
Debugging
The Runner::new function takes two parameters: the binary to run in the emulator, and a boolean flag: wait_for_debugger.
If you pass true here, and run your code, the emulator seems to get stuck while booting.
However, it is actually just waiting for you to attach a debugger, with which you can step through and debug the code while it is running in the emulator.
To do this, get a copy of gdb that works form ARM (arm-none-eabi-gdb or gdb-multiarch), and start the emulator to a point where it's waiting for a debugger to attach.
Now, in a separate terminal, run arm-none-eabi-gdb.
To attach to the emulator, use target remote localhost:1234, and then to get source debugging, use: symbol-file target/path/to/the/binary/with/embedded/code.
I usually like to do this directly from the commandline with:
arm-none-eabi-gdb \
-ex "target remote localhost:1234" \
-ex "symbol-file target/thumbv7m-none-eabi/debug/embedded-assignment" \
-ex "layout source" \ # also see the source code
-ex "focus cmd" \ # but put the focus on the command input
-ex "b main" \ # short for breakpoint
-ex "c" # short for continue to next breakpoint (so to main)
You can also write a .gdbinit file in the root of your project, with these commands in it.
Installation Manuals
Installation Manuals
Using PlantUML in Jupyter Notebook
This year, we highly encourage everyone to PlantUML with Jupyter Notebook for the UML part. You can either install Jupyter Notebook with VSCode, or use it with Anaconda.
Please follow the following instructions for installation:
- Using Jupyter Notebook in VSCode: https://code.visualstudio.com/docs/datascience/jupyter-notebooks
- Using Jupyter Notebook with Anaconda: https://docs.anaconda.com/ae-notebooks/user-guide/basic-tasks/apps/jupyter/
While you can largely reuse and follow the Jupyter Notebook templete/example we provided, to use PlantUML in Jupyter Notebook you need install the iplantuml Python package: https://github.com/jbn/IPlantUML
Listed below are other ways (kept from last year) that you can use PlantUML. You can skip them if you decided to use Jupyter Notebook.
Installing PlantUML in VSCode
- Go to the Extensions page
- Type in PlantUML and Install
jebbs.plantuml - To create a PlantUML file:
- Click
File | new Text File - Select the language by pressing
Ctrl + K, let go and then pressM - Type "PlantUML" and select it
- Click
- When you want to render your PlantUML script:
- Press
Ctrl + Shift + Pto open the palette - Type "PlantUML"
- Select "PlantUML: Preview Current Diagram"
- Press
Installing PlantUML in CLion
- Go to
File | Settings | Plugins - Type "PlantUML Integration" and Install
- To create a new PlantUML file:
- Click
File | new | fileand create a<name>.pumlfile
Rendering Online
You can always access the online PlantUML Web Server to render your PlantUML instance.
Troubleshooting
On Linux you might get a rendering error if you are missing graphviz.
To fix the error you only need to install the dependency:
sudo apt install graphviz
Installing itemis CREATE
IMPORTANT:
To be able to use itemis CREATE after the 30-day trial period it is necessary to obtain the academic license. The steps for doing so are explained below.
After you have submitted your application for the license it can take up to 7 days for your application to be reviewed. We advise you to install the software as soon as possible to be able to work on your assignments.
Download itemis CREATE
- Navigate to the website for itemis CREATE
- Press DOWNLOAD NOW
- Input your details and student email and download the software
Obtain the Academic License
- Navigate to Licenses
- Press GET IT NOW
- Input your details and student email and submit
- Check your email and follow the instructions there
After your application has been reviewed you will receive an email with your license in an .lic format.
Activating your academic license
- Open itemis CREATE
- Select Window|Preferences
- Press on Version control | itemis CREATE Licenses
- Press on Import Version file and browse to the location of your license
.licfile - At this point, your trial period should have increase to 365 days, and your license is updated
Lark
This year the DSL assignment will be done using LARK with Jupyter Notebook. You can either install Jupyter Notebook with VSCode, or use it with Anaconda.
Please follow the following instructions for installation:
You will be provided with three Jupyter Notebooks: 2 for the tutorial, 1 for the assignment.
Lecture Notes
Personalized lecture notes will be added here after each lecture. They attempt to recount everything notable that was discussed or happened during the lecture. The notes include your questions and answers during class.
Lecture 5
Introduction to Model-Based Development
What are some examples of complex systems?
- Drone swarm
- Philip's X-ray system (looks like this student has already looked at the assignment)
- ASML machine to create computer chips
- Missile system
What makes a problem complex?
- Many interacting components
- Large code-base which is difficult to test
- Code is reused for many generations of products
- Multiple teams cooperating (with different domain knowledge)
- Performance requirements
- Dependability requirements (might have to stay online for many years)
How to deal with complexity?
- Divide and Conquer, modularity
- Top-down or bottom-up approaches to design
- Small and targeted test-suites
In this course we describe these four approaches:
- Abstraction: Identify high-level concepts that hide low-level details
- Boundedness: Impose acceptable restrictions on the considered problem space
- Composition: Divide one problem into multiple independent smaller problems
- Duplication: Use multiple overlapping approaches for the same problem (redundancy)
What is model based development?
- Models capture "the essence" of the system to help understand the behavior of the system
- Communicating ideas
- Early validation
- Automated testing
More acronyms to keep in mind:
- KISS = Keep it simple, stupid
- DRY = Don't repeat yourself
Unified Modeling Language (UML)
Three categories of UML diagrams:
- Structure
- Behavior
- Interaction (subcategory of Behavior)
UML is a collection of standardized graphical notations.
Why bother with UML?
- Clarity: bring clarity to complex design
- Communication: a universal language for diverse teams
- Documentation: a valuable way for future reference
Use case diagrams
- Collection of actors, use cases, and their associations.
- Describes a very high-level overview of the system from an outsider's perspective.
What do you see in this diagram?
- The clinic has all the features that you want. The people on the left are interacting with the clinic. The patient has access to most of the system.
- Maybe there should be directions from the actors to the use cases? (No. See below.)
- There are actors on the left, use cases inside the system, and associations that show which use cases are associated with which actors.
A use case diagram shows us who are the users of the system and how they interact with it.
There are four different types of elements in a use case diagram:
- Actor: represents a role played by a user or any other system that interacts with the system being modeled.
- Focus: who will use the system?
- Represented by stick figures
- Actors must be external entities
- Use case: summary of scenarios
- Represented by horizontal ovals
- System boundary: separates actors and use cases
- Defines the scope of the system
- Associations: illustrates the relationship between an actors and use cases
- Represented by solid line between an actor and a use case (no arrow!)
The students were given a task to create a use case diagram based on this system description:
Imagine a Library System that has two main types of users: Library Members and Librarians. Library Members can use the system to borrow books to take home and return books when they have finished reading. They can also search their book of interest. On the other side, librarians are responsible for updating the catalogue and managing memberships. Both library members and librarians can search books.
Here is the diagram Brendan created on the board during class (recreated in PlantUML):
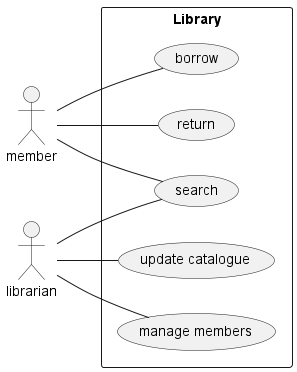
PlantUML code:
' Brendan's diagram
@startuml library
left to right direction
actor member
actor librarian
rectangle Library {
usecase borrow
usecase return
usecase search
usecase "update catalogue" as update
usecase "manage members" as manage
}
member -- borrow
member -- return
member -- search
librarian -- search
librarian -- update
librarian -- manage
@enduml
Later we looked at a more detailed model of the same system.
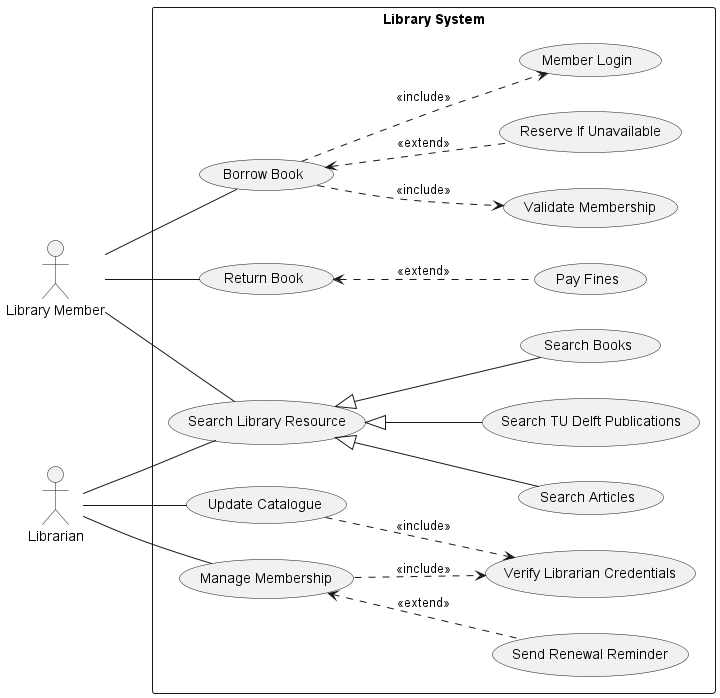
What has changed?
- More information has been specified
- Increased complexity
- Different types of relationships (See below)
Generalization:
- One use case is a more general version of another use case
- Empty arrow head
Include:
- One use case is a substantial part of another use case
- Dashed arrow
- Stereotype
<<include>>
Extend:
- Optional / conditional component of a use case
- Dashed arrow
- Stereotype
<<extend>>
When would we use a use case diagram?
- During the design of complex systems to keep track of interactions between systems (Isn't this true for all modeling methods?)
- Communication with non-technical members of the team, communication with the client
- Typically used in the early phase of the design
Lecture 6
Class Diagram
What are classes and objects (in OOP)?
A class is blueprint for an object. It describes what an object will be, but it is not the object itself. An object is particular instantiation of a class.
Rust is not an object oriented programming language, but it does support the paradigm. See the relevant chapter in the Rust Programming Language Book.
A class diagram describes the structure of classes in the system and the various kinds of static relationships among them.
It visualizes:
- static properties and operations of classes
- attributes, methods, associations
It does not show:
- how the classes interact dynamically
- implementation details
When to use:
- Describe the structure of the system
- During conceptual modeling
- Translating models into code
Class notation:
- Class is inside a rectangle
- Name is in a box at the top
- Fields (also known as attributes or properties) in the middle
- Methods at the bottom
Class relationships
We covered several relationships that can be shown on a class diagram.
Simple association
- Solid line without arrowhead
- Mainly used to show cardinality between classes
Generalization
- Represents "is-a" relationship
- Solid line with hollow arrowhead
- Used for inheritance
- Points from child to parent
Aggregation
- Represents "is part of" relationship
- A solid line with an unfilled diamond
- The child object can exist even without parent
Composition
- Represents "is entirely made of" relationship
- A solid line with a filled diamond
- Objects have the same lifetime
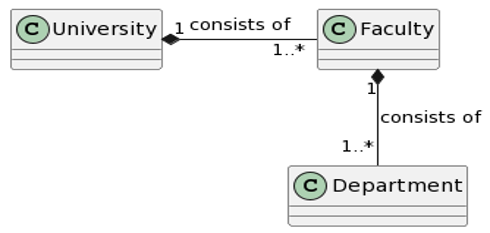
In Rust, aggregation and composition have a nice interpretation.
A composition can be thought of as a field on the parent. Any instance of A will have ownership of an instance of B. Once A is dropped, B will also be dropped.
#![allow(unused)] fn main() { struct A { b: B } }An aggregation can be thought of as a field with a reference to the child. It could be a
&T,Rc<T>, orArc<T>. What is important is that the child can exist even without the parent. The child can outlive the parent.#![allow(unused)] fn main() { struct A { b: Arc<B> } }
Component Diagram
Component diagram divides a complex system into multiple components and shows the inter-relationships between the components.
Components represent a module of classes that are an independent system with the ability to interface with other rest of the complex system.
It is useful for:
- Show the organization of the system (physical and software structure)
- Show the system's static components and their relations
Component Notation:
- A component is a rectangle with the stereotype
<<component>>and/or an icon. - Components can be grouped into packages which are also represented with named rectangles.
Types
We covered two ways to make component diagrams:
Dependency:
- Indicates that the functionality of one element depends on the the existence of another component
- Dotted arrows are used between components with labels
- Higher level form of component diagram
- Think about
usestatements or the dependency list inCargo.toml

Assembly:
- Tells you exactly what information is being used by each component
- Connections between components go through interfaces
- Provided interface: Circle on the end of a solid line (sometimes called a lollipop) that represents something the component provides, generates, or gives
- Required interface: Open arc at the end of a solid line (sometimes called a socket) that shows that a component depends on some provided interface
- Every interface has one exactly one component that provides it
- Multiple components can depend on the same interface
- You can have multiple interfaces between two diagrams if they are passing information back and forth or if multiple different interfaces exist between the components (even one-way)
Deployment Diagram
A deployment diagram shows how a system may be deployed in the real world. It is a type of structural diagram that shows a system’s physical layout, revealing which pieces of software run on what pieces of hardware.
- It shows the physical deployment of the software elements
- It illustrates runtime processing for hardware
- It provides the topology of the hardware system
The diagram is made up of nodes (the boxes) and connections (solid lines between nodes).
<<software>> and <<hardware>> stereotypes are used to distinguish between types of nodes.
It is possible to combine component and deployment diagrams.
Note that the example above uses dotted arrows in place of sockets for the required interfaces. In your assignments, please use the socket notation (
--(in PlantUML).
Sequence Diagram
A sequence diagram models a single scenario in the system. The diagram shows how example objects interact with each other and the messages that are passed between them.
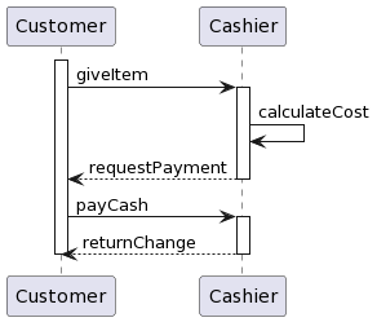
What do you see in this diagram?
- Sequence of interactions or actions
- Action of buying remains active while the Cashier is active.
- Do dotted lines mean that the messages are optional? No, they are used for simple return messages.
A sequence diagram shows:
- Lifetimes of participants
- What messages are sent between participants
- How objects are activated
- Which object is controlling the flow
Notation
Participants
- Rectangle or another icon
- Can be named or anonymous, with syntax
ObjectName:ClassName - Lifetime of the participant is shown with a vertical line
Messages
- Arrows going from one participant to another
- They have labels to describe the content of the message
- Different arrow types have different meanings (mainly synchronous vs. asynchronous) (see the tutorial for more information)
Activations
- Thin rectangle on top of lifetime
- Signifies that the participant is performing an operation or action
Opt Fragment
- Used to mean that the fragment only executes only if some condition is true
- Condition in square brackets:
[condition]
Loop Fragment
- Signifies some fragment executes multiple times while the condition is true or for each item
- Condition or collection in square brackets:
[while cond]or[for each item in collection]
Alt Fragment
- Shows possible alternative executions depending on situation
- Similar to
if / else if / elseormatchexpressions - Each case is separated by a dotted line, with situation described in square brackets:
[condition]
Other fragment types exist, such as
breakfor breaking out of another fragment,parfor parallel execution, orcriticalfor critical sections.
Lecture 7
Finite State Machines
Background and Motivation
What is an FSM?
- Mathematical model of computation.
- Diagram describing states that a system can be in and the transitions between these states.
- Model of computation with a finite number of states.
What parts (or type of logic) do you need to realize an FSM?
- A single start state
- An optional final state
- Transitions between states
- The other states
- Inputs/outputs
- Sequential logic to remember the state
- Combinatorial logic for the state transitions
What FSMs do we know?
- Moore: output depends only on the current state (outputs on states)
- Mealy: output depends on input and the current state (outputs on transitions)
What is a possible problem with simple FSM representations?
- Explosion of the number of states and transitions
FSMs are a practical way to describe behavior
- User workflow: In which environment will the system be used?
- System behavior: What is the logic that the system should implement?
- Communication protocols on interfaces: How should concurrent components interact with each other?
Exercises
We looked at and discussed several finite state machines. Students were asked to explain how each state machine worked.
What would the elements in this FSM mean?
- Two states (On, Off)
- A start state (Off, pointed to by black circle called entry point)
- No terminal state
- Two transitions (Off -> On: switch, On -> Off: switch)
- This diagram describes the behavior of a light switch (based on the picture on the right) which begins in the Off state and can alternate between Off and On when switched.
- Does the light switch on the transitions or at the states? Is this a Mealy or Moore machine? The diagram does not say.
See the slides for an explanation of states, transitions, and events.
What would the elements in this FSM mean?
- Same states as previously (Off and On, with Off as start state)
- On
entryto Off, setsbrightnessto 0. - On switch from Off to On, set
brightnessto 10. - When in On and the
changeBrightnessevent is received- if
brightness<= 1: set to 10 - is > 1: decrease by 1
- if
- On switch from On to Off, run entry of Off again
Q: Is there an infinite loop? Maybe transition 3 would set the brightness to 10 and then transition 2 would loop, decreasing the brightness by 1, until transition 3 is valid again and repeat.
A: No, the transitions are only triggered on the changeBrightness event.
Q: Can you have transitions which do not cover the whole space of possibilities?
(Such as changing the condition on transition 3 to brightness > 2.)
A: Yes, it is possible, but the diagram no longer models what you want.
Explanation of transition 3
- Triggering event
changeBrightness - Condition
[brightness <= 1] - Action
brightness = 10
See the slides for an explanation of variables, guards, and effects.
What would the elements in this FSM mean?
- New in this FSM: transition using
after. - On
entryto Off:brightness= 0 motionDetectedevent in Off triggers transition from Off to On- on
entryto On:brightness= 1 motionDetectedeven in On triggers transition from On to On (loop)- after 30s in On there is a transition to Off
The result is that the FSM will stay in On after motion is detected until there is no motion for 30 seconds. Then it will transition back to Off.
Modeling skills
#/media/File:Canal_lock.svg)
Ship lock
- two gates (bottom and top)
- two valves (paddle, culvert)
Why is this system interesting to model?
- We want to guarantee safety
- Catastrophic results if both gates are open at the same time
Task: Create diagram that models this system Assume:
- For the valves we rely on time to fill/empty the transition zone.
- For the gates we rely on sensors that confirm certain positions. User interaction:
- Start the next swap
- Possible extension: interrupt a swap?
Here is how Hidde modelled the system on the board:
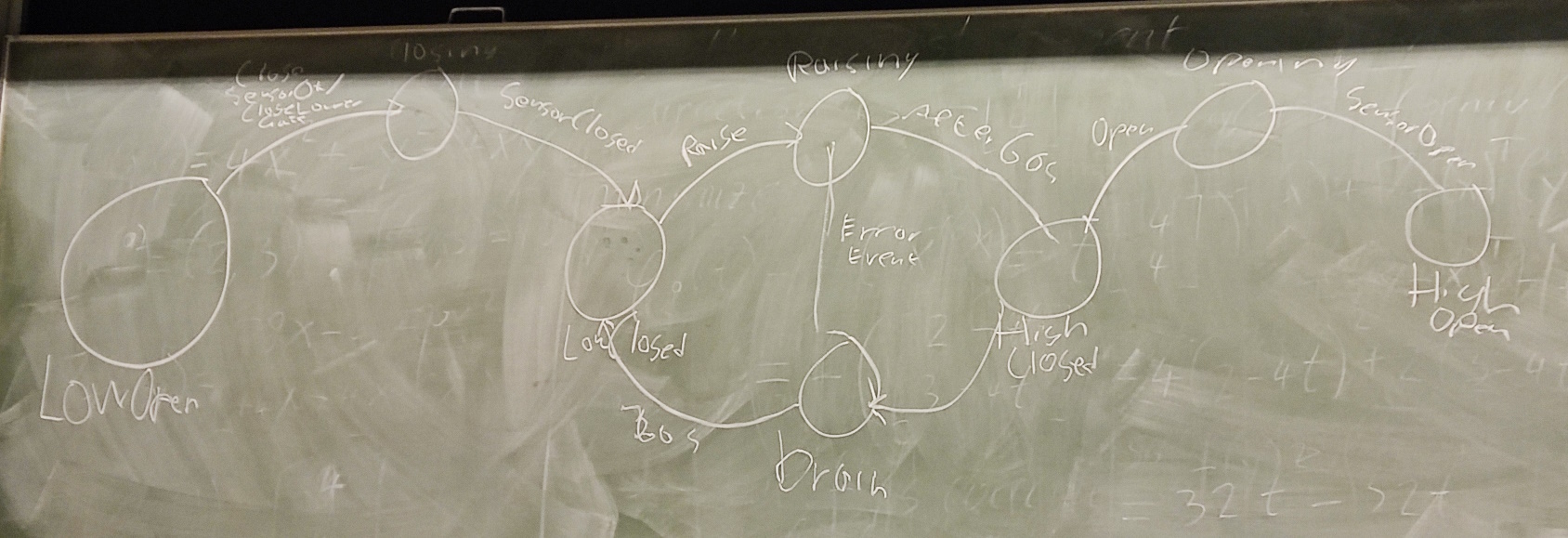
Here is a recreation in UML:
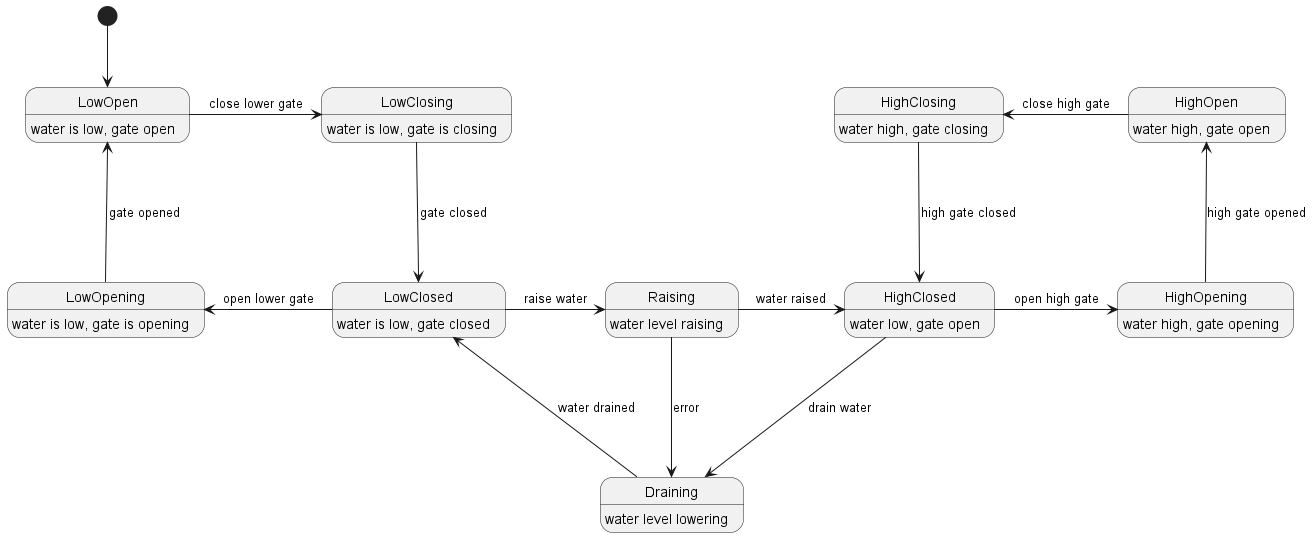
During class we discussed how the model could be simplified by removing certain states. We also appreciated the thought put into handling errors during the Raising state.
Advanced FSM Features
Composite States
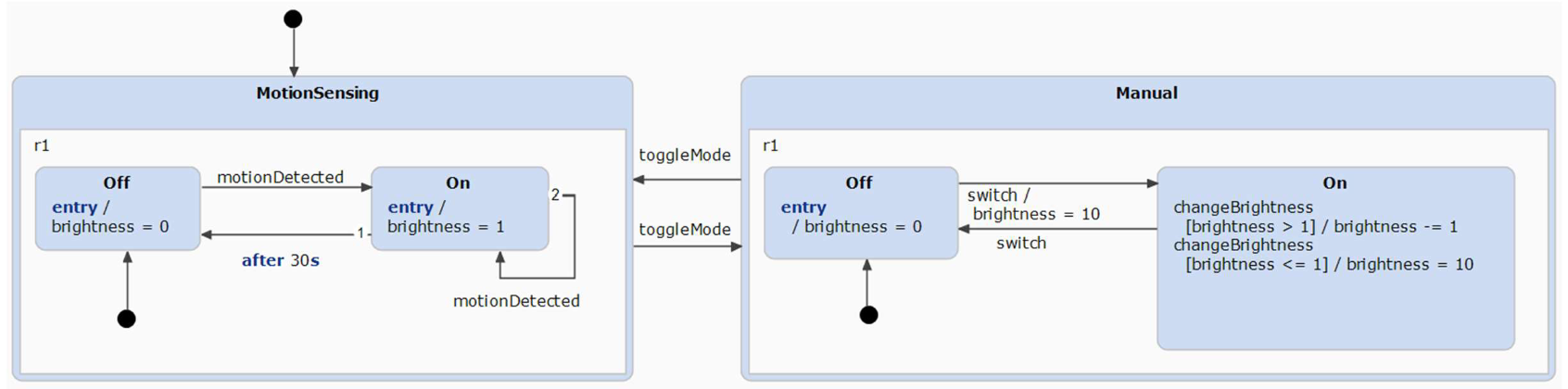
What would the elements in this FSM mean?
- Two composite states (MotionSensing and Manual)
- Sub-states inside these large states
- This is a combination of two previous state machines
- Toggle between the two composite states on
ToggleModeevent
Q: When switching between the composite states, do we go from On to On in the other state, or do we always start in Off?
A: We always start in Off, because that is the starting state in both composite states.
Multiple Entries
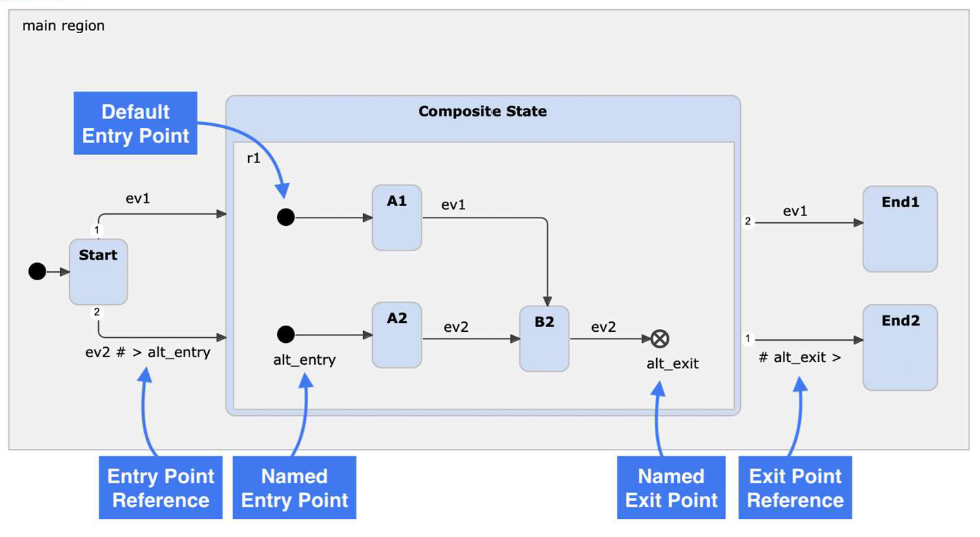
- Multiple entry nodes are possible (with unique names).
- Multiple exits are also possible.
- History nodes allow you to remember which state was active last when we left the composite state.
Q: What happens if we are in B2 receive both events ev1 and ev2 at the same time?
A: itemis CREATE only allows one event at a time, so we cannot simulate it.
Q: Is it compulsory to have a loop in the FSM?
A: Nothing is compulsory, we can have terminal states. It depends on what you are trying to model.
Orthogonal states
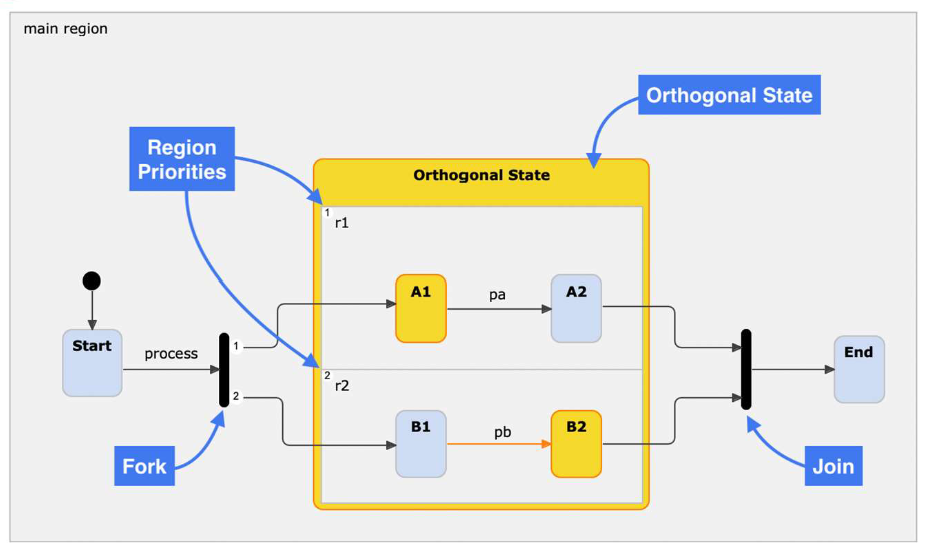
- Orthogonal states allow you to have two or more parallel state machines in one composite state.
- Fork nodes are used to enter into multiple states (otherwise we would only enter the first FSM)
- Join nodes are used to synchronize execution: they wait until all orthogonal state machines have reached the required states.
- Orthogonal regions can communicate via internal events.
How can we exploit FSM models?
- Communication
- With customers: model specification / requirements
- With developers: model of the implementation
- Generation of code
- Validation and verification of model
- Validation and verification of behavior
Tutorials & Lab Work
This chapter contains further explanations of the material covered in the lectures, as well as small tutorials for the tools you will need to use.
Each tutorial contains some exercises or practice for you to do during the labs.
This is how the work is divided up per lab:
- Installing PlantUML and making use case diagrams
- Making component, class and sequence diagrams
- Installing itemis CREATE and creating finite state machines
- Installing Lark and making a DSL
UML
This tutorial covers the basics of PlantUML that you will need to know to create UML diagrams for some lab exercises and the graded UML assignment.
The tutorial is split up with one diagram type per page. You can find exercises at the bottom of each page.
Although we do not refer to the official UML specification in the course, if you are interested, you may find it here.
Use Case Diagrams
This tutorial covers use case diagrams. First, we cover how to use PlantUML to create these diagrams, followed by two small exercises to practice drawing these diagrams.
More information on using PlantUML can be found on the official PlantUML website.
More information on use case diagrams in UML can be found in section 18.1 of the UML specification.
Actors and Use Cases
You can create an actor by using the keyword actor followed by the name of the actor
or by using the colon: :actor_name:
To create a use case you can simply use the keyword usecase followed by the name of the use case
or by using the parenthesis: (use case_name)
@startuml "actors and use cases"
' Create two actors Alice and Bob with aliases A and B.
:Alice: as A
actor :Bob: as B
' Create two use cases with aliases use1 and use2.
(usecase1) as use1
usecase usecase2 as use2
@enduml
Associations
To create simple associations between use cases and actors, write actor_name -- use_case or use_case -- actor_name.
For generalizations use -|>, and for include or extend relationships use .> with the desired stereotype after a colon :.
The more dashes or dots you add to the arrow, the longer the line. Compare
.>and...>.
@startuml associations
' Create an actor and several use cases
actor Admin as admin
usecase "Add Users" as add
usecase "Remove Users" as remove
usecase "Edit Users" as edit
(Authenticate) as authenticate
' simple association
admin -- add
admin -- remove
' generalization
add --|> edit
remove --|> edit
' include
edit ..> authenticate: <<include>>
@enduml
System Boundary
The system boundary separated use cases from the actors.
You can use the keyword rectangle to form a system boundary.
@startuml system-boundary
left to right direction
:Alice: as alice
' Create a system boundary
rectangle "System" {
' Define use cases within the boundary
(Use case 1) as uc1
(Use case 2) as uc2
usecase "Use case 3" as uc3
usecase "Use case 4" as uc4
}
' Connect Alice to the use cases
alice -- uc1
alice -- uc2
alice -- uc3
alice -- uc4
@enduml
Simple Checkout Example
@startuml checkout
left to right direction
' Create two actors
actor Customer
actor Clerk
rectangle Checkout {
' We can make the associations inside the system
Customer -- (Checkout)
(Checkout) .> (Payment) : <<include>>
(Help) .> (Checkout) : <<extend>>
(Checkout) -- Clerk
}
@enduml
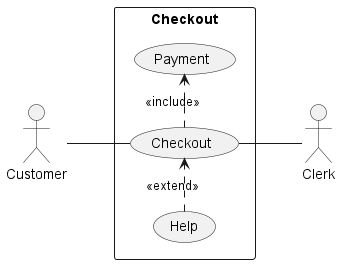
Note that the command
left to right directionwas used in the code above. Try copying the code to your IDE and remove that line. Do you see any difference?The output is displayed in the
top to bottom directionby default which can be difficult to read. Always try to make your diagrams more readable by trying different styles.
Scale Checker Example
Below is a real-world use case diagram showing the use cases for a machine that checks scales inside a hospital. This diagram was created to provide an overview of what kinds of interactions exist between a technician and the machine before developing it further.
@startuml scale-checker
left to right direction
actor Technician
rectangle "Scale Checker" {
usecase "Plug machine in" as plug_in
usecase "Turn machine on" as turn_on
usecase "Self-test" as self_test
usecase "Lock/unlock door" as lock
usecase "Configure procedure" as configure
usecase "Position scale" as position_scale
usecase "Start machine" as start
usecase "Check door closed" as check_door
usecase "Check scale inside" as check_scale
usecase "Safety stop" as stop
usecase "View results" as view
usecase "Download results" as download
}
Technician -- plug_in
Technician -- turn_on
turn_on ..> self_test: <<include>>
self_test ..> lock: <<include>>
Technician -- configure
Technician -- position_scale
Technician -- start
start ..> check_door: <<include>>
check_door ..> lock: <<include>>
start ..> check_scale: <<include>>
Technician -- stop
stop ..> lock: <<include>>
Technician -- view
Technician -- download
@enduml
Exercises
Draw two use case diagrams for the scenarios described below. Note that you should NOT embed all the mentioned details in the texts into your diagrams.
Some of the descriptions are designed as traps: they are too detailed and should not be included in the use case diagram. Thinking about what should be the main focus of the use case diagram and what level of design abstraction it should provide and include.
1. Browser-Based Training System
Create a Use Case Diagram for the following scenario:
A university is developing a web browser-based training system to help students prepare for a certification exam. The student can request the system to generate a quiz. The system achieves this by first selecting a random set of pre-prepared questions from its database and then composing them into a quiz. When the student is taking the quiz, he or she can ask the system to provide some hints if necessary. The system will automatically grade the answers provided by the student while allowing the student to check the correct answers. The questions and hints are provided by the tutors and are certified by the examiners.
2. Online Training Registration
Create a Use Case Diagram for the following scenario:
A university offers online courses for students who have registered on the training website. A registered student can sign-up for a course after paying the tuition fee. The payment is verified and handled by a bank system. After signing up for the course, the student will have the access to the course materials, e.g., lecture videos and slides. The student can register for a certain course using the online registration page. It allows the student to get additional registration help and choose different registration plans.
Component Diagrams
This tutorial covers component diagrams. First, we cover how to use PlantUML to create these diagrams, followed by two small exercises to practice drawing these diagrams.
More information on using PlantUML can be found on the official PlantUML website.
More information on component diagrams in UML can be found in section 11.6 of the UML specification.
Component and Interface
You can create a component by using the keyword component followed by the name of the component,
or by using brackets: [component_name].
To create an interface you can use the keyword interface followed by the name
or by using parenthesis: () interface_name.
@startuml components-and-interfaces
' Create two components
[Component1] as c1
component Component2 as c2
' Create two interfaces
() Interface1 as i1
interface Interface2 as i2
@enduml
Connecting Interfaces
To create associations between components and interfaces
write component_name -- interface_name
and component_name --( interface_name for the provider
and receiver of an interface respectively.
@startuml connecting-interfaces
[Provider] -- Something
[Receiver] --( Something
@enduml
Packages and Databases
You can also group several components into
a group or package by using the package keyword.
You can also group components into a database using
the database keyword.
@startuml packages-and-databases
package "Student Management Subsystem" {
component "Student Profile Finder" as SPF
component "Study Report Generator" as SRG
interface "Student Profile" as SP
SRG -right-( SP
SPF -left- SP
}
database "Student Database" {
component "Bachelor Student Database" as BSD
component "Master Student Database" as MSD
}
' We create two interfaces because
interface "Student ID" as SID1
interface "Student ID" as SID2
MSD -up- SID1
BSD -up- SID2
SPF --( SID1
SPF --( SID2
@enduml
Exercises
1. ATM Transaction
Draw a Component Diagram for an ATM transaction:
A user is interacting with an ATM with his credit card. Specifically, he can interact with the GUI of the ATM which provides the following options:
- Balance Check
- Money Withdraw
- Deposit
The user starts the interaction by inserting the credit card into the card reader of the ATM. After authentication, he can choose one of the three options provided. Note that the ATM is connected to the Bank's database server where the user's account information is stored. When the transaction is complete, the ATM will save the transaction in a separate database, update the user's account information, and print the receipt if required.
(Hint: a dispenser is needed for 'Money Withdraw').
2. Online Shopping Diagram
Draw a Component Diagram for an online shopping scenario:
A customer has an account for her favorite online shop. When shopping online, the customer can add a desirable product to the shopping basket. When the customer is placing an order, the system will leverage an online payment service that is provided by a banking system. To complete the order, the shopping system will collect delivery details from the customer and arrange the delivery of the ordered products.
Class Diagrams
This tutorial covers class diagrams. First we touch on Rust and Object Oriented Programming, then we cover how to use PlantUML to create class diagrams, and finally there is one small exercises to practice drawing these diagrams.
More information on using PlantUML can be found on the official PlantUML website.
More information on class diagrams in UML can be found in section 11.4 of the UML specification.
Rust and OOP
Class diagrams were created in the context of
Object Oriented Programming languages such as C++, Java, or C#.
Since class diagrams map quite closely to code, the diagrams
are a written in a way typical for those languages.
For example, field types are typically written before the field name,
such as String firstName. You can also notice that
camelCase is
often used for field and method names. Methods that do not return
anything are said to return void, which could be thought of as
an equivalent to unit () in Rust. Class diagrams are also used
to show inheritance, which is a language feature that Rust does have.
PlantUML supports "non-traditional" class diagrams which
write fields in a perhaps more familiar notation such as field_name: Type,
and it also has struct and enum keywords for representing
these constructs.
In the example below, we show how some Rust code could be represented with class diagrams, showing both styles.
#![allow(unused)] fn main() { pub struct Student { pub name: String, pub net_id: String, student_number: u32, courses: Vec<Course>, faculty: Faculty } impl Student { fn change_name(&mut self, new_name: String) { todo!() } pub fn completed_ects(&self) -> u32 { todo!() } } struct Course { course_code: u32, ects: u32 } enum Faculty { Architecture, CivilEngineeringAndGeoSciences, ElectricalEngineeringMathematicsAndComputerScience, IndustrialDesignEngineering, AerospaceEngineering, TechnologyPolicyAndManagement, AppliedSciences, MechanicalEngineering } }
We can get this class diagram by translating the code almost exactly:
@startuml rust-to-class-1
struct Student {
+ name: String
+ net_id: String
- student_number: u32
' the fields below are shown in the diagram as their own classes
' - courses: Vec<Course>
' - faculty: Faculty
- change_name(String)
+ completed_ects(): u32
}
struct Course {
- course_code: u32
- ects: u32
}
enum Faculty {
Architecture
CivilEngineeringAndGeoSciences
ElectricalEngineeringMathematicsAndComputerScience
IndustrialDesignEngineering
AerospaceEngineering
TechnologyPolicyAndManagement
AppliedSciences
MechanicalEngineering
}
Student "1" *- "*" Course
Student "*" *-- "1" Faculty
@enduml
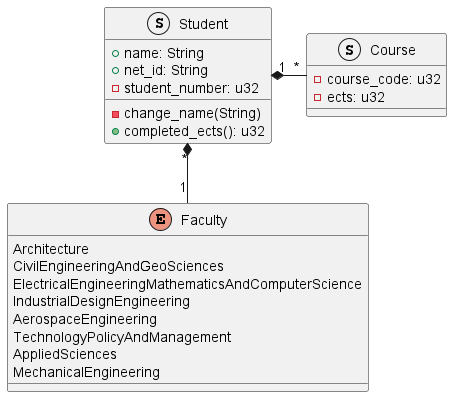
We can also write it using more typical class diagram notation:
@startuml rust-to-class-2
class Student {
+ String name
+ String netId
- Integer studentNumber
- void changeName(String)
+ Integer completedEcts()
}
class Course {
- Integer courseCode
- Integer ects
}
class Faculty <<enumeration>> {
ARCHITECTURE
CIVIL_ENGINEERING_AND_GEOSCIENCES
ELECTRICAL_ENGINEERING_MATHEMATICS_AND_COMPUTER_SCIENCE
INDUSTRIAL_DESIGN_ENGINEERING
AEROSPACE_ENGINEERING
TECHNOLOGY_POLICY_AND_MANAGEMENT
APPLIED_SCIENCES
MECHANICAL_ENGINEERING
}
Student "1" *- "*" Course
Student "*" *-- "1" Faculty
@enduml
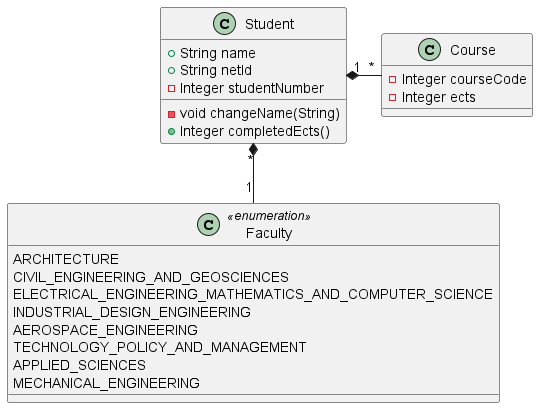
Constructing a Class
To make a class, use the class keyword. Classes have fields and methods.
The two are differentiated based on whether they contain parentheses ().
@startuml constructing-class
class Box {
' fields
Float width
Float height
Float depth
' methods
void open()
void close()
' method with a return type
Integer countItems(ItemKind)
}
@enduml

Visibility
Both fields and methods can have their visibility (public or private)
annotated in the diagram using - for private and + for public.
Other visibility modifiers exist but we will not be using them.
@startuml public-private
class Example {
- SomeType privateField
+ OtherType publicField
- ReturnType privateMethod()
+ void publicMethod()
}
@enduml

Cardinality
To show the cardinality between two classes, use double-quotes " "
on each side of the relation. You can also add a label to the relation
by using a colon afterwards : followed by the label.
@startuml cardinality
left to right direction
User "1" -- "0..*" Account
University "1" -- "1..*" Department
Account "1" -- "1" University : An account can be linked with exactly one University
@enduml
Class Relationships
We covered three different types of relations between classes:
@startuml class-relations
' a dog is a kind of animal
Animal <|-- Dog: Generalization
' the tail is a part of the dog
Dog "1" *-left- "1" Tail: Composition
' the favourite food exists even if the dog does not
Dog "*" o-right- "1" Food: Aggregation
@enduml
Exercises
1. Shopping Centre
Draw a class diagram that models the following scenario:
You are modeling the shopping and managing system for the Westfield Mall of the Netherlands. The mall provides both online and offline services that allow a customer to access their services either at physical locations or at the online website. The shopping mall includes different stores, supermarkets, restaurants, and some places of entertainment. Each one of them is made of several departments and employees. Note that a product and service can be offered by different stores in the shopping mall that allows the customer to compare and select.
Sequence Diagrams
This tutorial covers sequence diagrams. First, we cover how to use PlantUML to create these diagrams, followed by one small exercise to practice drawing these diagrams.
More information on using PlantUML can be found on the official PlantUML website.
More information on sequence diagrams in UML can be found in section 17.8 of the UML specification.
Creating a Participant and Lifetime
You can create a participant and the associated lifetime using the keyword participant
followed by the name of the participant.
You can also use other keywords such as actor and database
to change the shape of the participant.
@startuml participant
participant Participant
actor Actor
database Database
@enduml
Messages
We distinguish different message types by the arrow type.
@startuml messages
' Define participants
participant Source
participant Target
' Simple message which can be either synchronous or asynchronous
Source ->> Target: Simple (sync or async)
Source <<-- Target: Simple return (optional)
' Synchronous
Source -> Target: Synchronous
Source <-- Target: Synchronous return
' Asynchronous (other variants exist)
Source -\ Target: Asynchronous
@enduml
More arrow variants of each message type exist, but try to use these ones for the assignments. Refer to the slides if you are confused.
Activation
Participants are activated for a specific period of time to show they are performing an action. Use the keywords activate and deactivate to display the activation on the diagram.
@startuml activation
participant A
participant B
participant C
A ->> B: do something
activate B
B ->> C: ask for help
activate C
C -->> B
deactivate C
B -->> A
deactivate B
@enduml
Opt - Loop - Alt
The conditional statement expresses an operation that is executed
only if a certain condition is true. You can use the keyword opt
to create a conditional statement.
To create a loop statement where you can repeatably execute a fragment of your system,
you can use the keyword loop.
To create a group of alternative conditions you can use the keyword alt.
When you have reached the end of the block close it with end.
@startuml opt-loop-alt
participant "User" as user
participant "Website" as web
participant "Course Database" as course
participant "My Computer" as pc
opt request help
user ->> web: request_help
activate web
web -->> user: give_tutorial
deactivate web
end
loop for each subject in the course
user ->> web: get_course_description
activate web
web ->> course: get_description
activate course
course -->> web
deactivate course
web -->> user
deactivate web
end
alt print description document
user->Printer: get_print
activate Printer
Printer-->user: print_document
deactivate Printer
else download description document
user -> pc: download_document
activate pc
pc --> user: open_document
deactivate pc
end
@enduml
Exercises
1. ATM Cash Withdraw
Please create a Sequence diagram based on the following description:
After the customer inserts the debit card into the ATM and selects the option of “withdraw cash”, the ATM will ask the customer for the required withdrawal amount. The ATM will access the customer’s bank account and check the current balance. If the required amount is more than the current balance, the ATM will display an “insufficient balance” message to the customer and return to the main menu. Otherwise, the ATM will output the case, update the user’s balance, and print a receipt if the customer required it.
FSM
For this tutorial we will be using the official itemis CREATE documentation.
User Guide
Familiarize yourself with the User Guide.
Read the first two chapters and then move on to the comprehensive tutorial below.
Comprehensive Tutorial
Go through the Comprehensive Tutorial. It covers the basic concepts of itemis CREATE and how to create a finite state machine diagram inside the tool.
After the tutorial you can begin the FSM modeling assignment. If you get stuck, try looking in the User Guide first before asking a TA.
Lecture Examples
In the FSM lecture some example FSM's have been shown to you. It could be useful to simulate these examples in itemis CREATE yourself. That is why we provide you with the project files of the examples used in the slides. You can download the corresponding .zip file here.
The .zip file contains two project folders: HSS_examples/ and Light_examples/. See instructions on how to import the projects below. Once the projects are imported you can the run simulations.
How to Import the itemis CREATE Projects
- Extract the
fsm_slides_examples.zipfile.- When starting itemis CREATE, select the
fsm_slides_examplesdirectory you made as the workspace directory.- Once YAKINDU has launched, Click on
File > Import- Select
General > Existing Projects Into Workspaceand clickNext.- Choose Select
root directory.- Browse to the
fsm_slides_examplesdirectory (the one which has subdirectoriesHSS_examples/andLight_examples/).- Make sure both projects are selected (checkboxes are checked).
- Click on
Finish.- You should now be able to open the
.yscfiles.- If you get a pop-up about whether to Copy or Link the files, choose to link.
DSL
The tutorial for the DSL assignment is in the form of a Jupyter Notebook: 'DSL_Tutorial.ipynb'. To run the example simulation in the tutorial a complementary Jupyter Notebook will be provided: 'StateChartSimulatorApp.ipynb'. If you want to run the simulation, make sure that both notebooks are in the same directory.
To download the notebooks click here.
Assignments
The assignments for the second half of the course will use the same groups as the first part.
There will be three group assignments (UML, FSM, and DSL) and one individual assignment Reflection.
Introduction
The modeling assignments for the Software Systems course are inspired by Philips interventional X-ray systems used for (minimally-invasive) medical procedures. A description of such systems can be found in System Description. If you want more background information, you can optionally look at the paper linked below:
Early Fault Detection in Industry Using Models at Various Abstraction Levels
The grading criteria for each assignment are:
- Your solutions properly use specific model-based techniques.
- Your solutions (including modeling decisions) adequately model the system of interest.
IMPORTANT: System descriptions are often imprecise and incomplete, in this assignment and practice. Please record any questions that pop up during modeling as far as you would like to discuss them with an application domain expert. Please also record the decisions you have made during modeling until you get more clarity from domain experts.
HINTS: We will check the following aspects in your final submission (UML diagrams). Please make sure your diagrams follow these generic points.
Component diagram: (a) Use of assembly notation (connected with interfaces); (b) All interfaces with exactly one component; (c) No use case diagram symbols (generalization) or illegal arrows (solid).
Class Diagram: (a) All associations have a correct name; (b) All associations or aggregation/composition have a cardinality; (c) All attributes have a data type; (d) No circular containment relations; (e) Class attributes do not duplicate relations.
Sequence diagram: (a) Use of and correct activations; (b) No illegal arrows; (c) All synchronous calls with return; (d) Asynchronous call without return.
System Description
During minimally-invasive surgery (cardiac, vascular and neurological), surgeons need technology to be able to see what they are doing. Interventional X-ray systems provide real-time visual images based on X-rays. The patient lies on a table and is positioned between an X-ray tube and an X-ray detector. Based on the detected X-ray, the system reconstructs a visual image and displays this to the surgeon on a screen.
Outside Perspective
In this subsection, we describe the system as a surgeon sees it and uses it.
Hardware components
- Table to support the patient (the patient lies on top of the table);
- Pedal board with 3 or 6 pedals for the surgeon to control the system;
- 1 or 2 X-ray planes, each consisting of one X-ray tube and one X-ray detector that are physically aligned to each other (the two planes are called Frontal and Lateral, respectively);
- Screen to display visual images to the surgeon;
- Tablet for the surgeon to configure the system by selecting a medical procedure.
Interaction
During a medical procedure, the surgeon uses the pedals to select the type of X-ray generated by the whole system in terms of the following notions:
- Dose (= amount of X-ray): low or high
- Projection (= which X-ray plane(s)): Frontal, Lateral, or Biplane (= Frontal + Lateral)
A system with 1 plane has 3 pedals:
- 1 pedal for low-dose X-ray streaming video
- Press = start
- Release = stop
- 1 pedal for high-dose X-ray streaming video
- Press = start
- Release = stop
- 1 pedal for something outside the scope of this assignment
A system with 2 planes has 6 pedals:
- 3 pedals for low-dose X-ray streaming video (one for each projection)
- Press = start
- Release = stop
- 1 pedal to select the high dose projection
- Press = select the next projection in a round-robin fashion
- 1 pedal for high-dose X-ray streaming video (on the selected projection)
- Press = start
- Release = stop
- 1 pedal for something outside the scope of this assignment
While using low-dose streaming video, surgeons need to be able to temporarily switch to high-dose streaming video, without releasing the low-dose streaming video pedal.
Inside Perspective
In this subsection, we describe some of the internal components that this system may be composed of.
Software/electronic components
- PedalMapper: Mapping pedal actions (press/release for a specific pedal) into X-ray requests (e.g., start/stop for a specific type of X-ray).
- ActionLogic: Resolution of (possibly conflicting) X-ray requests, thus transforming X-ray requests (e.g., start/stop for a specific type of X-ray) into X-ray commands (e.g., activate/deactivate for a specific type of X-ray).
- XrayController: Control and synchronization of the X-ray tubes and detectors based on X-ray commands (e.g., activate/deactivate for a specific type of X-ray). The XrayController expects an alternation of activate and deactivate commands. At activation, it first prepares the X-ray tubes and detectors. Then, it synchronizes their execution using timed pulses and receives X-ray images from the X-ray detector until deactivation.
- ImageProcessor: Processing of the X-ray images into highly readable visual images.
- SystemConfigurator: Configuring the settings of the XrayController and ImageProcessor components based on the current system configuration and a selected medical procedure.
- ProcedureDatabase: Database with all possible system configurations and component settings for various medical procedures. Each system configuration consists of a combination of specific system components.
Unified Modeling Language (UML)
Let us first look at the full system. Use PlantUML to make the 6 models described below.
For each PlantUML model, hand in the following items:
- Textual PlantUML script;
- Graphical PlantUML output;
- Textual modeling decisions as a text cell (see the important remark in the Introduction).
Please combine all of the above into one Jupyter Notebook, with sections for each model.
To submit, create a 4-uml directory in your GitLab repository,
and place the Jupyter Notebook file in the 4-uml directory of your GitLab repository.
Each diagram provides a different view of the same system. This means that if you include a component or method in one diagram, the other diagrams should support that.
For example, if you use a method in a sequence diagram, it should also appear in the class diagram with the same name.
Remember that these diagrams should provide an insightful overview of the system. If the diagram is messy or there are many overlapping elements, it fails to do this.
Component diagram
Use PlantUML to create 1 component diagram that shows the hardware and software/electronic components for a system with 1 plane. In addition, introduce associations with required and provided interfaces between the components.
Hint: It may be useful to introduce packages to group some components.
Requirements
- Assembly notation was used (instead of dependency).
- The diagram uses UML correctly.
- Each interface is provided by exactly one component.
- The correct relation types are used.
- The diagram models the system (up to modeling decisions).
Sequence diagram
Use PlantUML to create 3 sequence diagrams for the following workflows in a system with 1 plane:
Configuration
Before a medical procedure:
- Show the supported medical procedures to the surgeon.
- Configure the system for a specific medical procedure that is selected by the surgeon.
Pedal scenario 1
During a medical procedure:
- Pressing the pedal for low-dose video.
- Releasing the pedal for low-dose video.
You must include the X-ray tube, X-ray detector, ImageProcessor, and Screen components in this particular scenario. Include pedal actions and the displaying images on the screen.
Pedal scenario 2
During a medical procedure:
- Pressing the pedal for low-dose video.
- Pressing the pedal for high-dose video.
- Releasing the pedal for high-dose video.
- Releasing the pedal for low-dose video.
You may (and are even advised to) omit the X-ray tube, X-ray detector, ImageProcessor and Screen components in this particular scenario. The diagram should still show that images are displayed on the screen.
Requirements
- The interactions match your component diagram.
- The use of synchronous and asynchronous events is correct.
- The XrayController receives an alternation of activate and deactivate events.
- The XrayController decouples the receiving of activate and deactivate events from the sending of timed pulses.
- The diagrams model the correct scenarios (up to modeling decisions).
Class diagram
Use PlantUML to create the following 2 class diagrams for systems with 1 or 2 planes:
Database Data Model
Diagram for the data model of the procedure database, which describes the required settings of the XrayController and ImageProcessor components for each medical procedure. The settings for these system components contain different attributes. These classes do not have any methods.
High-level
Diagram containing the high-level components, including support for the sequence diagrams you have made before. Include all the components from your component diagram, except for the PedalBoard and Tablet.
Requirements
- Use each relationship type at least once:
- Association is used correctly.
- Aggregation/Composition is used correctly.
- Generalization is used correctly.
- Multiplicities of all relationships are correct.
- The classes should match the components in the component diagram.
- The methods should match the interfaces in the component diagram and the events in the sequence diagrams.
- The diagrams model the system (up to modeling decisions).
Finite-State Machines (FSM)
Let us focus on the ActionLogic components that contain the logic for the X-ray requests and actions. Use itemis CREATE to make an imperative/operational specification of its behavior using finite-state machines.
The external interface of your statechart should be:
interface request:
// the integer selects the projection. 0 = frontal, 1 = lateral and 2 = biplane
in event startLowVideo: integer
in event stopLowVideo: integer
in event startHighVideo: integer
in event stopHighVideo: integer
interface controller:
// the integer selects the projection. 0 = frontal, 1 = lateral and 2 = biplane
out event activateLowVideo: integer
out event activateHighVideo: integer
out event deactivate
The value (the integer) of an event identifies a specific projection.
Event values can be used in itemis CREATE as in the following example that directly forwards the value of an incoming event to an outgoing event:
request.startLowVideo
/ raise controller.activateLowVideo : valueof(request.startLowVideo)
You can assume that the startLowVideo and stopLowVideo requests alternate for each specific projection,
similarly for the startHighVideo and stopHighVideo. You have to take into account that there can be
multiple ongoing requests for low video with different projections, possibly mixed with multiple ongoing
requests for high video with different projections.
Hints
- Make sure your diagram gives an insightful overview of the system.
- You can put multiple
raiseactions on the same transition. - Start by modeling the situation in which, at most, 1 pedal is pressed at the same time before modeling combinations of pedal presses.
- The assignment leaves some degrees of freedom in the logic to be modeled. If your model tends to get very complicated, then please revisit the modeling decisions that you have made.
Submission
You need to hand in two itemis models:
- FSM model for a 1-plane system.
- In this model, the values of the events can be ignored.
- FSM model for a 2-plane system.
- In this model, the value of the events needs to be considered.
- Use the interface that was given above. You do not need explicit toggle selection requests.
For each itemis model, hand in the following items:
- itemis CREATE project (as it is in the repository)
- Screenshot of graphical statechart (included in pdf or markdown document)
- Textual modeling decisions as a pdf or markdown document (see the important remark in the Introduction)
To submit, make sure your models are in the 5-fsm directory in your repository on main. Both models have their own sub-directory.
Instructions for how to import the itemis CREATE projects
can be found in the README.md file in the repository.
Domain-Specific Languages (DSL)
The DSL assignment can be found in this Jupyter Notebook.
There has been an update in the assignment notebook: In the first codebox under Model Validation
property_checker.visit(tree_invalid_program)should beproperty_checker.transform(tree_invalid_program).
Everything below is also covered in the assignment notebook.
Submission
Create a 6-dsl directory, and in this directory an examples/ folder for the examples you should provide.
Your 6-dsl directory should contain the following:
- Your Jupyter Notebook including code for: your grammar, your model validation, and your code generation.
- The One plane, default configuration example program + Rust project folder with generated code.
- The One plane, special configuration example program + Rust project folder with generated code.
- The Two plane, default configuration example program.
- The Two plane, special configuration example program.
Functional examples
You should provide the following examples, written in your DSL. For the one plane examples also provide the generated code.
In total you should provide 2 one plane examples (with generated code) and 2 two plane examples. The examples should encode the following cases:
-
One plane, default configuration
- Pedal mapping:
- low dose
- high dose
- unused
- High dose should override low dose
- Pedal mapping:
-
One plane, special configuration
- Pedal mapping:
- unused
- low dose
- high dose
- Earliest pressed pedal has priority.
- Pedal mapping:
-
Two plane, default configuration
- Pedal mapping:
- low dose, frontal projection
- low dose, lateral projection
- low dose, biplane projection
- high dose on the selected projection
- toggle selected projection (round robin)
- unused
- High dose overrides low dose
- Selection pedal should toggle between frontal, lateral and biplane projection in that order
- Selection pedal only toggles when no pedal is pressed
- Pedal mapping:
-
Two plane, special configuration
- Pedal mapping:
- unused
- high dose, frontal projection
- high dose, lateral projection
- low dose on the selected projection
- toggle selected projection (round robin)
- high dose, biplane projection
- Low dose overrides everything except high dose biplane
- Selection pedal should toggle between frontal, biplane and lateral projection in that order
- Selection pedal should only toggle when low dose pedal is pressed
- Pedal mapping:
If your DSL cannot model some of the examples then provide an alternative example of your DSL with an explanation of how you change the static configuration and the dynamic logic. In total you should still have 2 one plane examples (with generated code), and 2 two plane examples.
Example Use of Simulator
Consult the documentation of the package for additional help.
In Cargo.toml:
[package]
name = "example"
version = "0.1.0"
edition = "2021"
[dependencies]
# this is the simulation library
tudelft-xray-sim = "1.0.1"
# logging libraries
simple_logger = "4.0.0"
log = "0.4"
In src/main.rs:
// Import types from the simulation library. use tudelft_xray_sim::*; // Import enum variants to make this example a bit easier to read. use Dose::*; use Mode::*; use Projection::*; use log::info; fn main() { // Initialize logger. simple_logger::init().unwrap(); // Run simulation with your own implementation of the control logic. run_double_plane_sim(Logic::default()); } /// Example control logic for a two plane system. /// The pedal mapping is based on the example mapping given in the DSL assignment. #[derive(Default)] struct Logic { /// keep track of the selected projection selected: Projection, // you can have whatever other information that you want here } impl PedalMapper for Logic { /// We use an associated type to determine which pedal enum is used. /// Single-plane systems use the `ThreePedals` enum, while /// two-plane systems use `SixPedals`. /// Whether you used the correct type is checked at compile time. type Pedals = SixPedals; fn on_press(&self, pedal: Self::Pedals) -> Option<Request> { use SixPedals::*; Some(match pedal { // 3 pedals for low dose X-ray streaming video (one for each projection) Pedal1 => Request::start(Frontal, Low, Video), Pedal2 => Request::start(Lateral, Low, Video), Pedal3 => Request::start(Biplane, Low, Video), // 1 pedal to select the high dose projection in a round-robin fashion Pedal4 => Request::toggle_selected_projection(), // 1 pedal for high dose X-ray streaming video Pedal5 => Request::start_selected_projection(High, Video), // 1 pedal for high dose X-ray single image Pedal6 => Request::start_selected_projection(High, Image), }) } fn on_release(&self, pedal: Self::Pedals) -> Option<Request> { use SixPedals::*; Some(match pedal { Pedal1 => Request::stop(Frontal, Low, Video), Pedal2 => Request::stop(Lateral, Low, Video), Pedal3 => Request::stop(Biplane, Low, Video), Pedal4 => return None, // nothing happens when we release pedal 3 Pedal5 => Request::stop_selected_projection(High, Video), Pedal6 => Request::stop_selected_projection(High, Image), }) } } impl ActionLogic<true> for Logic { /// Naive implementation of request handling which does not handle /// multiple pedals being pressed at once. fn handle_request(&mut self, request: Request, controller: &mut Controller<true>) { // This is how you can get access to the planes in case you want to inspect their status. let _frontal = controller.frontal(); let _lateral = controller.lateral(); // Custom logging of requests. info!("Processing request: {request:?}"); // In your own code (as well as the code that you generate), // you should do checks before using the controller to // start and stop X-rays. match request { Request::Start { projection, dose, mode, } => { controller.activate_xray(projection, dose, mode); } Request::Stop { .. } => controller.deactivate_xray(), Request::ToggleSelectedProjection => { self.selected = match self.selected { Frontal => Lateral, Lateral => Biplane, Biplane => Frontal, }; info!("Selected: {:?}", self.selected); } Request::StartSelectedProjection { dose, mode } => { controller.activate_xray(self.selected, dose, mode) } Request::StopSelectedProjection { .. } => controller.deactivate_xray(), } } }
Reflection
Task
Formulate your informed view on Model-Based Development for Software Systems.
Motivate this view based on your experiences in this course.
- (Optional) You may relate it to other (properly-referenced) experience/information sources
- (Optional) You may relate it to your prior software development experiences
Grading Criteria
- Show understanding of model-based development for software systems.
- Provide an overarching view with supporting arguments (including your experiences in this course).
- Reference all used sources (facts, experiences, etc.) in an appropriate way.
Note
- Individual assignment
- Submitted as PDF
- Length: 1 page A4 (~ 500 words)
Submission
This is an individual assignment. You will have to upload your document on BrightSpace. There is an assignment on BrightSpace with the name "Reflection" where you should upload your pdf.