Lecture 3
Contents
No OS, no standard library
This explanation is a summary of the lecture. For more general knowledge about rust embedded development, I highly recommend the rust embedded book
Until now, in both Software Fundamentals and previous weeks in Software Systems, all the code you have made is designed to work on top of an operating systems. Either Linux, Windows, or sometimes even MacOS. A program that runs on top of an operating system generally has to care less about unimportant things. The operating system will take care of that. Scheduling threads? Interacting with peripherals? Allocating memory? The operating system generally handles it.
But sometimes, having an operating system is not feasible, required or desired. Some hardware is simply not supported by major operating systems. Or a specific peripheral has no driver for the operating system you want to use. Booting an operating system usually also takes a while, and some performance may be lost since the operating system has to perform tasks in the background. Or perhaps, you simply want to write an operating system itself.
When a program runs without an OS, some services aren't available by default. For example:
- A filesystem
- Threads and subprocesses
- An allocator
- support for interaction with peripherals
- graphics
- a standard output to print to, or standard input to get input from
- startup code initializing the program
But, where previously the operating system may have prevented you from creating these yourself, without an operating system around, the program is free to manage all the hardware by itself.
However, there is a problem. Rust has a pretty large standard library. Many of the services provided by the standard
library rely on the operating system. For example, std::thread only
works when it can spawn threads through the operating system, std::vec needs
an allocator and std::fs is literally made to manipulate a filesystem.
This means that a rust program that runs without an operating system, does not have access to the standard library. We often call
those programs "no-std", and they are marked in their main.rs file with the following annotation at the top of the file:
#![allow(unused)] #![no_std] fn main() { // the program }
Although the standard library is not available for no-std programs, they can just have dependecies like normal. You can
still specify those in the Cargo.toml file. However, all dependencies of a no-std program must also be marked as no-std.
For some libraries this is an optional feature, for some it's the default. A list is available here
core and alloc
Not all services in the standard library depend on an operating system. For example, many built-in types such as Option and Result,
and many traits such as Eq, Ord and Clone should be perfectly usable when there's no operating system. And indeed, you can. Sofar,
we've used the rust standard library and the word std pretty interchangeably. But actually, they are not the same. The standard library
comes in tiers.
coreis the set of all standard library items that don't rely on an operating system in any way.allocis the set of all standard library items that rely only on an allocator.Vecs are part of this.stdis the set of standard library items that require an operating system to work.stdis a superset ofallocandcore. 4coreis always available, even when you specified your program to be no-std.allocis conditionally available. It can only work if there is an allocator. Thus, if your program supplies one, you can importalloc. That works as follows:
#![allow(unused)] #![no_std] fn main() { // required, since this is technically not entirely stable yet. #![feature(alloc_error_handler)] // enable the alloc crate. Only works if an allocator is provided. extern crate alloc; // import some allocator use some_allocator::SomeAllocator; // this tag marks a special global variable. The type of it must implement // the `Allocator` trait. If this is not supplied, alloc cannot work and your // program won't compile. #[global_allocator] static ALLOCATOR: SomeAllocator = SomeAllocator::new(); // This function is called when an allocation fails. // For example, memory may have ran out. #[alloc_error_handler] fn alloc_error(layout: Layout) -> ! { panic!("Alloc error! {layout:?}"); } // A program using Vecs and other features from alloc can now follow }
There are a number of allocators available for no-std programs. A list of them can be found here.
You may have noticed the return type of alloc_error is
!. This means that the function will never return. Because it doesn't return, a real return type is also not necessary. You can create a program that never returns by using an infinite loop:#![allow(unused)] fn main() { fn never_returns() -> ! { loop {} } }
Panicking
When a Rust program panics, it generally performs a process called unwinding. That means that it will walk the stack backwards, and then crashes, printing a trace of the stackframes such that you can debug where it went wrong. But, what should happen when a program running on bare-metal1 crashes? There is no such thing as exiting the process and printing a message. Exiting just means giving control back to a parent process, but the program is the only thing running on the system.
When a program runs without an operating system, it has to assume its the only thing running, and that its running forever. On an embedded device, this means that the program is the first and only thing that runs once the device is turned on, and that it will run until the device is turned off. That means that if a program panics, the only real thing that it can do is either
- reboot/restart from the start of the program
- wait in an infinite loop
So, what happened when the panic function is executed in no-std rust?
For a no-std program to be valid (and compile), it has to define a panic handler:
#![allow(unused)] #![no_std] fn main() { // maybe put the code that initializes `alloc` here // when a panic occurs, this function is called #[panic_handler] fn panic(info: &PanicInfo) -> ! { // just go into an infinite loop if it does loop {} } }
Starting up
In normal rust, a program defines a main function, which is the first code to be executed. This works, because
the operating system will call it2 when the program is executed. But, we cannot assume there is an operating system
in no-std Rust!
Starting up depends on the environment. A no-std program can do one of several things. When a no-std program actually runs under
an operating system (maybe one that's not supported by rust by default), it can define a function with the appropriate name.
For example, a no-std program on linux could define the __start function.
However, if the program is supposed to be executed when a computer boots up (maybe you're making an operating system or a
program for a microcontroller), then the processor generally defines how it will start running user defined code. For those
of you who followed Software Fundamentals, you will know that on the NES
there was a reset vector. A location in memory containing the initial program counter. Other processors will have similar,
yet slightly different conventions.
However, often when we work with a well-supported processor architecture, or microcontrollers with good support, we can use hardware abstraction layers to greatly simplify this.
By default, all names in rust are "mangled". That means, in the final compiled program, they have slightly different names. In a Rust program, there can be multiple functions with the same name defined in different modules for example. In the compiled program, the functions will have different "mangled" names to disambiguate.
When a function needs to have a precise name such as
__starton linux, then you will have to add the#[no_mangle]attribute to it to make sure it will actually get that name in the compiled program:#![allow(unused)] fn main() { #[no_mangle] fn __start() { } }
Hardware abstraction
From now on, we will assume we are making a program that has to run on a bare-metal microcontroller. For this course, you will use an nrf51822 processor in the assignments.
Many bare-metal programs have similar needs. They need to boot up, initialize some data, set up some interrupt handlers and interact with some peripherals. These steps often work almost the same for systems with similar architectures. Also, it is not uncommon for systems to use the same standards for communicating with peripherals. Pretty common standards include I2C, CAN, SPI, PCI(E), etc.
Because no-std programs can just import libraries, naturally people have made libraries to solve some of these problems. Actually, each of the previously mentioned standards link to a rust library that makes it easier to use these standards. For example, they provide an interface to generically interact with components connected over for example i2c.
Many processors, or processor families also come with libraries that make it easy to use the interfaces that that processor provides. For example, for the assignments in this course we use an nrf51822 microcontroller. There are libraries which specifically for the NRF51 family of processors, allows you to set up interrupts, or access memory mapped IO safely. The library already hardcodes the memory locations of the different memory mapped devices.
Memory mapped IO
Many microcontrollers allow access to peripherals through memory-mapped IO. That means that specific addresses in memory are set up not as a memory location, but as a port to a peripheral. When the processor writes or reads to that location, it actually communicates with the peripheral device. Memory mapped IO is sometimes abbreviated as MMIO.
The locations in memory of MMIO can differ per processor or processor family. Generally, you have to look at the datasheet of the specific device to find the addresses. However, often a PAC library exists that remembers the addresses for you.
PACs
PAC is short for peripheral access crate. They provide an interface to easily access peripherals of a specific device. There are different PACs for different devices. You can find a list here. They will for example contain all the addresses of MMIO peripherals, and provide functions to write and read from and to those locations.
For example, nrf51-pac defines a module called uart0. In it, there is a struct with all the fields from the NRF uart API.
You will see that these fields match up with the register overview of the UART in the manual for the NRF51 series on page 154.
Often, PACs are automatically generated from a hardware's description. We will talk about this more next week. But it does mean a PAC is not always very easy to use. It requires knowledge of some conventions. The nice thing is, since it's all automatically generated, the conventions will be the same across all PACs for different hardware. However, this will take some time to get used to
Structs for Memory Mapped IO
If you think about it, a struct is simply a specification for the layout of some memory. A struct like
#![allow(unused)] fn main() { struct Example { a: u32, b: u8, c: u8, } }
Defines a region of memory of 48 bits (or 6 bytes)3, with specific names for the first 4 bytes, the 5th and the 6th byte.
Quite often, the manual of a microprocessor will list the locations and layout of memory mapped IO. For example, the reference manual of the NRF51 series processors, will list this for the I2C interface:
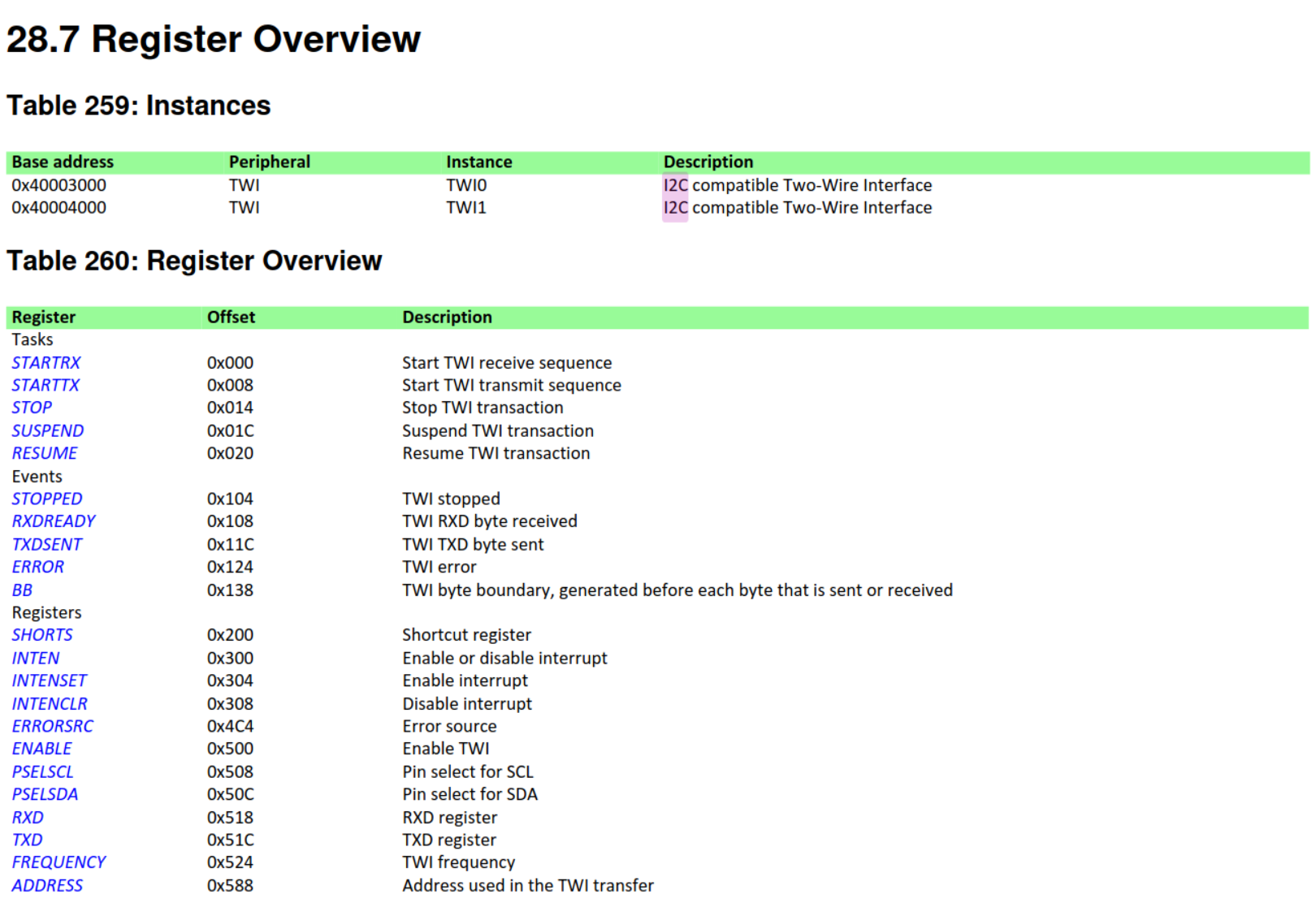 This says that, there are two (separate) I2C interfaces on the chip (the instances). One at address
This says that, there are two (separate) I2C interfaces on the chip (the instances). One at address 0x40003000 and
another one at address 0x40004000. Each of the instances has a number of control registers listed below. Each has an offset
from its base address (so that's the 0x40003000 or 0x40004000).
You may notice that this is actually quite similar to the definition of a struct. This is exactly what a PAC will be, a definition for structs that are equivalent to the layout of such MMIO regions. Let's look at the rust PAC for the nrf51, and its definition for the I2C interface:
#![allow(unused)] fn main() { #[repr(C)] pub struct RegisterBlock { pub tasks_startrx: TASKS_STARTRX, pub tasks_starttx: TASKS_STARTTX, pub tasks_stop: TASKS_STOP, pub tasks_suspend: TASKS_SUSPEND, pub tasks_resume: TASKS_RESUME, pub events_stopped: EVENTS_STOPPED, pub events_rxdready: EVENTS_RXDREADY, pub events_txdsent: EVENTS_TXDSENT, pub events_error: EVENTS_ERROR, pub events_bb: EVENTS_BB, pub events_suspended: EVENTS_SUSPENDED, pub shorts: SHORTS, pub intenset: INTENSET, pub intenclr: INTENCLR, pub errorsrc: ERRORSRC, pub enable: ENABLE, pub pselscl: PSELSCL, pub pselsda: PSELSDA, pub rxd: RXD, pub txd: TXD, pub frequency: FREQUENCY, pub address: ADDRESS, pub power: POWER, /* private fields */ } }
(source: https://docs.rs/nrf51-pac/latest/nrf51_pac/twi0/struct.RegisterBlock.html)
As you can see, the fields in this struct exactly match the manual of the NRF51. Note that some /* private fields */ are missing,
those are extra fields inserted for the alignment of the other registers, so they are located exactly at the right positions as the manual says.
The types of the field are also interesting. They are almost all different, and that's because each field may have different requirements for the values that can be stored in them (maybe the frequency field cannot have certain values). The values of these specific types make sure that you cannot write (without unsafe code) write wrong values to the fields.
Navigating the documentation for these types may be a bit difficult. You will have to do this in the third assignment. The documentation for PACs isn't great, that's because it's automatically generated code. The assumption is that you also have the manual for the chip the PAC was generated for, it has more information about the hardware. The PAC is just so you cannot make any mistakes by writing to the wrong register for example. Keep this in mind!
It often does not make sense for users of PACs to actually create instances of these MMIO structs themselves. That's because there physically only are a limited number of instances of that MMIO region (maybe only 1). And the actual locations of these structs are also limited. They can really only exist at the base addresses of these MMIO regions. Therefore, as a user of a PAC, you won't be constructing these structs yourself.
Instead, you'll ask the library to do it for you. It will give you a reference to all the instances of the MMIO structs. The references will
all point to the correct regions in memory. You do this with the Peripherals struct (this struct is present in any PAC crate). You can do this as follows:
use nrf51::Peripherals; fn main() { let peripherals = Peripherals::take().unwrap(); // instance of the SPI RegisterBlock struct, you can // write to fields of this to interact with the SPI device. let spi = &peripherals.SPI0; }
Let's say we want to write code that sets the frequency of the I2C signal. On the Spi struct, there's a field called frequency,
and you can see above that its type is FREQUENCY. Let's write to it:
use nrf51::Peripherals; fn main() { let peripherals = Peripherals::take().unwrap(); let spi = &peripherals.SPI0; // this is unsafe, most values are invalid for this register. // 0x0001 would likely crash the chip. spi.frequency.write(|w| unsafe {w.bits(0x0001)} ); // this is always safe however spi.frequency.write(|w| w.frequency().k125()); }
So what's happening on this last line? first, we're choosing the field spi.frequency, and call the write() function on it.
Instead of simply writing a value, write() takes a "closure" (a sort of lambda function).
This may feel cumbersome, but remember that a PAC is really low level. Structuring it this way actually allows the rust to generate code
that will be extremely close to hand-written assembly.
The closure gets a parameter w, and we can call methods For example, the bits() method. This allows us to put a specific
binary value in the frequency register. But, bits is unsafe to use. That's because not all values in the register are valid
frequencies for the chip. Maybe the chip crashes when you write certain values. However, since, through the PAC, rust knows that
this field is of type FREQUENCY, there is also a method frequency() which only allows us to put valid values into the register.
When using the unsafe
bits()function, always check the documentation what values are valid
For example, the k125() sets the chip to 125kbps. Other values like m1 (for 1 mbps) are possible too. But
Through PACs, all registers which have "semantics", i.e. they represent a frequency, a number, a power state, or a configuration value can only be (safely) written with values which fit these semantics. This prevents you from ever accidentally order the chip to do something unspecified.
HALs
HAL is short for hardware abstraction layer. A HAL is a higher level abstraction, usually built on top of a PAC. Let's again take
the NRF51 as an example. There is a crate called nrf51-hal. For example, some NRF51 processors will
have hardware accelerated cryptographic functions. While through a PAC, you'd interact with the registers directly, the HAL will provide an
encrypt() and decrypt() function that does everything for you.
Architecture specific
It sometimes doesn't make sense to put support for a specific device in either a PAC or a HAL. That's because some devices or hardware features are not shared per manufacturer, or series, but for the entire architecture. For example, the way you set up interrupts, set up memory protection, or even boot the entire chip. For some architectures, there are crates which provide support for systems with that architecture. For example,
cortex_mprovides support for all ARM cortex M processorscortex_m_rt(rt means runtime) provides code to boot cortex_m processors (so you don't need to touch assembly ever again)alloc_cortex_mprovides an allocator on ARM cortex M systems, so you can useBox,Vecand other standard collections in your code.
corex_aLikecortex_m, but for cortex A processorsriscvprovides similar operations ascortex_m, but for riscv processorsriscv-rtprovides similar operations ascortex_m_rt, but for riscv processors
x86provides similar operations ascortex_m, but for x86 processorsavr_halprovides low-level support for arduinos and related AVR-based processors. Unfortunately the support is worse than the other entries on this list.
All in all, this list allows you to run rust code on a large selection of microcontrollers available on the market without much hassle. Most of these provide templates to get started quickly. If you're interested, you might take a look through the rust embedded github organisation. They have loads of other projects that make writing rust for microcontrollers easy.
Safety abstractions and unsafe code
To switch to unsafe Rust, use the unsafe keyword and then start a new block that holds the unsafe code. You can take five actions in unsafe Rust that you can’t in safe Rust, which we call unsafe superpowers. Those superpowers include the ability to:
- Dereference a raw pointer
- Call an unsafe function or method
- Access or modify a mutable static variable
- Implement an unsafe trait
- Access fields of unions
It’s important to understand that unsafe doesn’t turn off the borrow checker or disable any other of Rust’s safety checks: if you use a reference in unsafe code, it will still be checked. The unsafe keyword only gives you access to these five features that are then not checked by the compiler for memory safety. You’ll still get some degree of safety inside of an unsafe block.
In addition, unsafe does not mean the code inside the block is necessarily dangerous or that it will definitely have memory safety problems: the intent is that as the programmer, you’ll ensure the code inside an unsafe block will access memory in a valid way.
People are fallible, and mistakes will happen, but by requiring these five unsafe operations to be inside blocks annotated with unsafe you’ll know that any errors related to memory safety must be within an unsafe block. Keep unsafe blocks small; you’ll be thankful later when you investigate memory bugs.
To isolate unsafe code as much as possible, it’s best to enclose unsafe code within a safe abstraction and provide a safe API, which we’ll discuss later in the chapter when we examine unsafe functions and methods. Parts of the standard library are implemented as safe abstractions over unsafe code that has been audited. Wrapping unsafe code in a safe abstraction prevents uses of unsafe from leaking out into all the places that you or your users might want to use the functionality implemented with unsafe code, because using a safe abstraction is safe.
One important note here is that using unsafe code is not always bad. We say that not all unsafe code is unsound. However, the compiler simply cannot and will not check this, making you, the programmer responsible. Any time you use an unsafe code block, you should properly document why yes this code has to be unsafe but also yes the code is sound nonetheless. Sometimes this soundness relies on some preconditions being checked.
The text also mentions the word "Safe abstraction". So what's that? A good example is a Mutex.
In general, it is unsafe to modify a variable from multiple threads. However, accessing and modifying
values inside mutexes from multiple threads is fine. That's because when accessing a value in a
Mutex, you are forced to lock that Mutex first. And this locking makes sure that nothing else is allowed
to access the variable until unlocked.
The important takeaway is, that Mutex actually uses unsafe code under the hood. It allows you to reference
a mutable variable from multiple threads. And yet, using a Mutex is totally safe. Because of the interface Mutex
exposes, it is actually impossible to violate any safety guarantees. Thus, a Mutex makes sure that however it is used,
all the internal unsafe code is always sound.
We call things like a Mutex a safety abstraction. Some things in Rust are only safe when specific conditions are met.
In the case of the mutex, this condition is aliasing a mutable reference (from multiple threads!). The compiler cannot
check those conditions. But instead of manually checking the conditions before you do something unsafe, you make an abstraction.
Some way that makes the unsafe thing unconditionally safe. A Mutex does this by only giving access to the internals when locking.
UnsafeCell
Mutexis not the only abstraction for aliasing mutable references. There is also theCell<T>,RefCell<T>andRwLock<T>. The first two are like locks, but can only be used in single threaded scenarios and are therefore much more efficient. The last is simply a more efficient lock when reading is more common than writing to the internals.At the root of all these types lies the
UnsafeCell. TheUnsafeCellhas some built-in compiler support and is therefore a bit magical. It is actually the only safe way to modify a value without needing a mutable reference. However, usingUnsafeCellis always unsafe as the name implies. When using it, you are responsible to make sure that the inner value is not actually ever accessible to two threads at the same time. You will see that the sourcecode of aMutexuses theUnsafeCelltoo, and only accesses it after theMutexis locked.#![allow(unused)] fn main() { pub struct Mutex<T: ?Sized> { inner: sys::MovableMutex, // <-- C-style mutex poison: poison::Flag, data: UnsafeCell<T>, // <-- UnsafeCell used here } }
Actually, indexing an array could also be seen as such a safe abstraction. Internally, indexing an array just offsets a pointer, but this
is only safe if the offset-location is in-bounds. The unsafe version of this operation is called get_unchecked
which does not do any safety checking and is therefore marked "unsafe". However, the indexing operation on arrays is safe because it checks whether the index
is in bounds, and crashes if it is not. A crash is not very nice of course, but at least it is safer than a buffer overflow leading to some kind of security vulnerability.
If you'd like reading more about this, I personally thought David Tolnay's and Alex Ozdemir's posts were very good.
In assignment 3 you are tasked to implement safe abstractions for mutation (there called OwnMutex). You should use UnsafeCell as a basis here.
Resources
-
When we refer to bare-metal code, we mean code that runs without any operating system around it. For example, the program runs alone on a microcontroller. It is the first and only thing started at boot, and is solely responsible to manage all the hardware on that system. ↩
-
Technically, that depends on the operating system. Linux will jump to the
__startlabel by default.stdRust makes sure that main is called at some point after__startis executed. ↩ -
Due to struct packing rules, the exact layout of the struct may not be 6 bytes since that may be less efficient in certain situations. You can add the attribute
#[repr(packed)]to a struct to force the layout to be exactly what was specified, and#[repr(C)]to force a struct to have the same layout as a C compiler would give it. ↩